AMD 配置
作为 JVD 一部分涵盖的 AI 服务器包括 2 台 Supermicro AS-8125GS-TNMR2 双 AMD EPYC 8U GPU 和 2 台 Dell PowerEdge XE9680。
本节提供一些基于 AI JVD 实验室测试的接口和其他相关参数的安装和配置指南。进行更改时,请务必参考制造商的官方文档并了解更多详细信息。
AMD MI300X 设置 BIOS 参数
根据其 UI 和 GPU 映射以及服务器内部架构的差异,每个供应商都有不同的 BIOS 设置。
SuperMicro AS-8125GS-TNMR2
将服务器启动到设置模式(启动到 supermicro splash 将需要几分钟时间才能显示):
| UEFI/BIOS 区域 | 值 |
|---|---|
| 高级 -> NB 配置 | ACS 启用 = 禁用 |
| 高级 -> NB 配置 -> xGMI | xGMI 链路宽度控制 = 手动 |
| xGMI 力链路宽度控制 = 力 | |
| xGMI 力链路宽度 = 2 | |
| xGMI 最大链路宽度控制 = 手动 | |
| xGMI 链路最大速度 = 自动 | |
| 高级> PCIe/PCI/PnP 配置 | 4G 以上编码:启用 |
| 调整大小 BAR 支持:已启用 | |
| SR-IOV 支持:已启用 | |
| 工作负载 = 未配置 |
戴尔 XE9680
戴尔建议为其 XE9680 AI/ML 服务器使用以下 BIOS 设置。BIOS 设置也会禁用主机上的 IOMMU 和 ACS。
| UEFI/BIOS 区域 | 值 |
|---|---|
| BIOS -> 处理器设置 | 逻辑处理器 = 禁用 |
| 虚拟化技术 = 禁用 | |
| SubNumaCluster = 禁用 | |
| MADt 核心群集 = 线性 | |
| 1 BIOS >集成设备 | 全局 SRIOV = 禁用 1 |
| BIOS -> 系统配置文件设置 | 服务器系统配置文件 = 性能 |
| 工作负载 = 未配置 | |
| BIOS ->系统安全性 | 交流恢复延迟 = 随机(强烈推荐) |
1 戴尔建议“启用”全局 SR-IOV,但在此实验室设置中的戴尔 DUT 上,此设置与存储和前端交换矩阵的 Thor2 NIC 端口模式 0 不兼容(2x200Gb 与 1x400Gb),导致 DUT 在启动时出现故障。请咨询您的戴尔客户团队,以获取有关设置中此设置的建议。
请按照 AMD Instinct 加速器的单节点网络配置 — GPU 群集网络文档中所述的配置步骤进行作。请注意,在重新启动服务器后,还必须在步骤 6 中使用的 禁用 ACS 脚本 在任何工作负载之前运行。
适用于 AI 数据中心的以太网网络适配器 (NIC)
AI/ML 工作负载的复杂性和规模都有所增加;网络对于缩短工作完成时间至关重要。网络适配器 (NIC) 是将 GPU 连接到数据中心交换矩阵的连接点,因此这些 NIC 应该能够处理大量数据,并且应该能够支持 GPU 服务器之间的高速、低延迟通信。因此,NIC 至少应该能够支持某些关键的 AI/ML 功能,如下所示:
- 聚合以太网 RDMA (RoCE) 和拥塞控制。
- 能够以低延迟的方式处理 400G 双向数据。
- 先进的拥塞控制机制,灵敏地应对网络拥塞并优化流量。
- 支持 GPU 可扩展性,即使 GPU 不断增加,也能确保稳健的性能。
对于服务器 NIC,我们有两个选项:
- Broadcom Thor2 — Broadcom Thor2 网络适配器已通过 AI/机器学习工作负载和作业完成时间验证。
- AMD Pollara - AMD Pollara 400 以太网网络适配器
有关 AMD Pensando Pollara 400(以太网适配器)的更多信息,请参阅此 链接。
识别 NIC 和 GPU 映射
除了交换矩阵和 GPU 服务器设置外,此 JVD 还涵盖了以太网网络适配器(或 NIC)的配置和设置,如下所示。Broadcom BCM957608 (Thor2) 以太网网络适配器在第 1 阶段通过了验证。在第 2 阶段,AMD Pollara 400 NIC 卡将经过验证。
所有 4 台服务器都配备了:
- 8 个 AMD Instinct MI300X OAM GPU
以及以下任一 NIC
- 8 个 单端口 400/200/100/50/25/10GbE Broadcom BCM957608 (Thor2) 适配器 ,带有 400Gbps QDD-400G-DR4 收发器,用于连接到 GPU 后端交换矩阵。
或者
- 8 个 单端口 400G 和 2 个端口 200G 和 4 个端口 100/50/25G AMD Pensando Pollara 400 以太网网络适配器 ,带有 Q112-400G-DR4 收发器,用于连接到 GPU 后端交换矩阵。
戴尔设备:
- 1 个 Mellanox MT2910 系列 NVIDIA® ConnectX-7® SmartNIC, 带 100Gbps QSFP28 收发器,可连接到前端交换矩阵
- 2 个 Mellanox MT2910 系列 NVIDIA® ConnectX-7® SmartNIC, 带 200Gbps QDD-2X200G-AOC-5M 收发器,可连接到前端交换矩阵
AMD MI300x GPU 服务器和 NIC 固件和 RCCL 库
出于 Broadcom Thor 2 NIC 验证的目的,以下是 MI300x GPU 服务器上配置的主要作系统和固件版本:
Broadcom Thor 2 以太网适配器
以下是安装的作系统 (OS)、固件和 AMD 库的详细信息:
| 作系统/固件 | 版本 |
|---|---|
| Ubuntu 的 | Ubuntu 24.04.2 LTS |
| Broadcom Thor2 NIC 固件版本 | 231.2.63.0 |
以下是为 Thor2 网络适配器的 RCCL 测试安装的库:
| RCCL 测试库 | 版本 | 命令 |
|---|---|---|
| ROCM/贵族 | 6.4.0.60400-47~24.04 AMD64 | APT 列表 ROCM |
| RCCL 1 | 2.22.3.60400-47~24.04 AMD64 | apt 列表 rccl |
| MPI(开放式 MPI) | 5.0.8a1 | mpirun –版本 |
| UCX |
1.15.0 | /opt/ucx/bin/ucx_info -v |
AMD Pensando Pollara 400 以太网适配器
出于 AMD Pollara 400 NIC 验证的目的,以下是 MI300x GPU 服务器上配置的主要作系统和固件版本:
| 作系统/固件 | 版本 |
|---|---|
| Ubuntu 的 | Ubuntu 22.04.5 LTS |
| AMD Pollara NIC 固件版本 | 1.110.0-A-79 |
安装在 MI22.04 服务器上的 ubuntu 版本 300 的输出。
-
jnpr@mi300-01:~$ cat /etc/os-release PRETTY_NAME="Ubuntu 22.04.5 LTS" NAME="Ubuntu" VERSION_ID="22.04" VERSION="22.04.5 LTS (Jammy Jellyfish)" VERSION_CODENAME=jammy ID=ubuntu ID_LIKE=debian HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
AMD Pollara 400 NIC 卡的输出固件版本
-
jnpr@mi300-01:~$ sudo nicctl show card --detail | grep Firmware Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79
以下是为 AMD Pollara 400 NIC 适配器的 RCCL 测试安装的库:
| RCCL 测试库 | 版本 | 命令 |
|---|---|---|
| ROCM/Jammy | 6.3.3.60303-74~22.04 AMD64 | APT 列表 ROCM |
| RCCL 1 | 7961624 | |
| MPI(开放式 MPI) | 5.1.0a1 | /opt/ompi/bin/mpirun –version |
| UCX |
1.20.0 | /opt/ucx/bin/ucx_info -v |
| RCCL 测试 | 修订版 6704FC6 | Git 分支 https://github.com/ROCm/rccl-tests.git |
| ANP 插件2 |
有关安装这些软件和依赖库的更多信息,稍后在 AMD Pollara 固件和依赖库一节中提供了高级步骤,因为只有在映射 NIC 和 GPU 后才能执行这些步骤,如以下部分所述。
在本节中,我们将探讨一些选项来查找和配置有关 NIC 和 GPU 的信息。
ROCm 通信集体图书馆 (RCCL)
在 AMD 服务器中, ROCm 提供了针对 AMD GPU 优化的多 GPU 和多节点集体通信原语。这些集合跨一个或多个 GPU 服务器中的多个 GPU 实现发送和接收作,例如 all-reduce、all-gather、reduce、广播、all-to-all 等。
单个服务器上 GPU 之间的通信是使用 xGMI(芯片间全局内存互连)实现的,这是 AMD Infinity 交换矩阵技术的一部分。Infinity 交换矩阵是一种高带宽、低延迟的互连,用于系统内的各个组件,包括 CPU、GPU、内存、NIC 和其他设备。xGMI 提供插槽到插槽的通信,允许直接的 CPU 到 CPU 或 GPU 到 GPU 的通信。
不同服务器之间的通信由支持 RDMA 的 NIC(例如,通过以太网的 RoCEv2)处理,并穿过 GPU 后端交换矩阵进行路由。这些 NIC 可随时由任何 GPU 使用,因为没有硬编码的 1 对 1 GPU 到 NIC 映射。但是,在 GPU 和 NIC 之间使用首选通信路径会产生 1:1 对应的外观。
RCCL 将始终选择 GPU 之间以及 GPU 和 NIC 之间连接最佳的路径,旨在优化带宽和延迟。在节点间转发之前,将采用优化的节点内路径。
rocm-smi (Radeon 开放计算平台系统管理接口)cli 提供了用于配置和监控 AMD GPU 的工具。它可用于通过以下选项识别 GPU、硬件详细信息以及拓扑信息:
--showproductname: 显示产品详情
--showtopo : 显示硬件拓扑信息
--showtopoaccess :显示了 GPU 之间的链路可访问性
--showtopohops :显示 GPU 之间的跃点数
--showtopotype :显示 GPU 之间的链路类型
--showtoponuma :显示 NUMA 节点
--shownodesbw:显示 NUMA 节点带宽
--showhw:显示硬件详细信息
AMD Instinct MI300X OAM 示例:
其中 --showproductname 显示了 GPU 系列、型号和供应商以及其他详细信息。示例输出显示服务器中安装了 AMD Instinct™ MI300X 平台 GPU。
-
jnpr@MI300X-01:/proc$ rocm-smi --showproductname ============================ ROCm System Management Interface ============================ ====================================== Product Info ====================================== GPU[0] : Card Series: AMD Instinct MI300X OAM GPU[0] : Card Model: 0x74a1 GPU[0] : Card Vendor: Advanced Micro Devices, Inc. [AMD/ATI] GPU[0] : Card SKU: M3000100 GPU[0] : Subsystem ID: 0x74a1 GPU[0] : Device Rev: 0x00 GPU[0] : Node ID: 2 GPU[0] : GUID: 28851 GPU[0] : GFX Version: gfx942 GPU[1] : Card Series: AMD Instinct MI300X OAM GPU[1] : Card Model: 0x74a1 GPU[1] : Card Vendor: Advanced Micro Devices, Inc. [AMD/ATI] GPU[1] : Card SKU: M3000100 GPU[1] : Subsystem ID: 0x74a1 GPU[1] : Device Rev: 0x00 GPU[1] : Node ID: 3 GPU[1] : GUID: 51499 GPU[1] : GFX Version: gfx942 ---more--
这些 --showhw 选项显示有关系统中 GPU 的信息,包括 ID
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# rocm-smi --showhw -v ====================================== ROCm System Management Interface ================================= =========================================== Concise Hardware Info ======================================= GPU NODE DID GUID GFX VER GFX RAS SDMA RAS UMC RAS VBIOS BUS PARTITION ID 0 2 0x74a1 28851 gfx942 ENABLED ENABLED ENABLED 113-M3000100-102 0000:05:00.0 0 1 3 0x74a1 51499 gfx942 ENABLED ENABLED ENABLED 113-M3000100-102 0000:27:00.0 0 2 4 0x74a1 57603 gfx942 ENABLED ENABLED ENABLED 113-M3000100-102 0000:47:00.0 0 3 5 0x74a1 22683 gfx942 ENABLED ENABLED ENABLED 113-M3000100-102 0000:65:00.0 0 4 6 0x74a1 53458 gfx942 ENABLED ENABLED ENABLED 113-M3000100-102 0000:85:00.0 0 5 7 0x74a1 26954 gfx942 ENABLED ENABLED ENABLED 113-M3000100-102 0000:A7:00.0 0 6 8 0x74a1 16738 gfx942 ENABLED ENABLED ENABLED 113-M3000100-102 0000:C7:00.0 0 7 9 0x74a1 63738 gfx942 ENABLED ENABLED ENABLED 113-M3000100-102 0000:E5:00.0 0 ========================================================================================================== ============================================ End of ROCm SMI Log ========================================= ========================================= VBIOS ========================================== GPU[0] : VBIOS version: 113-M3000100-102 GPU[1] : VBIOS version: 113-M3000100-102 GPU[2] : VBIOS version: 113-M3000100-102 GPU[3] : VBIOS version: 113-M3000100-102 GPU[4] : VBIOS version: 113-M3000100-102 GPU[5] : VBIOS version: 113-M3000100-102 GPU[6] : VBIOS version: 113-M3000100-102 GPU[7] : VBIOS version: 113-M3000100-102 ==========================================================================================
字段定义如下:
| GPU | 系统上 GPU 的索引,从 0 开始。 |
| 节点 | 与 GPU 关联的 NUMA(非均匀内存访问)节点 ID。帮助识别内存位置。最佳 GPU/NIC 映射通常依赖于 NUMA 邻近性 |
| 做了 | GPU 的设备 ID。这是特定 GPU 型号的唯一标识符。 对于验证确切的 GPU 模型很有用。例如,0x74a1对应的是 MI300X 系列 GPU。 |
| GUID | GPU 唯一标识符。此值特定于每个 GPU,可能与其 PCIe 设备相关。 对于区分多 GPU 环境中的 GPU 很有用。 |
| GFX 虚拟 | GPU 架构的版本(例如,gfx942 属于 AMD 的 RDNA2 系列)。 在 AMD GPU 中,GFX 前缀是 AMD 其 GPU 微架构系列内部命名约定的一部分。 |
| GFX RAS | GPU RAS(可靠性、可用性、可维护性)功能状态。指示错误处理。 |
| SDMA RAS | SDMA(系统直接内存访问)RAS 功能的状态。 |
| UMC RAS | 统一内存控制器 (UMC) RAS 功能的状态。 |
| VBIOS | VBIOS(视频 BIOS)版本。指示 GPU 上运行的固件版本。 所有 GPU 的固件版本 (113-M3000100-102) 相同则表示配置统一。 |
| 公共汽车 | GPU 的 PCIe 总线地址。帮助将 GPU 映射到其物理插槽。 例如,0000:05:00.0 是 PCIe 地址。它允许您将 GPU 与物理插槽或 NUMA 节点相关联。 |
| 分区 ID | GPU 分区或实例 ID。对于多实例 GPU(如 MI300X),这将识别实例。所有值均为 0,表示未为这些 GPU 启用多实例分区。 |
这些 --showbus 选项显示 PCI 总线相关信息,包括 GPU ID 和 PCI 总线 ID 之间的对应关系。
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# rocm-smi --showbus -i ============================ ROCm System Management Interface ============================ =========================================== ID =========================================== GPU[0] : Device Name: AMD Instinct MI300X OAM GPU[0] : Device ID: 0x74a1 GPU[0] : Device Rev: 0x00 GPU[0] : Subsystem ID: 0x74a1 GPU[0] : GUID: 28851 GPU[1] : Device Name: AMD Instinct MI300X OAM GPU[1] : Device ID: 0x74a1 GPU[1] : Device Rev: 0x00 GPU[1] : Subsystem ID: 0x74a1 GPU[1] : GUID: 51499 GPU[2] : Device Name: AMD Instinct MI300X OAM GPU[2] : Device ID: 0x74a1 GPU[2] : Device Rev: 0x00 GPU[2] : Subsystem ID: 0x74a1 GPU[2] : GUID: 57603 ---more--- ========================================================================================== ======================================= PCI Bus ID ======================================= GPU[0] : PCI Bus: 0000:05:00.0 GPU[1] : PCI Bus: 0000:27:00.0 GPU[2] : PCI Bus: 0000:47:00.0 GPU[3] : PCI Bus: 0000:65:00.0 GPU[4] : PCI Bus: 0000:85:00.0 GPU[5] : PCI Bus: 0000:A7:00.0 GPU[6] : PCI Bus: 0000:C7:00.0 GPU[7] : PCI Bus: 0000:E5:00.0 ========================================================================================== ================================== End of ROCm SMI Log ===================================
该 --showmetrics 选项提供有关 GPU 状态和性能的全面信息,包括温度、时钟频率、功耗和 PCIe 带宽等指标。
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# rocm-smi --showmetrics | grep GPU.0 GPU[0] : Metric Version and Size (Bytes): 1.6 1664 GPU[0] : temperature_edge (C): N/A GPU[0] : temperature_hotspot (C): 42 GPU[0] : temperature_mem (C): 35 GPU[0] : temperature_vrgfx (C): N/A GPU[0] : temperature_vrsoc (C): 41 GPU[0] : temperature_vrmem (C): N/A GPU[0] : average_gfx_activity (%): 0 GPU[0] : average_umc_activity (%): 0 GPU[0] : average_mm_activity (%): N/A GPU[0] : average_socket_power (W): N/A GPU[0] : energy_accumulator (15.259uJ (2^-16)): 4291409153508 GPU[0] : system_clock_counter (ns): 508330314785091 GPU[0] : average_gfxclk_frequency (MHz): N/A GPU[0] : average_socclk_frequency (MHz): N/A GPU[0] : average_uclk_frequency (MHz): N/A GPU[0] : average_vclk0_frequency (MHz): N/A GPU[0] : average_dclk0_frequency (MHz): N/A GPU[0] : average_vclk1_frequency (MHz): N/A GPU[0] : average_dclk1_frequency (MHz): N/A GPU[0] : current_gfxclk (MHz): 134 GPU[0] : current_socclk (MHz): 28 GPU[0] : current_uclk (MHz): 900 GPU[0] : current_vclk0 (MHz): 29 GPU[0] : current_dclk0 (MHz): 22 GPU[0] : current_vclk1 (MHz): 29 GPU[0] : current_dclk1 (MHz): 22 GPU[0] : throttle_status: N/A GPU[0] : current_fan_speed (rpm): N/A GPU[0] : pcie_link_width (Lanes): 16 GPU[0] : pcie_link_speed (0.1 GT/s): 320 GPU[0] : gfx_activity_acc (%): 682809151 GPU[0] : mem_activity_acc (%): 60727622 GPU[0] : temperature_hbm (C): ['N/A', 'N/A', 'N/A', 'N/A'] GPU[0] : firmware_timestamp (10ns resolution): 507863813273800 GPU[0] : voltage_soc (mV): N/A GPU[0] : voltage_gfx (mV): N/A GPU[0] : voltage_mem (mV): N/A GPU[0] : indep_throttle_status: N/A GPU[0] : current_socket_power (W): 123 GPU[0] : vcn_activity (%): [0, 0, 0, 0] GPU[0] : gfxclk_lock_status: 0 GPU[0] : xgmi_link_width: 0 GPU[0] : xgmi_link_speed (Gbps): 0 GPU[0] : pcie_bandwidth_acc (GB/s): 626812796806 GPU[0] : pcie_bandwidth_inst (GB/s): 18 ---more---
这些 --showtopo 选项显示系统中的 GPU 如何通过 XGMI(链路类型)相互通信,该 XGMI(链路类型)表示任意两个 GPU 之间的一个跃点。权重 15 表示此直接通信是首选路径。
-
jnpr@MI300X-01:~$ rocm-smi --showtopo ============================ ROCm System Management Interface ============================ ================================ Weight between two GPUs ================================= GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 GPU0 0 15 15 15 15 15 15 15 GPU1 15 0 15 15 15 15 15 15 GPU2 15 15 0 15 15 15 15 15 GPU3 15 15 15 0 15 15 15 15 GPU4 15 15 15 15 0 15 15 15 GPU5 15 15 15 15 15 0 15 15 GPU6 15 15 15 15 15 15 0 15 GPU7 15 15 15 15 15 15 15 0 ================================= Hops between two GPUs ================================== GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 GPU0 0 1 1 1 1 1 1 1 GPU1 1 0 1 1 1 1 1 1 GPU2 1 1 0 1 1 1 1 1 GPU3 1 1 1 0 1 1 1 1 GPU4 1 1 1 1 0 1 1 1 GPU5 1 1 1 1 1 0 1 1 GPU6 1 1 1 1 1 1 0 1 GPU7 1 1 1 1 1 1 1 0 =============================== Link Type between two GPUs =============================== GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 GPU0 0 XGMI XGMI XGMI XGMI XGMI XGMI XGMI GPU1 XGMI 0 XGMI XGMI XGMI XGMI XGMI XGMI GPU2 XGMI XGMI 0 XGMI XGMI XGMI XGMI XGMI GPU3 XGMI XGMI XGMI 0 XGMI XGMI XGMI XGMI GPU4 XGMI XGMI XGMI XGMI 0 XGMI XGMI XGMI GPU5 XGMI XGMI XGMI XGMI XGMI 0 XGMI XGMI GPU6 XGMI XGMI XGMI XGMI XGMI XGMI 0 XGMI GPU7 XGMI XGMI XGMI XGMI XGMI XGMI XGMI 0 ======================================= Numa Nodes ======================================= GPU[0] : (Topology) Numa Node: 0 GPU[0] : (Topology) Numa Affinity: 0 GPU[1] : (Topology) Numa Node: 0 GPU[1] : (Topology) Numa Affinity: 0 GPU[2] : (Topology) Numa Node: 0 GPU[2] : (Topology) Numa Affinity: 0 GPU[3] : (Topology) Numa Node: 0 GPU[3] : (Topology) Numa Affinity: 0 GPU[4] : (Topology) Numa Node: 1 GPU[4] : (Topology) Numa Affinity: 1 GPU[5] : (Topology) Numa Node: 1 GPU[5] : (Topology) Numa Affinity: 1 GPU[6] : (Topology) Numa Node: 1 GPU[6] : (Topology) Numa Affinity: 1 GPU[7] : (Topology) Numa Node: 1 GPU[7] : (Topology) Numa Affinity: 1 ================================== End of ROCm SMI Log =================================== Usage: cma_roce_tos OPTIONS Options: -h show this help -d <dev> use IB device <dev> (default mlx5_0) -p <port> use port <port> of IB device (default 1) -t <TOS> set TOS of RoCE RDMA_CM applications (0)
链路类型、跃点数和权重也可使用特定选项 --showtopoweight 、 --showtopotype和 –showtopoweight:
-
jnpr@MI300X-01:~/SCRIPTS$ rocm-smi --showtopoweight ============================ ROCm System Management Interface ============================ ================================ Weight between two GPUs ================================= GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 GPU0 0 15 15 15 15 15 15 15 GPU1 15 0 15 15 15 15 15 15 GPU2 15 15 0 15 15 15 15 15 GPU3 15 15 15 0 15 15 15 15 GPU4 15 15 15 15 0 15 15 15 GPU5 15 15 15 15 15 0 15 15 GPU6 15 15 15 15 15 15 0 15 GPU7 15 15 15 15 15 15 15 0 ================================== End of ROCm SMI Log =================================== jnpr@MI300X-01:~/SCRIPTS$ rocm-smi --showtopohops ============================ ROCm System Management Interface ============================ ================================= Hops between two GPUs ================================== GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 GPU0 0 1 1 1 1 1 1 1 GPU1 1 0 1 1 1 1 1 1 GPU2 1 1 0 1 1 1 1 1 GPU3 1 1 1 0 1 1 1 1 GPU4 1 1 1 1 0 1 1 1 GPU5 1 1 1 1 1 0 1 1 GPU6 1 1 1 1 1 1 0 1 GPU7 1 1 1 1 1 1 1 0 ================================== End of ROCm SMI Log =================================== jnpr@MI300X-01:~/SCRIPTS$ rocm-smi --showtopotype ============================ ROCm System Management Interface ============================ =============================== Link Type between two GPUs =============================== GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 GPU0 0 XGMI XGMI XGMI XGMI XGMI XGMI XGMI GPU1 XGMI 0 XGMI XGMI XGMI XGMI XGMI XGMI GPU2 XGMI XGMI 0 XGMI XGMI XGMI XGMI XGMI GPU3 XGMI XGMI XGMI 0 XGMI XGMI XGMI XGMI GPU4 XGMI XGMI XGMI XGMI 0 XGMI XGMI XGMI GPU5 XGMI XGMI XGMI XGMI XGMI 0 XGMI XGMI GPU6 XGMI XGMI XGMI XGMI XGMI XGMI 0 XGMI GPU7 XGMI XGMI XGMI XGMI XGMI XGMI XGMI 0 ================================== End of ROCm SMI Log ===================================
显示 --shownodesbw 了内部可用于 GPU 到 GPU 内部通信的带宽:
-
jnpr@MI300X-01:/home/ben$ rocm-smi --shownodesbw ============================ ROCm System Management Interface ============================ ======================================= Bandwidth ======================================== GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 GPU0 N/A 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 GPU1 50000-50000 N/A 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 GPU2 50000-50000 50000-50000 N/A 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 GPU3 50000-50000 50000-50000 50000-50000 N/A 50000-50000 50000-50000 50000-50000 50000-50000 GPU4 50000-50000 50000-50000 50000-50000 50000-50000 N/A 50000-50000 50000-50000 50000-50000 GPU5 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 N/A 50000-50000 50000-50000 GPU6 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 N/A 50000-50000 GPU7 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 50000-50000 N/A Format: min-max; Units: mps "0-0" min-max bandwidth indicates devices are not connected directly ================================== End of ROCm SMI Log ===================================
rocm-smi -h
有关 ROCm-SMI 以及较新的 AMD-SMI CLI 的更多信息,请查看: ROCm 文档、 AMD SMI 文档、 ROCm 和 AMD SMI
NIC 和 GPU 映射
接下来是执行 NIC 到 GPU 的映射,如以下步骤所示。Thor2 和 AMD Pollara 400 NIC 的这些都是相同的。
其他 命令中的信息可以与上述一些选项相结合,以按照以下步骤查找 GPU 和 NIC 之间的相关性:
- 识别 NUMA 节点和 GPU
使用输出 或仅
rocm-smi --showtopo查找rocm-smi --showtoponumaGPU 和 NUMA 节点之间的映射。在输出中查找每个 GPU 的 NUMA 关联 性。本节稍后将介绍此属性的含义。
请注意哪些 GPU 与哪些 NUMA 节点相关联。
示例:
-
jnpr@MI300X-01:/proc$ rocm-smi --showtoponuma ============================ ROCm System Management Interface ============================ ======================================= Numa Nodes ======================================= GPU[0] : (Topology) Numa Node: 0 GPU[0] : (Topology) Numa Affinity: 0 GPU[1] : (Topology) Numa Node: 0 GPU[1] : (Topology) Numa Affinity: 0 GPU[2] : (Topology) Numa Node: 0 GPU[2] : (Topology) Numa Affinity: 0 GPU[3] : (Topology) Numa Node: 0 GPU[3] : (Topology) Numa Affinity: 0 GPU[4] : (Topology) Numa Node: 1 GPU[4] : (Topology) Numa Affinity: 1 GPU[5] : (Topology) Numa Node: 1 GPU[5] : (Topology) Numa Affinity: 1 GPU[6] : (Topology) Numa Node: 1 GPU[6] : (Topology) Numa Affinity: 1 GPU[7] : (Topology) Numa Node: 1 GPU[7] : (Topology) Numa Affinity: 1 ================================== End of ROCm SMI Log ===================================
GPU 0–3 → NUMA 节点 0
GPU 4–7 → NUMA 节点 1
-
- 识别 NIC 的 NUMA 节点
导航到
/sys/class/net/目录并检查每个网络接口(不包括 lo 或 docker 接口)的 NUMA 节点关联 性:-
for iface in $(ls /sys/class/net/ | grep -Ev '^(lo|docker)'); do numa_node=$(cat /sys/class/net/$iface/device/numa_node 2>/dev/null) echo "Interface: $iface, NUMA Node: $numa_node" done
请注意每个 NIC 接口的 NUMA 节点关联性。
示例:
-
jnpr@MI300X-01:~/SCRIPTS$ for iface in $(ls /sys/class/net/ | grep -Ev '^(lo|docker)'); do numa_node=$(cat /sys/class/net/$iface/device/numa_node 2>/dev/null) echo "Interface: $iface, NUMA Node: $numa_node" done Interface: ens61f1np1, NUMA Node: 1 Interface: enxbe3af2b6059f, NUMA Node: Interface: gpu0_eth, NUMA Node: 0 Interface: gpu1_eth, NUMA Node: 0 Interface: gpu2_eth, NUMA Node: 0 Interface: gpu3_eth, NUMA Node: 0 Interface: gpu4_eth, NUMA Node: 1 Interface: gpu5_eth, NUMA Node: 1 Interface: gpu6_eth, NUMA Node: 1 Interface: gpu7_eth, NUMA Node: 1 Interface: mgmt_eth, NUMA Node: 1 Interface: stor0_eth, NUMA Node: 0 Interface: stor1_eth, NUMA Node: 0
-
- 基于 NUMA 关联性将 GPU 与 NIC 关联
使用步骤 1 (GPU) 和步骤 2 (NIC) 中的 NUMA 节点关联,将每个 GPU 映射到同一 NUMA 节点内的 NIC:
示例:
-
GPU0 (NUMA 0): - NIC: gpu0_eth (NUMA 0) - NIC: gpu1_eth (NUMA 0) - NIC: gpu2_eth (NUMA 0) - NIC: gpu3_eth (NUMA 0) - NIC: stor0_eth (NUMA 0) - NIC: stor1_eth (NUMA 0) GPU4 (NUMA 1): - NIC: gpu4_eth (NUMA 1) - NIC: gpu5_eth (NUMA 1) - NIC: gpu6_eth (NUMA 1) - NIC: gpu7_eth (NUMA 1) - NIC: mgmt_eth (NUMA 1)
-
jnpr@MI300X-01:~/SCRIPTS$ cat GPU-to-NIC_YL.sh #!/bin/bash # Temporary data files gpu_to_numa_file="GPU-to-NUMA.tmp" nic_to_numa_file="NIC-to-NUMA.tmp" output_file="NIC-to-GPU.txt" # Clear or create the output file > "$output_file" # Step 1: Parse GPUs and NUMA nodes echo "Step 1: Parsing GPUs and NUMA Nodes..." rocm-smi --showtoponuma > /tmp/rocm_smi_output.tmp 2>/dev/null if [[ $? -ne 0 ]]; then echo "Error: rocm-smi is not installed or failed to run." exit 1 fi # Extract GPU and NUMA information grep "GPU" /tmp/rocm_smi_output.tmp | grep "Numa Node" | awk -F'[ :]' '{print $2, $NF}' | sed 's/^/GPU /' > "$gpu_to_numa_file" # Step 2: Parse NICs and NUMA nodes echo "Step 2: Parsing NICs and NUMA Nodes..." > "$nic_to_numa_file" for iface in $(ls /sys/class/net/ | grep -Ev '^(lo|docker)'); do numa_node=$(cat /sys/class/net/$iface/device/numa_node 2>/dev/null) if [[ $numa_node -ge 0 ]]; then echo "NIC $iface, NUMA Node: $numa_node" >> "$nic_to_numa_file" fi done # Step 3: Match GPUs to NICs based on NUMA affinity echo "Step 3: Mapping GPUs to NICs..." while read -r gpu_entry; do gpu=$(echo "$gpu_entry" | awk '{print $2}') gpu_numa=$(echo "$gpu_entry" | awk '{print $NF}') echo "GPU$gpu (NUMA $gpu_numa):" >> "$output_file" while read -r nic_entry; do nic=$(echo "$nic_entry" | awk '{print $2}' | sed 's/,//') nic_numa=$(echo "$nic_entry" | awk '{print $NF}') if [[ "$gpu_numa" == "$nic_numa" ]]; then echo " - NIC: $nic" >> "$output_file" fi done < "$nic_to_numa_file" done < "$gpu_to_numa_file" # Output the result echo "Mapping complete! Results saved in $output_file." cat "$output_file"
示例:
-
jnpr@MI300X-01:~/SCRIPTS$ ./GPU-to-NIC_YL.sh Step 1: Parsing GPUs and NUMA Nodes... Step 2: Parsing NICs and NUMA Nodes... Step 3: Mapping GPUs to NICs... Mapping complete! Results saved in NIC-to-GPU.txt. GPU0 (NUMA 0): - NIC: gpu0_eth - NIC: gpu1_eth - NIC: gpu2_eth - NIC: gpu3_eth - NIC: stor0_eth - NIC: stor1_eth GPU0 (NUMA 0): - NIC: gpu0_eth - NIC: gpu1_eth - NIC: gpu2_eth - NIC: gpu3_eth - NIC: stor0_eth - NIC: stor1_eth GPU0 (NUMA 0): - NIC: gpu0_eth - NIC: gpu1_eth - NIC: gpu2_eth - NIC: gpu3_eth - NIC: stor0_eth - NIC: stor1_eth GPU0 (NUMA 0): - NIC: gpu0_eth - NIC: gpu1_eth - NIC: gpu2_eth - NIC: gpu3_eth - NIC: stor0_eth - NIC: stor1_eth GPU1 (NUMA 1): - NIC: ens61f1np1 - NIC: gpu4_eth - NIC: gpu5_eth - NIC: gpu6_eth - NIC: gpu7_eth - NIC: mgmt_eth GPU1 (NUMA 1): - NIC: ens61f1np1 - NIC: gpu4_eth - NIC: gpu5_eth - NIC: gpu6_eth - NIC: gpu7_eth - NIC: mgmt_eth GPU1 (NUMA 1): - NIC: ens61f1np1 - NIC: gpu4_eth - NIC: gpu5_eth - NIC: gpu6_eth - NIC: gpu7_eth - NIC: mgmt_eth GPU1 (NUMA 1): - NIC: ens61f1np1 - NIC: gpu4_eth - NIC: gpu5_eth - NIC: gpu6_eth - NIC: gpu7_eth - NIC: mgmt_eth
您会注意到,GPU 与 NIC 之间没有 1:1 的关联。相反,多个 NIC 接口与 GPU 相关联。这是因为它们属于相同的非统一内存访问 (NUMA) 节点关联。
采用 NUMA 架构的系统包含硬件资源的集合,包括 CPU、GPU、内存和 PCIe 设备(包括 NIC),这些资源组合在一起,称为“NUMA 节点”。这些资源被视为彼此的“本地”资源。从 GPU 的角度来看,同一 NUMA 节点中的设备与该 GPU 的关联最密切。NUMA 节点由 NUMA 关联标识。
多个 NIC 和 GPU 可以连接到同一个 PCIe 复合体或 NUMA 节点内的交换机。这使得共享该综合体的所有 GPU 都可以访问 NIC。但是,虽然同一节点中的任何 GPU 都可以访问 NUMA 节点中的所有 NIC,但 NIC 会根据可用性、流量类型、延迟等动态分配给给定 GPU 使用。
同一 NUMA 节点上的 GPU(例如 GPU1 ↔、GPU2)之间的通信:
同一 NUMA 节点上的 GPU(例如 GPU1 和 GPU2)直接通过高带宽、低延迟互连进行通信,例如 Infinity 交换矩阵 (在 AMD 系统中)。
这些互连完全避开了 CPU 和主内存,与跨 NUMA 通信相比,通信速度要快得多。由于两个 GPU 都位于同一内存控制器和 CPU 的“本地”,因此通信路径得到了高度优化。
不同 NUMA 节点上的 GPU 之间的通信(例如 GPU1 ↔、GPU4):
不同 NUMA 节点上的 GPU 之间的通信(例如,NUMA 0 上的 GPU1 和 NUMA 1 上的 GPU4)必须遍历系统架构的其他层,这会带来更高的延迟。路径通常如下:
- GPU1 → CPU (NUMA 0):数据从 GPU1 发送到 NUMA 0 上的 CPU。
- NUMA 间链路:NUMA 0 和 NUMA 1 中的 CPU 通过互连连接,例如 Infinity 交换矩阵或 UPI(超路径互连)。
- CPU (NUMA 1) → GPU4:数据从 NUMA 1 上的 CPU 转发到 GPU4。
更改 NIC 属性
本节介绍如何添加或更改 NIC 的 接口名称、 MTU、 DNS、 IP 地址 和 路由表条目。
编辑和重新应用网络配置 (netplan) 文件
网络配置在以下 netplan *.yaml 文件中进行了描述: /etc/netplan/。
请注意,实际文件名可能会有所不同。示例:
/etc/netplan/01-netcfg.yaml
/etc/netplan/00-installer-config.yaml
更改任何接口属性都需要编辑此文件并重新应用网络计划,如下所示:
- 查找逻辑接口的默认名称。
您可以使用以下步骤来实现此目的:
Thor2 NIC 输出:
-
jnpr@MI300X-01:~$ > devnames1; for iface in $(ls /sys/class/net/ | grep -Ev '^(lo|docker|virbr)'); do device=$(ethtool -i $iface 2>/dev/null | grep 'bus-info' | awk '{print $2}'); if [[ $device != 0000:* ]]; then device="0000:$device"; fi; model=$(lspci -s $device 2>/dev/null | awk -F ': ' '{print $2}'); echo "$iface:$model" >> devnames1; done jnpr@MI300X-01:~$ cat devnames1 ens61f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] enxbe3af2b6059f: ens41np0:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) ens42np0:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) ens32np0:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) ens31np0:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) ens21np0:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) ens22np0:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) ens12np0:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) ens11np0:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) ens61f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] ens50f0np0:Mellanox Technologies MT2910 Family [ConnectX-7] ens50f1np1:Mellanox Technologies MT2910 Family [ConnectX-7]
接口
ens31np0:地点
- zh:以太网网络接口。
- S31:表示系统总线上网络接口的物理位置。总线上的插槽编号 31。
- NP0:
- n:网络(表示是网络端口)。
- p0:端口 0(表示它是此网络接口的第一个端口)。
AMD Pollara 400 NIC 输出
-
jnpr@mi300-01:~# > devnames1; for iface in $(ls /sys/class/net/ | grep -Ev '^(lo|docker|virbr)'); do device=$(ethtool -i $iface 2>/dev/null | grep 'bus-info' | awk '{print $2}'); if [[ $device != 0000:* ]]; then device="0000:$device"; fi; model=$(lspci -s $device 2>/dev/null | awk -F ': ' '{print $2}'); echo "$iface:$model" >> devnames1; done jnpr@mi300-01:~# cat devnames1 ens61f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] eth3: gpu0_eth:Pensando Systems DSC Ethernet Controller gpu1_eth:Pensando Systems DSC Ethernet Controller gpu2_eth:Pensando Systems DSC Ethernet Controller gpu3_eth:Pensando Systems DSC Ethernet Controller gpu4_eth:Pensando Systems DSC Ethernet Controller gpu5_eth:Pensando Systems DSC Ethernet Controller gpu6_eth:Pensando Systems DSC Ethernet Controller gpu7_eth:Pensando Systems DSC Ethernet Controller mgmt_eth:Mellanox Technologies MT2910 Family [ConnectX-7] stor0_eth:Mellanox Technologies MT2910 Family [ConnectX-7] stor1_eth:Mellanox Technologies MT2910 Family [ConnectX-7]
您可以使用该脚本
gpunic.py查找每个 pcie 总线的 GPU 和 NIC 之间的映射,以确定需要如何重命名 NIC 以保持一致性。示例:
-
jnpr@MI300X-01:~/SCRIPTS$ sudo python3 amd_map_nic_gpu.py bus 0000:00:01.1: 0000:05:00.0 (gpu) - GPU0 0000:08:00.0 (gpu) - - 0000:08:00.1 (gpu) - - 0000:08:00.2 (gpu) - - 0000:09:00.0 (nic) - gpu0_eth bus 0000:20:01.1: 0000:25:00.0 (gpu) - - 0000:25:00.1 (gpu) - - 0000:25:00.2 (gpu) - - 0000:26:00.0 (nic) - gpu1_eth 0000:29:00.0 (gpu) - GPU1 bus 0000:20:03.1: 0000:31:00.0 (nic) - stor0_eth 0000:31:00.1 (nic) - stor1_eth bus 0000:40:01.1: 0000:45:00.0 (gpu) - - 0000:45:00.1 (gpu) - - 0000:45:00.2 (gpu) - - 0000:46:00.0 (nic) - gpu2_eth 0000:49:00.0 (gpu) - GPU2 bus 0000:60:01.1: 0000:65:00.0 (gpu) - GPU3 0000:68:00.0 (gpu) - - 0000:68:00.1 (gpu) - - 0000:68:00.2 (gpu) - - 0000:69:00.0 (nic) - gpu3_eth bus 0000:60:05.4: 0000:6e:00.0 (gpu) - - bus 0000:80:01.1: 0000:85:00.0 (gpu) - GPU4 0000:88:00.0 (gpu) - - 0000:88:00.1 (gpu) - - 0000:88:00.2 (gpu) - - 0000:89:00.0 (nic) - gpu4_eth bus 0000:a0:01.1: 0000:a5:00.0 (gpu) - - 0000:a5:00.1 (gpu) - - 0000:a5:00.2 (gpu) - - 0000:a6:00.0 (nic) - gpu5_eth 0000:a9:00.0 (gpu) - GPU5 bus 0000:c0:01.1: 0000:c5:00.0 (gpu) - - 0000:c5:00.1 (gpu) - - 0000:c5:00.2 (gpu) - - 0000:c6:00.0 (nic) - gpu6_eth 0000:c9:00.0 (gpu) - GPU6 bus 0000:c0:03.1: 0000:d2:00.0 (nic) - mgmt_eth 0000:d2:00.1 (nic) - ens61f1np1 bus 0000:e0:01.1: 0000:e5:00.0 (gpu) - GPU7 0000:e8:00.0 (gpu) - - 0000:e8:00.1 (gpu) - - 0000:e8:00.2 (gpu) - - 0000:e9:00.0 (nic) - gpu7_eth
要进一步识别接口,可以使用命令sudo ethtool <device> | grep Speed
-
jnpr@MI300X-01:~/SCRIPTS$ sudo ethtool ens61f0np0| grep Speed Speed: 400000Mb/s jnpr@MI300X-01:~/SCRIPTS$ sudo ethtool enp47s0f0np0| grep Speed Speed: 200000Mb/s jnpr@MI300X-01:~/SCRIPTS$ sudo ethtool enp208s0f0np0| grep Speed Speed: 100000Mb/s
您需要确保连接到 GPU 后端交换矩阵、存储后端交换矩阵和前端交换矩阵的 NIC 分别为 400GE 接口、200GE 接口和 100GE 接口。
默认接口名称 新名称 速度 enp6s0np0 gpu0_eth 400GE ENP35S0NP0 gpu1_eth 400GE ENP67S0NP0 gpu2_eth 400GE ENP102S0NP0 gpu3_eth 400GE ENP134S0NP0 gpu4_eth 400GE ENP163S0NP0 gpu5_eth 400GE ENP195S0NP0 gpu6_eth 400GE ENP230S0NP0 gpu7_eth 400GE ENP47S0F0NP0 stor0_eth 200GE ENP47S0f0NP1 stor1_eth 200GE ENP208S0F0NP0 mgmt_eth 100GE -
- 查找接口的 MAC 地址:
您可以使用该
ip linkshow <device>命令。示例:
-
jnpr@MI300X-01:~/SCRIPTS$ ip link show ens61f0np0 | grep "link/ether" link/ether 5c:25:73:66:c3:ee brd ff:ff:ff:ff:ff:ff jnpr@MI300X-01:~/SCRIPTS$ ip link show enp35s0np0 | grep "link/ether" link/ether 5c:25:73:66:bc:5e brd ff:ff:ff:ff:ff:ff
默认接口名称、 新名称 、MAC 地址 enp6s0np0 gpu0_eth 7c:c2:55:bd:75:d0 ENP35S0NP0 gpu1_eth 7c:c2:55:bd:79:20 ENP67S0NP0 gpu2_eth 7c:c2:55:bd:7d:f0 ENP102S0NP0 gpu3_eth 7c:c2:55:bd:7e:20 ENP134S0NP0 gpu4_eth 7c:c2:55:bd:75:10 ENP163S0NP0 gpu5_eth 7c:c2:55:bd:7d:c0 ENP195S0NP0 gpu6_eth 7c:c2:55:bd:84:90 ENP230S0NP0 gpu7_eth 7c:c2:55:bd:83:10 ENP47S0F0NP0 stor0_eth 5c:25:73:66:bc:5e ENP47S0f0NP1 stor1_eth 5c:25:73:66:bc:5f ENP208S0F0NP0 mgmt_eth 5c:25:73:66:c3:ee -
- 使用在前面步骤中确定的新名称和 MAC 地址修改网络计划配置文件。
示例:
-
network: version: 2 ethernets: gpu0_eth: match: macaddress: 7c:c2:55:bd:75:d0 <= MAC address associated to the original ens61f0np0. Will become gpu0_eth. dhcp4: false mtu: 9000 <= Interface’s MTU (default = 1500) addresses: - 10.200.16.18/24 <= New IP address(s) routes: - to: 10.200.0.0/16 <= New route(s). Example shows route for 10.200.0.0/16 via 10.200.16.254 via: 10.200.16.254 from: 10.200.16.18 set-name: gpu0_eth <= New interface name ---more---
编辑文件时,请确保保持适当的缩进和连字符(例如在 IP 地址、路由等之前)。对于 IP 地址,请确保包含子网掩码。
以下是实验室中一台 MI300X 服务器的 netplan 配置文件示例:
-
jnpr@MI300X-01:/etc/netplan$ cat 00-installer-config.yaml network: version: 2 ethernets: mgmt_eth: match: macaddress: 5c:25:73:66:c3:ee dhcp4: false addresses: - 10.10.1.25/31 nameservers: addresses: - 8.8.8.8 routes: - to: default via: 10.10.1.24 set-name: mgmt_eth stor0_eth: match: macaddress: 5c:25:73:66:bc:5e dhcp4: false mtu: 9000 addresses: - 10.100.5.3/31 routes: - to: 10.100.0.0/21 via: 10.100.5.2 set-name: stor0_eth stor1_eth: match: macaddress: 5c:25:73:66:bc:5f dhcp4: false mtu: 9000 addresses: - 10.100.5.5/31 routes: - to: 10.100.0.0/21 via: 10.100.5.4 set-name: stor1_eth gpu0_eth: match: macaddress: 7c:c2:55:bd:75:d0 dhcp4: false mtu: 9000 addresses: - 10.200.16.18/24 routes: - to: 10.200.0.0/16 via: 10.200.16.254 from: 10.200.16.18 set-name: gpu0_eth gpu1_eth: match: macaddress: 7c:c2:55:bd:79:20 dhcp4: false mtu: 9000 addresses: - 10.200.17.18/24 routes: - to: 10.200.0.0/16 via: 10.200.17.254 from: 10.200.17.18 set-name: gpu1_eth gpu2_eth: match: macaddress: 7c:c2:55:bd:7d:f0 dhcp4: false mtu: 9000 addresses: - 10.200.18.18/24 routes: - to: 10.200.0.0/16 via: 10.200.18.254 from: 10.200.18.18 set-name: gpu2_eth gpu3_eth: match: macaddress: 7c:c2:55:bd:7e:20 dhcp4: false mtu: 9000 addresses: - 10.200.19.18/24 routes: - to: 10.200.0.0/16 via: 10.200.19.254 from: 10.200.19.18 set-name: gpu3_eth gpu4_eth: match: macaddress: 7c:c2:55:bd:75:10 dhcp4: false mtu: 9000 addresses: - 10.200.20.18/24 routes: - to: 10.200.0.0/16 via: 10.200.20.254 from: 10.200.20.18 set-name: gpu4_eth gpu5_eth: match: macaddress: 7c:c2:55:bd:7d:c0 dhcp4: false mtu: 9000 addresses: - 10.200.21.18/24 routes: - to: 10.200.0.0/16 via: 10.200.21.254 from: 10.200.21.18 set-name: gpu5_eth gpu6_eth: match: macaddress: 7c:c2:55:bd:84:90 dhcp4: false mtu: 9000 addresses: - 10.200.22.18/24 routes: - to: 10.200.0.0/16 via: 10.200.22.254 from: 10.200.22.18 set-name: gpu6_eth gpu7_eth: match: macaddress: 7c:c2:55:bd:83:10 dhcp4: false mtu: 9000 addresses: - 10.200.23.18/24 routes: - to: 10.200.0.0/16 via: 10.200.23.254 from: 10.200.23.18 set-name: gpu7_eth
-
-
保存文件并使用 netplan apply 命令应用更改。
jnpr@MI300X-01:/etc/netplan$ sudo netplan apply
jnpr@MI300X-01:/etc/netplan$
- 验证更改是否已正确应用。
检查新接口名称是否正确:
Thor2 NIC 输出:
-
root@MI300X-01:/home/jnpr/SCRIPTS# > devnames; for iface in $(ls /sys/class/net/ | grep -Ev '^(lo|docker|virbr)'); do device=$(ethtool -i $iface 2>/dev/null | grep 'bus-info' | awk '{print $2}'); if [[ $device != 0000:* ]]; then device="0000:$device"; fi; model=$(lspci -s $device 2>/dev/null | awk -F ': ' '{print $2}'); echo "$iface:$model" >> devnames; done root@MI300X-01:/home/jnpr/SCRIPTS# cat devnames ens61f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] enxbe3af2b6059f: gpu0_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu1_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu2_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu3_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu4_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu5_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu6_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu7_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) mgmt_eth:Mellanox Technologies MT2910 Family [ConnectX-7] stor0_eth:Mellanox Technologies MT2910 Family [ConnectX-7] stor1_eth:Mellanox Technologies MT2910 Family [ConnectX-7]
同一命令的 AMD Pollara NIC 输出:
-
jnpr@mi300-01:~$ > devnames; for iface in $(ls /sys/class/net/ | grep -Ev '^(lo|docker|virbr)'); do device=$(ethtool -i $iface 2>/dev/null | grep 'bus-info' | awk '{print $2}'); if [[ $device != 0000:* ]]; then device="0000:$device"; fi; model=$(lspci -s $device 2>/dev/null | awk -F ': ' '{print $2}'); echo "$iface:$model" >> devnames; done jnpr@mi300-01:~$ cat devnames ens61f1np1:Mellanox Technologies MT2910 Family [ConnectX-7] eth3: gpu0_eth:Pensando Systems DSC Ethernet Controller gpu1_eth:Pensando Systems DSC Ethernet Controller gpu2_eth:Pensando Systems DSC Ethernet Controller gpu3_eth:Pensando Systems DSC Ethernet Controller gpu4_eth:Pensando Systems DSC Ethernet Controller gpu5_eth:Pensando Systems DSC Ethernet Controller gpu6_eth:Pensando Systems DSC Ethernet Controller gpu7_eth:Pensando Systems DSC Ethernet Controller mgmt_eth:Mellanox Technologies MT2910 Family [ConnectX-7] stor0_eth:Mellanox Technologies MT2910 Family [ConnectX-7] stor1_eth:Mellanox Technologies MT2910 Family [ConnectX-7]
验证 IP 地址配置是否正确:
-
user@MI300X-03:~/scripts$ ip address show gpu0_eth 4: gpu0_eth: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc mq state UP group default qlen 1000 link/ether 6c:92:cf:87:cc:00 brd ff:ff:ff:ff:ff:ff inet 10.200.24.22/24 brd 10.200.24.255 scope global gpu0_eth valid_lft forever preferred_lft forever inet6 fe80::6e92:cfff:fe87:cc00/64 scope link valid_lft forever preferred_lft forever
或
-
jnpr@MI300X-01:/etc/netplan$ ifconfig gpu0_eth gpu0_eth: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 9000 inet 10.200.16.18 netmask 255.255.255.0 broadcast 10.200.16.255 inet6 fe80::7ec2:55ff:febd:75d0 prefixlen 64 scopeid 0x20<link> ether 7c:c2:55:bd:75:d0 txqueuelen 1000 (Ethernet) RX packets 253482 bytes 28518251 (28.5 MB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 38519 bytes 10662707 (10.6 MB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
检查路由是否已正确添加到路由表中:
-
jnpr@MI300X-01:/etc/netplan$ route | grep mgmt_eth default _gateway 0.0.0.0 UG 0 0 0 mgmt_eth 10.10.1.24 0.0.0.0 255.255.255.254 U 0 0 0 mgmt_eth jnpr@MI300X-01:/etc/netplan$ route | grep gpu0_eth 10.200.0.0 10.200.16.254 255.255.0.0 UG 0 0 0 gpu0_eth 10.200.16.0 0.0.0.0 255.255.255.0 U 0 0 0 gpu0_eth
或
-
user@MI300X-03:~/scripts$ ip route show | grep gpu0_eth 10.200.24.0/24 dev gpu0_eth proto kernel scope link src 10.200.24.22
检查地址解析:
-
jnpr@MI300X-01:/etc/netplan$ ping google.com -c 5 -n PING google.com (142.250.188.14) 56(84) bytes of data. 64 bytes from 142.250.188.14: icmp_seq=1 ttl=113 time=2.16 ms 64 bytes from 142.250.188.14: icmp_seq=2 ttl=113 time=2.43 ms 64 bytes from 142.250.188.14: icmp_seq=3 ttl=113 time=191 ms 64 bytes from 142.250.188.14: icmp_seq=4 ttl=113 time=50.6 ms 64 bytes from 142.250.188.14: icmp_seq=5 ttl=113 time=12.0 ms --- google.com ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4005ms rtt min/avg/max/mdev = 2.158/51.596/190.818/71.851 ms
AMD Pollara 固件和依赖库
为简洁起见,此处描述的步骤仅涉及为 AMD Pollara 400 NIC 启用 RCCL 测试,因此需要安装所有必要的依赖软件和库才能运行 RCCL 测试。所涉及的步骤与 AMD 服务器和 NIC 固件以及 RCCL 支持库 表中列出的库有关。
- 确保 ubuntu OS 版本为 22.04,如 AMD 服务器和 NIC 固件以及 RCCL 支持库一节中的建议
-
Install ROCm library as suggested in below steps. wget https://repo.radeon.com/amdgpu-install/6.3.3/ubuntu/jammy/amdgpu-install_6.3.60303-1_all.deb sudo apt install ./amdgpu-install_6.3.60303-1_all.deb sudo apt update sudo apt install amdgpu-dkms rocm sudo apt install cmake libstdc++-12-dev
-
- 按照以下步骤中的建议安装 RCCL 库。请注意,RCCL 和 ANP 是 AMD 提供的私有库。
-
tar xf rccl-7961624_may21.tgz cd rccl-7961624 ./install.sh -l --prefix=build --disable-mscclpp --disable-msccl-kernel
-
- 安装统一通信框架 (UCX)。统一通信框架 (UCX) 是一个开源的跨平台框架,旨在为各种网络编程模型和接口提供一组通用的通信接口,有关更多信息,请参阅 AMD 文档 。
-
sudo apt install libtool git clone https://github.com/openucx/ucx.git cd ucx ./autogen.sh mkdir build cd build ../configure --prefix=/opt/ucx --with-rocm=/opt/rocm ../configure --prefix=/opt/ucx make -j $(nproc) sudo make -j $(nproc) install
-
- 接下来,安装 OpenMPI。请注意,OpenMPI 是 GitHub 链接,因此可能需要 GitHub 凭据。开放 MPI 项目是一个开源消息传递接口实现,由学术、研究和行业合作伙伴组成的联盟开发和维护。因此,Open MPI 能够结合整个高性能计算社区的专业知识、技术和资源,以构建可用的最佳 MPI 库,请参阅 OpenMPI 了解更多信息。
-
sudo apt install flex git clone --recursive https://github.com/open-mpi/ompi.git cd ompi ./autogen.pl mkdir build cd build ../configure --prefix=/opt/ompi --with-ucx=/opt/ucx --with-rocm=/opt/rocm make -j $(nproc) sudo make install
-
- 安装 Pollara 驱动程序和固件。这是 AMD 提供的固件包。该固件还将安装“nicctl”命令行实用程序以与 Pollara NIC 交互并运行命令以重置卡或配置 QOS 等。
-
# Prerequisites sudo apt install device-tree-compiler policycoreutils ninja-build jq pkg-config libnl-3-dev libnl-route-3-dev libpci-dev # Untar the bundle itself tar xf ainic_bundle_1.113.0-a-2.tar.gz # cd into the bundle directory cd ainic_bundle_1.113.0-a-2 # untar the host software tar xf host_sw_pkg.tar.gz # cd into the host software directory cd host_sw_pkg # install the drivers and software sudo ./install.sh
固件版本的输出:
-
jnpr@MI300-01:~/ainic_bundle_1.110.0-a-79$ sudo nicctl update firmware --image ./ainic_fw_salina.tar --log-file /tmp/amd_ainic_upgrade.log ---------------------------------------------------------------------------------- Card Id Stage Progress ---------------------------------------------------------------------------------- 42424650-4c32-3530-3130-313346000000 Done 100% [02:50.941] 42424650-4c32-3530-3130-313844000000 Done 100% [02:41.200] 42424650-4c32-3530-3130-313242000000 Done 100% [02:51.584] 42424650-4c32-3530-3130-304341000000 Done 100% [02:51.281] 42424650-4c32-3530-3130-313434000000 Done 100% [02:31.062] 42424650-4c32-3530-3130-314537000000 Done 100% [02:51.480] 42424650-4c32-3530-3130-314436000000 Done 100% [02:51.077] 42424650-4c32-3530-3130-304435000000 Done 100% [02:51.367] NIC 42424650-4c32-3530-3130-313346000000 (0000:06:00.0) : Successful NIC 42424650-4c32-3530-3130-313844000000 (0000:23:00.0) : Successful NIC 42424650-4c32-3530-3130-313242000000 (0000:43:00.0) : Successful NIC 42424650-4c32-3530-3130-304341000000 (0000:66:00.0) : Successful NIC 42424650-4c32-3530-3130-313434000000 (0000:86:00.0) : Successful NIC 42424650-4c32-3530-3130-314537000000 (0000:a3:00.0) : Successful NIC 42424650-4c32-3530-3130-314436000000 (0000:c3:00.0) : Successful NIC 42424650-4c32-3530-3130-304435000000 (0000:e6:00.0) : Successful
-
- 固件安装完成后,运行重置卡以显示固件版本。
Pollara 固件更新的 NIC 输出
-
jnpr@mi300-01:~$ sudo nicctl reset card --all NIC 42424650-4c32-3530-3130-313346000000 (0000:06:00.0) : Card reset triggered, wait for completion (75 secs) NIC 42424650-4c32-3530-3130-313844000000 (0000:23:00.0) : Card reset triggered, wait for completion (75 secs) NIC 42424650-4c32-3530-3130-313242000000 (0000:43:00.0) : Card reset triggered, wait for completion (75 secs) NIC 42424650-4c32-3530-3130-304341000000 (0000:66:00.0) : Card reset triggered, wait for completion (75 secs) NIC 42424650-4c32-3530-3130-313434000000 (0000:86:00.0) : Card reset triggered, wait for completion (75 secs) NIC 42424650-4c32-3530-3130-314537000000 (0000:a3:00.0) : Card reset triggered, wait for completion (75 secs) NIC 42424650-4c32-3530-3130-314436000000 (0000:c3:00.0) : Card reset triggered, wait for completion (75 secs) NIC 42424650-4c32-3530-3130-304435000000 (0000:e6:00.0) : Card reset triggered, wait for completion (75 secs) NIC 42424650-4c32-3530-3130-313346000000 (0000:06:00.0) : Card reset successful NIC 42424650-4c32-3530-3130-313844000000 (0000:23:00.0) : Card reset successful NIC 42424650-4c32-3530-3130-313242000000 (0000:43:00.0) : Card reset successful NIC 42424650-4c32-3530-3130-304341000000 (0000:66:00.0) : Card reset successful NIC 42424650-4c32-3530-3130-313434000000 (0000:86:00.0) : Card reset successful NIC 42424650-4c32-3530-3130-314537000000 (0000:a3:00.0) : Card reset successful NIC 42424650-4c32-3530-3130-314436000000 (0000:c3:00.0) : Card reset successful NIC 42424650-4c32-3530-3130-304435000000 (0000:e6:00.0) : Card reset successful jnpr@mi300-01:~$ sudo nicctl show card --detail | grep Firm Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79 Firmware version : 1.110.0-a-79
-
- 安装ANP插件。ANP 是一个插件库,旨在通过扩展的网络传输支持来增强 RCCL 集体通信库。ANP 插件库是一个私有 AMD 库。
-
sudo apt install libboost-dev export RCCL_BUILD=/home/${User}/pollara/rccl-7961624/build/release export MPI_INCLUDE=/opt/ompi/include export MPI_LIB_PATH=/opt/ompi/lib make RCCL_BUILD=$RCCL_BUILD MPI_INCLUDE=$MPI_INCLUDE MPI_LIB_PATH=$MPI_LIB_PATH
-
- 最后,构建 RCCL 测试
Build rccl-tests git clone https://github.com/ROCm/rccl-tests.git cd rccl-tests make MPI=1 MPI_HOME=/opt/ompi NCCL_HOME=/home/${User}/pollara/rccl-7961624/build/release CUSTOM_RCCL_LIB=/home/${User}/pollara/rccl-7961624/build/release/librccl.so -j $(nproc) make MPI=1 MPI_HOME=/opt/ompi NCCL_HOME=/home/dbarmann/pollara/rccl-7961624/build/release HIP_HOME=/home/${User}/pollara/rccl-7961624/build/release CUSTOM_RCCL_LIB=/home/${User}/pollara/rccl-7961624/build/release/librccl.so -j $(nproc)
Broadcom BCM957608用于 RDMA 流量的 Thor2 DCQCN 配置
AMD 服务器中的默认 DCQN-ECN/PFC 属性。
网络接口适配器配置了以下用于 RoCE 流量的服务等级(包括 DCQCN-ECN)参数:
对于 Thor2 NIC 适配器:
- 启用 RoCEv2 (RDMA over IPv4)
- 启用拥塞控制 (ECN) 和 PFC
- 在优先级 3 上用 DSCP 26 标记的 RoCE 流量
- 使用 DSCP 48 和 PRIORITY 7 标记的 RoCE CNP 流量
映射 Broadcom 和逻辑接口名称,以配置 AMD 服务器中 RDMA 的 DCQN-ECN/PFC 和 TOS/DSCP 流量属性
需要在连接到GPU后端的接口上配置DCQCN、ECN、PFC和流量标记;仅在 GPU#_eth (#=0-7) 接口上。
在本文档的“ 更改NIC属性 ”部分中,我们确定服务器中的 gpu#_eth 接口是 Broadcom BCM957608(如下所示)NIC。
-
root@MI300X-01:/home/jnpr/SCRIPTS# cat devnames | grep gpu gpu0_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu1_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu2_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu3_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu4_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu5_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu6_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11) gpu7_eth:Broadcom Inc. and subsidiaries BCM957608 25Gb/50Gb/100Gb/200Gb/400Gb Ethernet (rev 11)
本节中配置服务等级的所有步骤都将重点介绍这些 Broadcom 接口。
我们将结合使用 Linux 系统命令和 Broadcom 工具来启用、调整和监控 DCQCN ECN/PFC作和 RoCE 流量标记。对于其中一些命令,我们需要找到与每个 GPU 接口关联的 Broadcom 接口名称。请按照以下步骤查找这些映射:
- 使用以下逻辑查找每个 gpu#_eth 接口的 PCI 地址:
-
for iface in $(ls /sys/class/net | grep -E 'gpu[0-9]+_eth'); do pci_addr=$(readlink -f /sys/class/net/$iface/device | awk -F '/' '{print $NF}') echo "$iface => $pci_addr" done1
示例:
-
root@MI300X-01:/home/jnpr/SCRIPTS# for iface in $(ls /sys/class/net | grep -E 'gpu[0-9]+_eth'); do pci_addr=$(readlink -f /sys/class/net/$iface/device | awk -F '/' '{print $NF}') echo "$iface => $pci_addr" done gpu0_eth => 0000:06:00.0 gpu1_eth => 0000:23:00.0 gpu2_eth => 0000:43:00.0 gpu3_eth => 0000:66:00.0 gpu4_eth => 0000:86:00.0 gpu5_eth => 0000:a3:00.0 gpu6_eth => 0000:c3:00.0 gpu7_eth => 0000:e6:00.0
-
- 使用以下逻辑查找与每个 PCI 地址对应的 bnxt_re# (#=0-7) 设备:
-
for pci in $(find /sys/class/infiniband -type l -exec basename {} \;); do pci_addr=$(readlink -f /sys/class/infiniband/$pci/device | awk -F '/' '{print $NF}') echo "$pci => $pci_addr" |grep bnxt done
示例:
-
root@MI300X-01:/home/jnpr/SCRIPTS# for pci in $(find /sys/class/infiniband -type l -exec basename {} \;); do pci_addr=$(readlink -f /sys/class/infiniband/$pci/device | awk -F '/' '{print $NF}') echo "$pci => $pci_addr" |grep bnxt done bnxt_re5 => 0000:a3:00.0 bnxt_re3 => 0000:66:00.0 bnxt_re1 => 0000:23:00.0 bnxt_re6 => 0000:c3:00.0 bnxt_re4 => 0000:86:00.0 bnxt_re2 => 0000:43:00.0 bnxt_re0 => 0000:06:00.0 bnxt_re7 => 0000:e6:00.0
-
- 映射 GPU 接口 bnxt_re# 或 mlx5_# 接口名称。
组合步骤 1 和 2 的输出以创建从 gpu#_eth 到 bnxt_re# 或 mlx5_# 的完整映射。例如,您可以从输出中看到,gpu0_eth对应于 bnxt_re3 (0000:66:00.0)
您可以使用以下逻辑来简化该过程:
-
echo "GPU-to-NIC Mapping:" for iface in $(ls /sys/class/net | grep -E 'gpu[0-9]+_eth'); do pci_addr=$(readlink -f /sys/class/net/$iface/device | awk -F '/' '{print $NF}') rdma_dev=$(find /sys/class/infiniband -type l -exec basename {} \; | while read rdma; do rdma_pci=$(readlink -f /sys/class/infiniband/$rdma/device | awk -F '/' '{print $NF}') if [[ "$pci_addr" == "$rdma_pci" ]]; then echo "$rdma"; fi done) echo "$iface => $pci_addr => $rdma_dev" done
示例:
-
root@MI300X-01:/home/jnpr/SCRIPTS# echo "GPU-to-NIC Mapping:" for iface in $(ls /sys/class/net | grep -E 'gpu[0-9]+_eth'); do pci_addr=$(readlink -f /sys/class/net/$iface/device | awk -F '/' '{print $NF}') rdma_dev=$(find /sys/class/infiniband -type l -exec basename {} \; | while read rdma; do rdma_pci=$(readlink -f /sys/class/infiniband/$rdma/device | awk -F '/' '{print $NF}') if [[ "$pci_addr" == "$rdma_pci" ]]; then echo "$rdma"; fi done) echo "$iface => $pci_addr => $rdma_dev" done GPU-to-NIC Mapping: gpu0_eth => 0000:06:00.0 => bnxt_re0 gpu1_eth => 0000:23:00.0 => bnxt_re1 gpu2_eth => 0000:43:00.0 => bnxt_re2 gpu3_eth => 0000:66:00.0 => bnxt_re3 gpu4_eth => 0000:86:00.0 => bnxt_re4 gpu5_eth => 0000:a3:00.0 => bnxt_re5 gpu6_eth => 0000:c3:00.0 => bnxt_re6 gpu7_eth => 0000:e6:00.0 => bnxt_re7
为 AMD 服务器(Broadcom 接口)中的 RDMA 配置 DCQN-ECN/PFC 和 TOS/DSCP 流量属性
下表列出了与 DCQN-ECN/PFC 和 TOS/DSCP 相关的一些参数:
表 25.服务器 DCQCN 配置参数
| 参数说明 | 默认 | |
|---|---|---|
| cc_mode | 0 表示 确定性标记 (DCQCN-D) 1 用于 概率标记 (DCQCN-P) |
1 |
| cnp_ecn | 启用/禁用 ECN | 0x1(启用) |
| cnp_dscp | RoCE 拥塞通知数据包的 DSCP 值 | 48 |
| cnp_prio | RoCE 拥塞通知包的优先级 | 7 |
| cnp_ratio_th | 定义生成 CNP 的阈值比率。它决定了响应拥塞而发送的 CNP 速率,从而有助于控制反馈机制的积极性。 | 0x0 |
| ecn_enable | 启用拥塞控制。 | 0x1(启用) |
| ecn_marking | 支持将数据包标记为支持 ECN。ECN = 01 | 0x1(启用) |
| default_roce_mode | 设置 RDMA 的默认 RoCE 模式 | RoCE v2 |
| default_roce_tos | 设置 RDMA 流量的默认 ToS 值 | 104 |
| roce_dscp | RoCE 数据包的 DSCP 值。 | 26 |
| roce_prio | RoCE 数据包的优先级。 | 3 |
| RTT | cnp 和传输数据包计数累积的时间段 (μs)。在 rtt 结束时,计算 CNP 和 TxPkts 之间的比率,并更新 CP。 | 40 微秒。 |
BCM95741X以太网网络适配器支持每个以太网端口的三个传输和接收队列:0、4 和 5。
BCM95750X以太网网络适配器支持每个以太网端口的八个传输和接收队列:0 到 7。
默认情况下,所有队列均配置为加权公平队列 (WFQ),优先级 0 的流量映射到队列 4。
加载 RoCE bnxt_re 驱动程序后,CoSQ 0 配置为无损流量,CoSQ 5 从 WFQ 更改为 CNP 处理的严格优先级 (SP)。
RoCE 和 CNP 流量可以使用不同的 DSCP 值进行标记,也可以改用 VLAN 标记。
默认情况下,ToS 字段设置为 104,这意味着 DSCP 设置为 48,ECN 位设置为 10(启用 ECN)。
这些参数可以使用三种不同的方法进行调整:
- 直接配置 DCQCN/RDMA 标记值
- 使用 Broadcom 工具(例如
niccli,或lldptool直接)配置 DCQCN/RDMA 标记值 - 使用实用程序配置
thebnxt_setupcc.shDCQCN/RDMA 标记值,该实用程序在后台使用或nicclilldptool(默认)。
以下部分介绍使用这些不同选项进行更改的步骤。
-
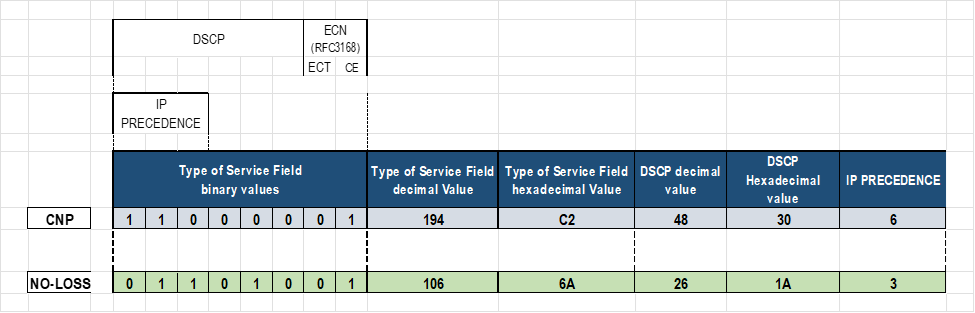
set class-of-service classifiers dscp mydscp forwarding-class CNP loss-priority low code-points 110000 set class-of-service classifiers dscp mydscp forwarding-class NO-LOSS loss-priority low code-points 011010 set class-of-service forwarding-classes class NO-LOSS pfc-priority 3
直接为 RDMA 配置 DCQN-ECN/PFC 和 TOS/DSCP 流量属性
您可以通过直接编辑包含每个参数值的文件来更改 DCQCN 和流量标记。此方法是最简单的,不需要安装任何额外的工具。但是,它不是 PFC 相关参数的选项,也不是所有类型的网络适配器都支持它。
要为特定接口完成这些更改,您必须在相应的接口目录中,按照以下步骤作:
- 为 QoS 相关值创建接口目录
我们确定了 gpu#_eth 接口与相应的 Broadcom 接口名称之间的映射
GPU 到 NIC 映射:
gpu0_eth => 0000:06:00.0 => bnxt_re0
gpu1_eth => 0000:23:00.0 => bnxt_re1
gpu2_eth => 0000:43:00.0 => bnxt_re2
gpu3_eth => 0000:66:00.0 => bnxt_re3
gpu4_eth => 0000:86:00.0 => bnxt_re4
gpu5_eth => 0000:a3:00.0 => bnxt_re5
gpu6_eth => 0000:c3:00.0 => bnxt_re6
gpu7_eth => 0000:e6:00.0 => bnxt_re7
我们将使用 Broadcom 接口名称创建目录(rdma_cm 和 bnxt_re),其中 DCQCN 属性以及每个接口的其他参数和统计信息将在这里。
接口特定目录在使用以下命令创建之前不存在:
-
cd /sys/kernel/config mkdir -p /rdma_cm/<Broadcom-interface-name> mkdir -p /bnxt_re/<Broadcom-interface-name>
请注意,这两个目录必须存在。
-
root@MI300X-01:/# cd /sys/kernel/config/ls bnxt_re rdma_cm
例如,如果缺少rdma_cm目录,请尝试以下作:
-
root@MI300X-01:/sys/kernel/config# sudo modprobe rdma_cm root@MI300X-01:/sys/kernel/config# lsmod | grep rdma_cm rdma_cm 147456 0 iw_cm 61440 1 rdma_cm ib_cm 151552 1 rdma_cm ib_core 507904 6 rdma_cm,iw_cm,bnxt_re,ib_uverbs,mlx5_ib,ib_cm
示例:
-
root@MI300X-01:/# cd /sys/kernel/config/bnxt_re root@MI300X-01:/sys/kernel/config/bnxt_re# (NO FILES LISTED) root@MI300X-01:/# cd /sys/kernel/config/rdma_cm root@MI300X-01:/sys/kernel/config/rdma_cm# ls (NO FILES LISTED) root@MI300X-01:/sys/kernel/config# mkdir -p rdma_cm/bnxt_re0 root@MI300X-01:/sys/kernel/config# mkdir -p bnxt_re/bnxt_re0 root@MI300X-01:/sys/kernel/config# ls rdma_cm bnxt_re0 root@MI300X-01:/sys/kernel/config# ls bnxt_re bnxt_re0 root@MI300X-01:/sys/kernel/config# mkdir -p rdma_cm/bnxt_re1 root@MI300X-01:/sys/kernel/config# mkdir -p bnxt_re/bnxt_re1 root@MI300X-01:/sys/kernel/config# ls rdma_cm bnxt_re0 bnxt_re1 root@MI300X-01:/sys/kernel/config# ls bnxt_re bnxt_re0 bnxt_re1
对所有 GPU 接口重复这些步骤。
注意:您必须是 root 用户才能进行这些更改。-
jnpr@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc$ sudo echo -n 0x1 > ecn_enable -bash: ecn_enable: Permission denied. jnpr@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc$ sudo bash root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# sudo echo -n 0x1 > ecn_enable root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc#
新目录将包含与 ECN、ROCE 流量和其他函数相关的值:
-
root@MI300X-01:/sys/kernel/config# cd rdma_cm/bnxt_re0/ports/1 root@MI300X-01:/sys/kernel/config/rdma_cm/bnxt_re0/ports/1# ls default_roce_mode default_roce_tos root@MI300X-01:/sys/kernel/config/rdma_cm/bnxt_re0/ports/1# cd /sys/kernel/config/bnxt_re/bnxt_re0/ports/1 root@MI300X-02:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1$ ls cc tunables root@MI300X-02:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1$ ls tunables acc_tx_path cq_coal_en_ring_idle_mode dbr_pacing_algo_threshold en_qp_dbg snapdump_dbg_lvl user_dbr_drop_recov_timeout cq_coal_buf_maxtime cq_coal_normal_maxbuf dbr_pacing_enable gsi_qp_mode stats_query_sec cq_coal_during_maxbuf dbr_def_do_pacing dbr_pacing_time min_tx_depth user_dbr_drop_recov root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/# ls cc abs_max_quota act_cr_factor act_rel_cr_th actual_cr_shift_correction_en advanced ai_rate_incr ai_rtt_th1 ai_rtt_th2 apply bw_avg_weight cc_ack_bytes cc_mode cf_rtt_th cnp_dscp cnp_ecn cnp_prio cnp_ratio_th cp_bias cp_bias_en cp_exp_update_th cr_min_th cr_prob_fac cr_width disable_prio_vlan_tx ecn_enable ecn_marking exp_ai_rtts exp_crcp_ratio fair_cr_th fr_num_rtts g inact_th init_cp init_cr init_tr l64B_per_rtt lbytes_per_usec max_cp_cr_th max_quota min_quota min_time_bet_cnp random_no_red_en red_div red_rel_rtts_th reduce_cf_rtt_th reset_cc_cr_th roce_dscp roce_prio rt_en rtt rtt_jitter_en sc_cr_th1 sc_cr_th2 tr_lb tr_prob_fac tr_update_cyls tr_update_mode
您可以在目录中找到
/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc#其中一些参数的描述,以及它们的当前值cat to apply。示例:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat apply ecn status (ecn_enable) : Enabled ecn marking (ecn_marking) : ECT(1) congestion control mode (cc_mode) : DCQCN-P send priority vlan (VLAN 0) : Disabled running avg. weight(g) : 8 inactivity threshold (inact_th) : 10000 usec initial current rate (init_cr) : 0xc8 initial target rate (init_tr) : 0x320 cnp header ecn status (cnp_ecn) : ECT(1) rtt jitter (rtt_jitter_en) : Enabled link bytes per usec (lbytes_per_usec) : 0x7fff byte/usec current rate width (cr_width) : 0xe bits minimum quota period (min_quota) : 0x4 maximum quota period (max_quota) : 0x7 absolute maximum quota period(abs_max_quota) : 0xff 64B transmitted in one rtt (l64B_per_rtt) : 0xf460 roce prio (roce_prio) : 3 roce dscp (roce_dscp) : 26 cnp prio (cnp_prio) : 7 cnp dscp (cnp_dscp) : 48
-
- 启用 RoCEv2作。
即使 RoCEv2 应为默认模式,此处显示了启用 RoCEv2 的命令。
注意:此更改是在 rdma_cm 目录下进行的-
root@MI300X-01:/# cd /sys/kernel/config/rdma_cm/bnxt_re0/ports/1 root@MI300X-01:/sys/kernel/config/rdma_cm/bnxt_re0/ports/1# ls default_roce_mode default_roce_tos root@MI300X-01:/sys/kernel/config/rdma_cm/bnxt_re0/ports/1# echo RoCE v2 > default_roce_mode
注意:输入完全如图所示的值,包括空格:“RoCE v2”(区分大小写)。设置参数后,应用新值,如下所示:
-
echo -n 0x1 > apply
验证更改:
-
root@MI300X-01:/sys/kernel/config/rdma_cm/bnxt_re1/ports/1# cat default_roce_mode RoCE v2
-
-
启用 ECN 响应和通知功能。
尽管默认情况下应启用 ECN,但此处显示了启用 ECN 的命令。root@MI300X-01:/# cd /sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# echo -n 0x1 > ecn_enable
echo -n 0x0 > ecn_enable
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# echo -n 0x1 > ecn_enable
在 Broadcom 接口上启用 ECN 后,它们将响应 CNP 数据包 (RP),并在收到带有 ECN 标记的接口 (NP) 时生成 CNP 数据包。
要禁用它,请输入 echo -n 0x0 > cnp_ecn 。
设置参数后,应用新值:
-
echo -n 0x1 > apply
验证更改:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat ecn_enable 0x1
您还可以将 CNP 和 ROCE 数据包标记为 ECN 合格(这意味着,当发生拥塞时,这些数据包可以通过网络进行标记)。
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat cnp_ecn 0x1
总结这些属性:
| ecn_enable | 启用/禁用 ECN 的 RP(响应点)端。它使设备能够响应 CNP 数据包。默认值 = 1(启用) |
| cnp_ecn | 将标记为 CNP 数据包符合 ECN 条件。ECT 字段的值为 01 或 10。 |
| ecn_marking | 将 ROCE 数据包标记为 ECN 合格。ECT 字段的值为 01 或 10。 |
- 为 CNP 和 RoCEv2 数据包配置 DSCP 和 PRIO 值。
注意:并非所有类型的 Broadcom 接口卡都可以通过手动配置这些值(如下所示)。例如,对于 BCM95741X 设备,您可以使用此方法配置 ECN 和 RoCE 优先级值,但在 BCM95750X/BCM957608 设备上,您可以配置
roce_dscp, ecn_dscp
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# echo -n 0x30 > cnp_dscp # DSCP value as 48 (30 in HEX)
注意:这些更改是在 bnxt_re0 目录下进行的。-
echo -n 0x1a > roce_dscp # DSCP value as 26 (1a in HEX) echo -n 0x7 > cnp_prio echo -n 0x3 > roce_prio
注意:以下错误表示不支持直接更改此参数的值。如果是BCM957608 roce_prio,并且需要使用(后文所述)进行bnxt_setupcc.sh配置cnp_prio。-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# echo -n 0x3 > roce_prio bash: echo: write error: Invalid argument
设置参数后,应用新值:
-
echo -n 0x1 > apply
验证更改:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat cnp_dscp 0x30 root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat cnp_dscp 0x1a root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat cnp_prio 0x7 root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat cnp_prio 0x3
-
- 配置 DCQCN 算法(在 bnxt_re 目录下)。
Broadcom 以太网网络适配器中的默认 DCQCN 拥塞控制(cc 模式)算法是 DCQCN-P。可以使用以下命令更改模式:
注意:此更改是在 bnxt_re0 目录下进行的。要使用 DCQCN-P ,请配置:
-
cd /sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc/ echo -n 1 > cc_mode echo -n 1 > apply cat apply
要使用 DCQCN-D ,请配置:
-
root@MI300X-01:/ cd /sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc/ echo -n 0 > cc_mode echo -n 1 > apply
-
- 检查已配置的所有属性。
以下命令显示所有接口参数:
-
root@MI300X-01:/ cd /sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc/ echo -n 1 > advanced echo -n 1 > apply cat apply
有关 Broadcom 以太网网络适配器中 DCQCN 算法的详细信息,请查看以下文档: 更改拥塞控制模式设置 和 RoCE 拥塞控制
示例:
我们强调了一些 ECN/CNP 相关参数:
-
root@MI300X-01:/sys/kernel/config# cd /sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc/ echo -n 1 > advanced echo -n 1 > apply cat apply ecn status (cnp_ecn) : Enabled ecn marking (ecn_marking) : ECT(1) congestion control mode (cc_mode) : DCQCN-P send priority vlan (VLAN 0) : Disabled running avg. weight(g) : 8 inactivity threshold (inact_th) : 10000 usec initial current rate (init_cr) : 0xc8 initial target rate (init_tr) : 0x320 round trip time (rtt) : 45 usec cnp header ecn status (cnp_ecn) : ECT(1) rtt jitter (rtt_jitter_en) : Enabled link bytes per usec (lbytes_per_usec) : 0x7fff byte/usec current rate width (cr_width) : 0xe bits minimum quota period (min_quota) : 0x4 maximum quota period (max_quota) : 0x7 absolute maximum quota period(abs_max_quota) : 0xff 64B transmitted in one rtt (l64B_per_rtt) : 0xf460 minimum time between cnps (min_time_bet_cnp) : 0x0 usec initial congestion probability (init_cp) : 0x3ff target rate update mode (tr_update_mode) : 1 target rate update cycle (tr_update_cyls) : 0x0 fast recovery rtt (fr_num_rtts) : 0x5 rtts active increase time quanta (ai_rate_incr) : 0x1 reduc. relax rtt threshold (red_rel_rtts_th) : 0x2 rtts additional relax cr rtt (act_rel_cr_th) : 0x50 rtts minimum current rate threshold (cr_min_th) : 0x0 bandwidth weight (bw_avg_weight) : 0x5 actual current rate factor (act_cr_factor) : 0x0 current rate level to max cp (max_cp_cr_th) : 0x3ff cp bias state (cp_bias_en) : Disabled log of cr fraction added to cp (cp_bias) : 0x3 cr threshold to reset cc (reset_cc_cr_th) : 0x32a target rate lower bound (tr_lb) : 0x1 current rate probability factor (cr_prob_fac) : 0x3 target rate probability factor (tr_prob_fac) : 0x5 current rate fairness threshold (fair_cr_th) : 0x64 reduction divider (red_div) : 0x1 rate reduction threshold (cnp_ratio_th) : 0x0 cnps extended no congestion rtts (exp_ai_rtts) : 0x8 rtt log of cp to cr ratio (exp_crcp_ratio) : 0x7 use lower rate table entries (rt_en) : Disabled rtts to start cp track cr (cp_exp_update_th) : 0x1a4 rtt first threshold to rise ai (ai_rtt_th1) : 0x40 rtt second threshold to rise ai (ai_rtt_th2) : 0x80 rtt actual rate base reduction threshold (cf_rtt_th) : 0x15e rtt first severe cong. cr threshold (sc_cr_th1) : 0x0 second severe cong. cr threshold (sc_cr_th2) : 0x0 cc ack bytes (cc_ack_bytes) : 0x44 reduce to init rtts threshold(reduce_cf_rtt_th) : 0x3eb rtt random no reduction of cr (random_no_red_en) : Enabled actual cr shift correction (actual_cr_shift_correction_en) : Enabled roce prio (roce_prio) : 3 roce dscp (roce_dscp) : 26 cnp prio (cnp_prio) : 7 cnp dscp (cnp_dscp) : 0
使用 niccli 为 RDMA 配置 DCQN-ECN/PFC 和 TOS/DSCP 流量属性
您可以使用 NICCLI 配置实用程序对 DCQCN 和流量标记进行更改。
niccli是 Broadcom 以太网网络适配器的管理工具,可提供详细信息,包括类型、状态、序列号和固件版本。此外,它支持配置接口属性,如 DCQCN-ECN、PFC 和 TOS/DSCP,以优化 RDMA 流量。
-
root@MI300X-01:/$ which niccli /usr/bin/niccli root@MI300X-01:/usr/bin$ ls niccli -l lrwxrwxrwx 1 18896 1381 18 Sep 25 18:52 niccli -> /opt/niccli/niccli
您可以使用以下示例所示获取可通过服务器 niccli listdev, or list-eth 上的 niccli 进行管理的接口适配器和以太网端口的摘要。
-
root@MI300X-01:/home/jnpr# niccli --listdev 1 ) Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller (Adp#1 Port#1) Device Interface Name : gpu0_eth MAC Address : 7C:C2:55:BD:75:D0 PCI Address : 0000:06:00.0 2 ) Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller (Adp#2 Port#1) Device Interface Name : gpu1_eth MAC Address : 7C:C2:55:BD:79:20 PCI Address : 0000:23:00.0 3 ) Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller (Adp#3 Port#1) Device Interface Name : gpu2_eth MAC Address : 7C:C2:55:BD:7D:F0 PCI Address : 0000:43:00.0 4 ) Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller (Adp#4 Port#1) Device Interface Name : gpu3_eth MAC Address : 7C:C2:55:BD:7E:20 PCI Address : 0000:66:00.0 5 ) Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller (Adp#5 Port#1) Device Interface Name : gpu4_eth MAC Address : 7C:C2:55:BD:75:10 PCI Address : 0000:86:00.0 6 ) Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller (Adp#6 Port#1) Device Interface Name : gpu5_eth MAC Address : 7C:C2:55:BD:7D:C0 PCI Address : 0000:A3:00.0 7 ) Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller (Adp#7 Port#1) Device Interface Name : gpu6_eth MAC Address : 7C:C2:55:BD:84:90 PCI Address : 0000:C3:00.0 8 ) Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller (Adp#8 Port#1) Device Interface Name : gpu7_eth MAC Address : 7C:C2:55:BD:83:10 PCI Address : 0000:E6:00.0 root@MI300X-01:/home/jnpr# niccli --list-eth BoardId Interface PCIAddr 1) BCM957608 gpu0_eth 0000:06:00.0 2) BCM957608 gpu1_eth 0000:23:00.0 3) BCM957608 gpu2_eth 0000:43:00.0 4) BCM957608 gpu3_eth 0000:66:00.0 5) BCM957608 gpu4_eth 0000:86:00.0 6) BCM957608 gpu5_eth 0000:A3:00.0 7) BCM957608 gpu6_eth 0000:C3:00.0 8) BCM957608 gpu7_eth 0000:E6:00.0
您可以在单行模式、交互模式或批处理模式下使用niccli。提供了niccli -h help这些模式的高级说明。在本节中,我们将展示一些示例,说明如何使用单线和交互模式进行 DCQCN-ECN、PFC 和 TOS/DSCP 配置。
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# niccli --help ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- NIC CLI - Help Option --help / -h Displays the following help page. Utility provides three modes of execution, 1. Interactive Mode To launch in interactive mode : <NIC CLI executable> [-i <index of the target>] | -pci <NIC pci address> After launching in interactive mode, execute 'help' command to display the list of available commands. 2. Oneline Mode To launch in Oneline mode : <NIC CLI executable> [-i <index of the target>] | -pci <NIC pci address> <command> To list available commands in Oneline mode : <NIC CLI executable> [-i <index of the target>] | -pci <NIC pci address> help Legacy Nic command syntax : To launch in Oneline mode : <NIC CLI executable> [-dev [<index of the target> | <mac addr> | <NIC pci address>]] <command> To list available commands in Oneline mode : <NIC CLI executable> [-dev [<index of the target> | <mac addr> | <NIC pci address>]] help 3. Batch Mode To launch in batch mode : <NIC CLI executable> [-i <index of the target>] | -pci <NIC pci address> --batch <batch file> NOTE: Batch mode requires flat text file with utility supported commands. Commands have to be provided in ascii format with the valid parameters. Supported commands can be listed using One-Line mode or Interactive mode Upon failure of any commands, utility will exit without continuing with other commands List available targets for Oneline or Batch mode <NIC CLI executable> --list <NIC CLI executable> --listdev
在没有选项的情况下进入允许您 niccli 在交互模式下工作,您可以在其中选择适配器/接口(按索引),然后选择适当的 <command> 适配器/接口(例如,显示、get_qos、set_map)以获取信息或对所选接口进行更改。
您可以使用将 Broadcom 接口名称与逻辑接口名称进行映射 一节中所述的方法来识别与每个接口对应的接口索引。这将为您提供接口和 pcie 地址之间的映射,然后您可以将其与下面的输出 niccli 相关联。
确定后,输入接口索引(输出中的第一列),如以下示例所示。
示例:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# niccli ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------ BoardId MAC Address FwVersion PCIAddr Type Mode 1) BCM957608 7C:C2:55:BD:75:D0 230.2.49.0 0000:06:00.0 NIC PCI 2) BCM957608 7C:C2:55:BD:79:20 230.2.49.0 0000:23:00.0 NIC PCI 3) BCM957608 7C:C2:55:BD:7D:F0 230.2.49.0 0000:43:00.0 NIC PCI 4) BCM957608 7C:C2:55:BD:7E:20 230.2.49.0 0000:66:00.0 NIC PCI 5) BCM957608 7C:C2:55:BD:75:10 230.2.49.0 0000:86:00.0 NIC PCI 6) BCM957608 7C:C2:55:BD:7D:C0 230.2.49.0 0000:A3:00.0 NIC PCI 7) BCM957608 7C:C2:55:BD:84:90 230.2.49.0 0000:C3:00.0 NIC PCI 8) BCM957608 7C:C2:55:BD:83:10 230.2.49.0 0000:E6:00.0 NIC PCI Enter the target index to connect with : 1 BCM957608> Once you are at the prompt for the selected NIC, you can enter commands such asshow, device_health_check, listdev,andlisteth) BCM957608> show NIC State : Up Device Type : THOR2 PCI Vendor ID : 0x14E4 PCI Device ID : 0x1760 PCI Revision ID : 0x11 PCI Subsys Vendor ID : 0x15D9 PCI Subsys Device ID : 0x1D42 Device Interface Name : gpu0_eth MAC Address : 7C:C2:55:BD:75:D0 Base MAC Address : 7C:C2:55:BD:75:D0 Serial Number : OA248S074777 Part Number : AOC-S400G-B1C PCI Address : 0000:06:00.0 Chip Number : BCM957608 Chip Name : THOR2 Description : Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller ---more--- BCM957608> devid Device Interface Name : gpu0_eth PCI Vendor ID : 0x14E4 PCI Device ID : 0x1760 PCI Revision ID : 0x11 PCI Subsys Vendor ID : 0x15D9 PCI Subsys Device ID : 0x1D42 PCI Address : 0000:06:00.0 BCM957608> device_health_check Device Health Information : SBI Mismatch Check : OK SBI Booted Check : OK SRT Mismatch Check : OK SRT Booted Check : OK CRT Mismatch Check : OK CRT Booted Check : OK Second RT Image : CRT Image Second RT Image Redundancy : Good Image Fastbooted Check : OK Directory Header Booted Check : OK Directory Header Mismatch Check : OK MBR Corrupt Check : OK NVM Configuration : OK FRU Configuration : OK --------------------------------------------- Overall Device Health : Healthy BCM957608> devid Device Interface Name : gpu0_eth PCI Vendor ID : 0x14E4 PCI Device ID : 0x1760 PCI Revision ID : 0x11 PCI Subsys Vendor ID : 0x15D9 PCI Subsys Device ID : 0x1D42 PCI Address : 0000:06:00.0
niccli -i <interface-index> <command>
niccli -list 命令可用于确定接口索引。
示例
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# niccli --list ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- BoardId MAC Address FwVersion PCIAddr Type Mode 1) BCM957608 7C:C2:55:BD:75:D0 230.2.49.0 0000:06:00.0 NIC PCI 2) BCM957608 7C:C2:55:BD:79:20 230.2.49.0 0000:23:00.0 NIC PCI 3) BCM957608 7C:C2:55:BD:7D:F0 230.2.49.0 0000:43:00.0 NIC PCI 4) BCM957608 7C:C2:55:BD:7E:20 230.2.49.0 0000:66:00.0 NIC PCI 5) BCM957608 7C:C2:55:BD:75:10 230.2.49.0 0000:86:00.0 NIC PCI 6) BCM957608 7C:C2:55:BD:7D:C0 230.2.49.0 0000:A3:00.0 NIC PCI 7) BCM957608 7C:C2:55:BD:84:90 230.2.49.0 0000:C3:00.0 NIC PCI 8) BCM957608 7C:C2:55:BD:83:10 230.2.49.0 0000:E6:00.0 NIC PCI
提供了 sudo niccli help 可用于交互式和单行模式的命令和选项的广泛列表。
-
root@MI300X-01:/home/jnpr# sudo niccli help ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- Commands sets - Generic/Offline ------------------------------------------------------------------------------- list - Lists all the compatible devices listdev - Lists all the compatible devices (NIC legacy syntax) devid - Query Broadcom device id's. pkgver - Display FW PKG version installed on the device. verify - Verify FW packages & NVM nvm-list - Display NVM components and its associated versions. nvmview - View NVM directories data list-eth - Lists all NIC devices with ethernet interface names help - Lists the available commands quit - Quits from the application Commands for platform 'BCM57xxx Performance NIC' and interface 'Direct PCIe' ------------------------------------------------------------------------------- show - Shows NIC specific device information coredump - Retrieves coredump data from device. snapdump - Retrieves snapdump data from device. version - Display the current version of the application txfir - Network Interface Card Transmission Finite - Impulse Response msixmv - Display and configure the number of MSIX max - vectors values for VF's per each PF scan - Scan PCI devices in the topology pcie - Show/Execute pcie operation nvm - NVRAM Option Management pfalloc - Configure and Query for the number of PFs per PCIe - endpoint rfd - Restores NVM configuration to factory defaults backuppowercfg - Backup Power Configuration tsio - TSIO function capability on the pin ingressqos - Query and configure the ingressqos parameters egressqos - Query and configure the egressqos parameters dutycycle - Set duty cycle on TSIO outgoing signal dllsource - Set the DLL source for PHC vf - Configure and Query for a trusted VF rxportrlmt - Configure the receive side port rate limit rxrlmt - Query the configured receive side rate control parameters rxeprlmt - Configure the receive side rate control parameters for a given endpoint txpartitionrlmt - Query and Configure the transmit side partition rate limit applies to traffic - sent from a partition, which is one PF and all of its child VFs txportrlmt - Query and Configure the transmit side of port rate limit txeprlmt - Query and Configure the PCIe endpoint transmit rate control vf - Configure and Query for a trusted VF pfc - Configure the priority-based flow control for a given priority apptlv - Configure the priority for the AppTLV tcrlmt - Configure the rate limit for each traffic class ets - Configure the enhanced transmission selection, priority to traffic class and bandwidths up2tc - Configure the user priorities to traffic classes getqos - Query the configured enhanced transmission selection, priority to traffic class and bandwidths listmap - List the priority to traffic class and queueid mapping dscp2prio - Query the dscp to priority mapping reset - Reset the device synce - Configure the synchronous ethernet profile dscdump - Retrieves dscdump for device ptp - PTP extended parameters operation prbs_test - Run PRBS loopback test serdes - Plots the serdes pci and ethernet eye and prints the horizontal and vertical margin values Legacy NVM commands : - Query commands --------------------- - --------------- device_info - Query Broadcom device information and default hardware - resources profile version. device_temperature - Query the device temperature in Celsius. get_backup_power_config - Query backup power configuration of the device. moduleinfo - Query the PHY module information. nvm_measurement - Query the active NVM configuration. get_ptp_extended - Query the PTP extended parameters. getoption - Query current NVM configuration option settings - of a device. pcie_counters - Display the pcie counters. saveoptions - Save NVM configuration options on the device - to a file. get_sync_ethernet - Get the synchronous ethernet frequency profile get_txfir - Query the TX FIR settings. cert_provision_state - Query the imported certificate chain on the device. read - Read the NVM item data and write its contents to a file. mh_pf_alloc - Query the number of PFs per PCIe endpoint. - This command is supported only on Thor devices. get_tsio_function_pin - Query TSIO function capability on the pin. Legacy NVM commands : - Debug commands --------------------- - --------------- device_health_check - Checks the device health. backup - Backup NVM contents to a file Legacy NVM commands : - Configuration commands --------------------- - --------------- reset_ap - Reset management processor. setoption - Configure NVM configuration option settings - of a device. msix_max_vectors - Configure the number of MSI-X max vectors per - VF for each PF. loopback - Query/perform loopback config. add_ntuple_filter - Add ntuple flow filter. free_ntuple_filter - Free ntuple flow filter. cfgtunnel - query/config custom tunnel port/rss. write - Create or overwrite NVM data item with a file. set_txfir - Configures the TX FIR settings set_ptp_extended - Set PTP extended parameters mh_pf_alloc - Query/Configure the number of PFs per PCIe endpoint. - This command is supported only on Thor devices. restore_factory_defaults - Restores NVM configuration to factory defaults resmgmt - Query and Configure resources of the device. Legacy NVM commands : - FW update commands --------------------- - --------------- fw_sync - Synchronize primary & secondary FW images livepatch - Query, Activate and Deactivate the patch in live install - Install/Update FW Legacy QoS Rx commands : - Rx Qos commands --------------------- - --------------- rx_port_ratelimit - The user can configure rx rate control that applies to all traffic in a rx CoS queue group. rx_endpoint_ratelimit - The user can configure endpoint rx rate control that applies to all traffic in a rx CoS queue group. get_rx_ratelimits - The user can query the rx rate limits. Legacy QoS Tx commands : - Tx Qos commands --------------------- - --------------- partition_tx_ratelimit - This command is used to configure partition tx rate limit. get_partition_tx_ratelimit - This command is used to query the partition rate limit configuration for a given partition. get_tx_port_ratelimit - This command is used to query the tx side of port rate limit. tx_port_ratelimit - This command is used to configure the tx side of port rate limit tx_endpoint_ratelimit - This command is used to configure PCIe endpoint tx rate limit. get_tx_endpoint_ratelimits - This command is used to query the tx endpoint rate limits. Legacy DCB commands : - Data Center Bridging commands --------------------- - --------------- set_pfc - This command is used to enable PFC on a given priority set_apptlv - This command is used to configure the priority of the AppTLV. ratelimit - This command is used to configure the rate limit for each traffic class. set_ets - This command is used to configure the DCB parameters. set_map - This command is used to configure the priority to traffic class. get_qos - This command is used to query the DCB parameters. dump - This command is used to dump the priority to cos mapping. get_dscp2prio - This command is used to query the dscp to priority mapping.
以下示例说明如何使用 niccli 来获取有关特定接口的信息。
- 检查接口状态。
提供
niccli -i <interface> show有关接口的详细信息,例如类型、MAC 地址、固件、序列号、设备运行状况、温度等。示例:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# sudo niccli -i 1 show ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- NIC State : Up Device Type : THOR2 PCI Vendor ID : 0x14E4 PCI Device ID : 0x1760 PCI Revision ID : 0x11 PCI Subsys Vendor ID : 0x15D9 PCI Subsys Device ID : 0x1D42 Device Interface Name : gpu0_eth MAC Address : 7C:C2:55:BD:75:D0 Base MAC Address : 7C:C2:55:BD:75:D0 Serial Number : OA248S074777 Part Number : AOC-S400G-B1C PCI Address : 0000:06:00.0 Chip Number : BCM957608 Chip Name : THOR2 Description : Supermicro PCIe 400Gb Single port QSFP56-DD Ethernet Controller Firmware Name : PRIMATE_FW Firmware Version : 230.2.49.0 RoCE Firmware Version : 230.2.49.0 HWRM Interface Spec : 1.10.3 Kong mailbox channel : Not Applicable Active Package Version : 230.2.52.0 Package Version on NVM : 230.2.52.0 Active NVM config version : 0.0.5 NVM config version : 0.0.5 Reboot Required : No Firmware Reset Counter : 0 Error Recovery Counter : 0 Crash Dump Timestamp : Not Available Secure Boot : Enabled Secure Firmware Update : Enabled FW Image Status : Operational Crash Dump Available in DDR : No Device Temperature : 57 Celsius PHY Temperature : Not Available Optical Module Temperature : 65 Celsius Device Health : Good
-
- 检查 QoS 设置
sudo niccli -i <interface-index> dscp2prio and sudo niccli -i 1 listmap -pri2cos
-
root@MI300X-01:/home/jnpr# sudo niccli -i 1 dscp2prio ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- dscp2prio mapping: priority:7 dscp: 48 priority:3 dscp: 26 root@MI300X-01:/home/jnpr# sudo niccli -i 2 listmap -pri2cos ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- Base Queue is 0 for port 0 ---------------------------- Priority TC Queue ID ------------------------ 0 0 4 1 0 4 2 0 4 3 1 0 4 0 4 5 0 4 6 0 4 7 2 5
示例中的输出显示以下默认设置:
- 队列状态。仅启用队列 0、1 和 2。
- 优先级到 DSCP 的映射:优先级 7 = > DSCP 48 和优先级 3 => DSCP 26。
- TC(流量类)和队列映射的优先级:优先级 7 => TC2(队列 0)=> DSCP 48 和优先级 3 => TC1(队列 5)=> DSCP 26。
该 sudo niccli -i <interface-index> get_qos 命令提供接口上 QoS 配置的摘要。
示例:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# sudo niccli -i 1 get_qos ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- IEEE 8021QAZ ETS Configuration TLV: PRIO_MAP: 0:0 1:0 2:0 3:1 4:0 5:0 6:0 7:2 TC Bandwidth: 50% 50% 0% TSA_MAP: 0:ets 1:ets 2:strict IEEE 8021QAZ PFC TLV: PFC enabled: 3 IEEE 8021QAZ APP TLV: APP#0: Priority: 7 Sel: 5 DSCP: 48 APP#1: Priority: 3 Sel: 5 DSCP: 26 APP#2: Priority: 3 Sel: 3 UDP or DCCP: 4791 TC Rate Limit: 100% 100% 100% 0% 0% 0% 0% 0%
| IEEE 802.1Qaz ETS 配置 TLV:显示增强型传输选择 (ETS) 配置 | |
|---|---|
| PRIO_MAP:0:0 1:0 2:0 3:1 4:0 5:0 6:0 7:2 | 将优先级映射到流量类 (TC) 优先级 0、1、2、4、5、6 → TC 0 优先级 3 → TC 1 优先级 7 → TC 2 |
| TC 带宽:50% 50% 0% | 为流量类别分配带宽百分比。 TC 0:占总带宽的 50%。 TC 1:50%。 TC 2:0%。 |
| TSA_MAP:0:ets 1:ets 2:严格 | TSA_MAP 与 TC Bandwidth 一起为每个 TC 分配资源并定义服务优先级。相当于 Junos 中的调度器和调度器映射。 指定用于每个 TC 的传输选择算法 (TSA): TC 0 和 TC 1 使用 ETS(增强型传输选择) 并按 50/50 共享可用带宽 TC 2 使用严格优先级,这意味着 TC 2 流量将始终首先发送 |
| IEEE 802.1Qaz PFC TLV:使用 APP TLV(类型-长度-值)格式定义流量分类 | |
| 启用 PFC:3 | 指示在优先级 3 上启用 PFC。 其他优先级未启用 PFC。 PFC 可确保具有此优先级的流量可以暂停,而不是在拥塞期间被丢弃。 |
| IEEE 802.1Qaz APP TLV | |
| 应用#0: 优先级:7 选:5 DSCP:48 应用#1: 优先级:3 选:5 DSCP:26 应用#2: 优先级:3 选:3 UDP 或 DCCP:4791 |
将流量映射到流量类。等效于 Junos 中的多域分类器。 APP#0:标有 DSCP = 48 的流量映射到优先级 7 APP#1:标记为 DSCP = 48 的流量映射到优先级 3 APP#2:端口 = 4791 (RoCEv2) 的 UDP 或 DCCP 流量映射到优先级 3 |
| TC 速率限制:100% 100% 100% 0% 0% 0% 0% 0% | TC 0、TC 1 和 TC 2 最多可使用 100% 的带宽。 TC 3 到 TC 7 设置为 0%,表示当前未将其配置为传输流量。 |
如果需要,将优先级更改为流量类别映射或将应用更改为流量类别映射。
我们建议保留默认设置,并确保它们与 GPU 后端交换矩阵中叶节点上的服务等级配置一致。
-
[edit class-of-service classifiers] jnpr@gpu-backend-rack1-001-leaf1# show dscp mydscp { forwarding-class CNP { loss-priority low code-points 110000; <= DSCP = 48 } forwarding-class NO-LOSS { loss-priority low code-points 011010; <= DSCP = 26 } } } [edit class-of-service forwarding-classes] jnpr@gpu-backend-rack1-001-leaf1# show class CNP queue-num 3; class NO-LOSS queue-num 4 no-loss pfc-priority 3;
如果需要更改流量类映射的优先级或流量类映射的应用程序,可以使用以下命令:
优先级到流量类映射
-
BCM957608> help up2tc DESCRIPTION : This command is used to set the user priorities to traffic classes. SYNTAX : up2tc -p <priority[0-7]:tc>, ...> -p: Comma separated list mapping user priorities to traffic classes.
示例:
-
BCM957608> sudo niccli -i 1 get_qos ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- IEEE 8021QAZ ETS Configuration TLV: PRIO_MAP: 0:1 1:1 2:0 3:0 4:1 5:1 6:0 7:0 <= default ---more--- BCM957608> up2tc -p 0:0,1:0,2:1,3:1,4:1,5:1,6:1,7:0 User priority to traffic classes are configured successfully. BCM957608> sudo niccli -i 1 get_qos ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- IEEE 8021QAZ ETS Configuration TLV: PRIO_MAP: 0:0 1:0 2:1 3:1 4:1 5:1 6:1 7:0 ---more---
应用到流量类别的映射
-
BCM957608> help apptlv DESCRIPTION : This command is used to configure the priority of the AppTLV SYNTAX : apptlv -add -app <priority,selector,protocol> apptlv -del -app <priority,selector,protocol>
示例:
-
BCM957608> sudo niccli -i 1 get_qos ---more--- IEEE 8021QAZ APP TLV: APP#1: Priority: 7 Sel: 5 DSCP: 48 APP#2: Priority: 3 Sel: 5 DSCP: 26 APP#3: Priority: 3 Sel: 3 UDP or DCCP: 4791 BCM957608> apptlv -add -app 5,1,35093 AppTLV configured successfully. BCM957608> sudo niccli -i 1 get_qos ---more--- IEEE 8021QAZ APP TLV: APP#0: Priority: 5 Sel: 1 Ethertype: 0x8915 APP#1: Priority: 7 Sel: 5 DSCP: 48 APP#2: Priority: 3 Sel: 5 DSCP: 26 APP#3: Priority: 3 Sel: 3 UDP or DCCP: 4791 BCM957608> BCM957608> apptlv -del -app 5,1,35093 AppTLV deleted successfully. BCM957608> sudo niccli -i 1 get_qos ---more--- IEEE 8021QAZ APP TLV: APP#0: Priority: 7 Sel: 5 DSCP: 48 APP#1: Priority: 3 Sel: 5 DSCP: 26 APP#2: Priority: 3 Sel: 3 UDP or DCCP: 4791 ---more---
如果需要,请更改 ETS 配置属性。
我们建议保留默认设置,并确保它们与 GPU 后端交换矩阵中叶节点上的服务等级配置一致。
-
[edit class-of-service forwarding-classes] jnpr@gpu-backend-rack1-001-leaf1# show class CNP queue-num 3; class NO-LOSS queue-num 4 no-loss pfc-priority 3; BCM957608> help ets DESCRIPTION : This command is used to configure the enhanced transmission selection, priority to traffic class and traffic class bandwidths. SYNTAX : ets -tsa <tc[0-7]:[ets|strict], ...> -up2tc <priority[0-7]:tc>, ...> -tcbw <list> -tsa: Transmission selection algorithm, sets a comma separated list of traffic classes to the corresponding selection algorithm. Valid algorithms include "ets" and "strict". -up2tc: Comma separated list mapping user priorities to traffic classes. -tcbw: Comma separated list of bandwidths for each traffic class the first value being assigned to traffic class 0 and the second to traffic class 1 and so on.
示例:
-
BCM957608> sudo niccli -i 1 get_qos NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- IEEE 8021QAZ ETS Configuration TLV: PRIO_MAP: 0:1 1:1 2:0 3:0 4:1 5:1 6:0 7:0 TC Bandwidth: 50% 50% 0% TSA_MAP: 0:ets 1:ets 2:strict IEEE 8021QAZ PFC TLV: PFC enabled: 3 ---more--- BCM957608> ets -tsa 0:ets,1:ets,2:ets -up2tc 0:0,1:0,2:0,3:0,4:0,5:1,6:0,7:0 -tcbw 50,25,25 Enhanced transmission selection (ets) configured successfully. BCM957608> sudo niccli -i 1 get_qos NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- IEEE 8021QAZ ETS Configuration TLV: PRIO_MAP: 0:0 1:0 2:0 3:0 4:0 5:1 6:0 7:0 TC Bandwidth: 50% 25% 25% TSA_MAP: 0:ets 1:ets 2:ets
如果需要,配置 PFC
-
BCM957608> help pfc DESCRIPTION : This command is used to enable priority-based flow control on a given priority. SYNTAX : pfc -enable <pfc list> The valid range is from 0 to 7. Where list is a comma-separated value for each pfc. To disable the pfc, user needs to provide a value of 0xFF.
示例:
-
BCM957608> sudo niccli -i 1 get_qos ---more--- IEEE 8021QAZ PFC TLV: PFC enabled: 3 <= default; PFC enabled for priority 3 ---more--- BCM957608> pfc -enable 0xFF <= disables pfc on all priorities. pfc configured successfully. BCM957608> sudo niccli -i 1 get_qos ---more--- IEEE 8021QAZ PFC TLV: PFC enabled: none <= pfc disabled on all priorities. ---more--- BCM957608> pfc -enable 5 pfc configured successfully. BCM957608> sudo niccli -i 1 get_qos ---more--- IEEE 8021QAZ PFC TLV: PFC enabled: 5 <= PFC enabled for priority 5 ---more---
以下命令尝试在优先级 5 和 6 上启用 PFC,并演示只能将一个队列(一个优先级)配置为无损队列(支持 PFC)。
-
BCM957608> pfc -enable 5,6 ERROR: Hardware doesn't support more than 1 lossless queues to configure pfc. ERROR: Failed to enable pfc.
使用 bnxt_setupcc.sh 配置 DCQCN 和 RoCE 流量标记值
使用 bnxt_setupcc.sh 可以简化流程的实用程序。
该 bnxt_setupcc.sh 实用程序可以简化启用或禁用 ECN 和 PFC,以及更改给定接口的 ROCE 和 CNP 数据包的 DSCP 和 PRIO 值。
在幕后,它使用 niccli (默认)或 lldptool 可以作为命令的一部分选择。
您需要按照 bnxt_setupcc.sh 帮助菜单中的说明输入,然后输入您选择的选项:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# bnxt_setupcc.sh Usage: bnxt_setupcc.sh [OPTION]... -d RoCE Device Name (e.g. bnxt_re0, bnxt_re_bond0) -i Ethernet Interface Name (e.g. p1p1 or for bond, specify slave interfaces like -i p6p1 -i p6p2) -m [1-3] 1 - PFC only 2 - CC only 3 - PFC + CC mode -v 1 - Enable priority vlan -r [0-7] RoCE Packet Priority -s VALUE RoCE Packet DSCP Value -c [0-7] RoCE CNP Packet Priority -p VALUE RoCE CNP Packet DSCP Value -b VALUE RoCE Bandwidth percentage for ETS configuration - Default is 50% -t [2] Default mode (Only RoCE v2 is supported - Input Ignored) -C VALUE Set CNP Service Type -u [1-3] Utility to configure QoS settings 1 - Use bnxtqos utility. Will disable lldptool if enabled. (default) 2 - Use lldptool 3 - Use Broadcom niccli utility. Will disable lldptool if enabled. -h display help
示例:
接口 gpu0 (bnxt_re0) 的 CNP 数据包的默认 DSCP 标记为 0,如下输出所示:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat apply | grep cnp ecn status (cnp_ecn) : Enabled cnp header ecn status (cnp_ecn) : ECT(1) minimum time between cnps (min_time_bet_cnp) : 0x0 usec rate reduction threshold (cnp_ratio_th) : 0x0 cnps cnp prio (cnp_prio) : 7 cnp dscp (cnp_dscp) : 0 root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat apply | grep cc congestion control mode (cc_mode) : DCQCN-P cr threshold to reset cc (reset_cc_cr_th) : 0x32a cc ack bytes (cc_ack_bytes) : 0x44 root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat cnp_prio 0x7 root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat cnp_dscp 0x0
bnxt_setupcc.sh可用于将其更改为交换矩阵 (48) 的预期值,如下所示:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# bnxt_setupcc.sh -d bnxt_re0 -i gpu0_eth -u 3 -p 48 -c 6 -s 26 -r 5 -m 3 ENABLE_PFC = 1 ENABLE_CC = 1 ENABLE_DSCP = 1 ENABLE_DSCP_BASED_PFC = 1 L2 50 RoCE 50 Using Ethernet interface gpu0_eth and RoCE interface bnxt_re0 Setting pfc/ets 0000:06:00.0 ---more--- AppTLV configured successfully.
地点:
- -u 3:使用 Broadcom niccli 实用程序
- -p 48:将 CNP 数据包的 DSCP 值设置为 48 (0x30)
- -c:将 CNP 数据包的优先级配置为 6
- -s:将常规 RoCE 数据包的 DSCP 值定义为 26 (0x1a)
- -r:将常规 RoCE 数据包的优先级设置为 5
- -m 3:配置 PFC 和拥塞控制 (ECN)。
通过以下方法验证结果:
-
root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat apply | grep cnp ecn status (cnp_ecn) : Enabled cnp header ecn status (cnp_ecn) : ECT(1) minimum time between cnps (min_time_bet_cnp) : 0x0 usec rate reduction threshold (cnp_ratio_th) : 0x0 cnps cnp prio (cnp_prio) : 6 cnp dscp (cnp_dscp) : 48 root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat apply | grep roce roce prio (roce_prio) : 5 roce dscp (roce_dscp) : 26 root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat cnp_prio 0x6 root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat cnp_dscp 0x30 <= 48 is HEX root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat roce_dscp 0x1a <= 26 is HEX root@MI300X-01:/sys/kernel/config/bnxt_re/bnxt_re0/ports/1/cc# cat roce_prio 0x5
bnxt_setupcc.sh需要确保已安装和可执行,还需要确保至少安装了一个工具(
niccli
lldptool或 )。
以下示例显示了 和 niccli 已bnxt_setupcc.sh安装,但lldptool未安装。它还显示了安装和使用 lldptool.
-
root@MI300X-01:/# which bnxt_setupcc.sh /usr/local/bin/bnxt_setupcc.sh root@MI300X-01:/usr/local/bin# ls bnxt_setupcc.sh -l -rwxr-xr-x 1 root root 14761 Jan 17 18:06 bnxt_setupcc.sh root@MI300X-01:/$ which niccli /usr/bin/niccli root@MI300X-01:/usr/bin$ ls niccli -l lrwxrwxrwx 1 18896 1381 18 Sep 25 18:52 niccli -> /opt/niccli/niccli root@MI300X-01:/opt/niccli$ ls niccli -l -rwxr-xr-x 1 18896 1381 609 Sep 25 18:52 niccli root@MI300X-01:/$ which lldptool
用于 lldptool 检查或修改 LLDP(链路层发现协议)设置。要启用 LLDP,您需要安装 lldpad, 它也会自动安装 lldptool 。
要安装 lldpad 并 lldptool 执行以下步骤:
- 安装所需的依赖项。
在安装 lldpad 之前,请确保通过运行以下命令安装必要的库:
-
sudo apt install libconfig9 libnl-3-200
- libconfig9 – 配置文件处理库。
- libnl-3-200 – 用于与 Linux Netlink 接互的库。
-
- 安装 lldpad。
通过运行以下命令安装 lldpad:
-
sudo apt install lldpad
此软件包可在系统上启用 LLDP,使其能够与其他设备交换网络拓扑信息。
-
- 启用 lldpad。
使用 systemctl 启用 lldp:
-
sudo systemctl enable lldpad
这将创建一个系统服务,确保 lldpad 在重新启动后始终运行。
-
- 启动 lldpad 服务
使用 systemctl 激活 lldp:
-
sudo systemctl start lldpad
这会立即激活 lldpad,使其能够处理 LLDP 数据包。
注意:要手动重新启动 lldpad,请使用:sudo systemctl restart lldpad
要禁用 lldpad 在启动时启动,请使用:sudo systemctl disable lldpad -
- 验证安装
使用 systemctl 检查服务状态
-
user@MI300X-01:/etc/apt$ sudo systemctl status lldpad ● lldpad.service - Link Layer Discovery Protocol Agent Daemon. Loaded: loaded (/usr/lib/systemd/system/lldpad.service; enabled; preset: enabled) Active: active (running) since Fri 2025-02-14 00:16:40 UTC; 2min 2s ago TriggeredBy: ● lldpad.socket Docs: man:lldpad(8) Main PID: 695860 (lldpad) Tasks: 1 (limit: 629145) Memory: 1.3M (peak: 2.0M) CPU: 510ms CGroup: /system.slice/lldpad.service └─695860 /usr/sbin/lldpad -t Feb 14 00:16:40 MI300X-01 systemd[1]: Started lldpad.service - Link Layer Discovery Protocol Agent Daemon..
这可确保工具已安装并可供使用。如果一切正常,您应该会看到“活动(正在运行)”状态。
您可以使用 lldptool 在接口上启用或禁用 LLDP,并检查 LLDP 状态和在该接口上发现的邻接方。lldptool -h 向您显示所有不同的选项:
-
user@MI300X-01:/etc/apt$ lldptool -h Usage: lldptool <command> [options] [arg] general command line usage format lldptool go into interactive mode <command> [options] [arg] general interactive command format Options: -i [ifname] network interface -V [tlvid] TLV identifier may be numeric or keyword (see below) -c <argument list> used with get TLV command to specify that the list of configuration elements should be retrieved -d use to delete specified argument from the configuration. (Currently implemented for DCBX App TLV settings) -n "neighbor" option for command -r show raw message -R show only raw messages -g destination agent (may be one of): - nearestbridge (nb) (default) - nearestcustomerbridge (ncb) - nearestnontpmrbridge (nntpmrb) Commands: license show license information -h|help show command usage information -v|version show version -p|ping ping lldpad and query pid of lldpad -q|quit exit lldptool (interactive mode) -S|stats get LLDP statistics for ifname -t|get-tlv get TLVs from ifname -T|set-tlv set arg for tlvid to value -l|get-lldp get the LLDP parameters for ifname -L|set-lldp set the LLDP parameter for ifname TLV identifiers: chassisID : Chassis ID TLV portID : Port ID TLV TTL : Time to Live TLV portDesc : Port Description TLV sysName : System Name TLV sysDesc : System Description TLV sysCap : System Capabilities TLV mngAddr : Management Address TLV macPhyCfg : MAC/PHY Configuration Status TLV powerMdi : Power via MDI TLV linkAgg : Link Aggregation TLV MTU : Maximum Frame Size TLV LLDP-MED : LLDP-MED Settings medCap : LLDP-MED Capabilities TLV medPolicy : LLDP-MED Network Policy TLV medLoc : LLDP-MED Location TLV medPower : LLDP-MED Extended Power-via-MDI TLV medHwRev : LLDP-MED Hardware Revision TLV medFwRev : LLDP-MED Firmware Revision TLV medSwRev : LLDP-MED Software Revision TLV medSerNum : LLDP-MED Serial Number TLV medManuf : LLDP-MED Manufacturer Name TLV medModel : LLDP-MED Model Name TLV medAssetID : LLDP-MED Asset ID TLV CIN-DCBX : CIN DCBX TLV CEE-DCBX : CEE DCBX TLV evb : EVB Configuration TLV evbcfg : EVB draft 0.2 Configuration TLV vdp : VDP draft 0.2 protocol configuration IEEE-DCBX : IEEE-DCBX Settings ETS-CFG : IEEE 8021QAZ ETS Configuration TLV ETS-REC : IEEE 8021QAZ ETS Recommendation TLV PFC : IEEE 8021QAZ PFC TLV APP : IEEE 8021QAZ APP TLV PVID : Port VLAN ID TLV PPVID : Port and Protocol VLAN ID TLV vlanName : VLAN Name TLV ProtoID : Protocol Identity TLV vidUsage : VID Usage Digest TLV mgmtVID : Management VID TLV linkAggr : Link Aggregation TLV uPoE : Cisco 4-wire Power-via-MDI TLV user@MI300X-01:/etc/apt$ sudo lldptool -S -i gpu0_eth Total Frames Transmitted = 0 Total Discarded Frames Received = 0 Total Error Frames Received = 0 Total Frames Received = 92 Total Discarded TLVs = 0 Total Unrecognized TLVs = 8 Total Ageouts = 0 user@MI300X-01:/etc/apt$ sudo lldptool -L -i gpu0_eth AMDinStatus=rxtx AMDinStatus = rxtx user@MI300X-01:/etc/apt$ sudo lldptool -S -i gpu0_eth Total Frames Transmitted = 5 Total Discarded Frames Received = 0 Total Error Frames Received = 0 Total Frames Received = 94 Total Discarded TLVs = 0 Total Unrecognized TLVs = 8 Total Ageouts = 0 user@MI300X-01:/etc/apt$ sudo lldptool -t -i gpu0_eth Chassis ID TLV MAC: 7c:c2:55:bd:75:d0 Port ID TLV MAC: 7c:c2:55:bd:75:d0 Time to Live TLV 120 IEEE 8021QAZ ETS Configuration TLV Willing: yes CBS: not supported MAX_TCS: 3 PRIO_MAP: 0:0 1:0 2:0 3:0 4:0 5:0 6:0 7:0 TC Bandwidth: 0% 0% 0% 0% 0% 0% 0% 0% TSA_MAP: 0:strict 1:strict 2:strict 3:strict 4:strict 5:strict 6:strict 7:strict IEEE 8021QAZ PFC TLV Willing: yes MACsec Bypass Capable: no PFC capable traffic classes: 1 PFC enabled: none End of LLDPDU TLV
有关更多详细信息,请查看 Broadcom 以太网网络适配器用户指南的手动安装和配置软件部分或安装 NICCLI 配置实用程序。
监控接口和 ECN/PFC作:
获得特定 GPU 的 Broadcom 名称后(如本部分开头所述),您就可以找到接口作状态以及 RoCE 流量和拥塞控制统计信息所在的目录。
- 导航到相应的目录
/sys/class/infiniband/<Broadcom-interface-name>
示例:
对于gpu0_eth:
-
root@MI300X-01:/home/jnpr/SCRIPTS# cd /sys/class/infiniband/bnxt_re3 root@MI300X-01:/sys/class/infiniband/bnxt_re3# ls device fw_ver hca_type hw_rev node_desc node_guid node_type ports power subsystem sys_image_guid uevent root@MI300X-01:/sys/class/infiniband/bnxt_re3# ls device/net/gpu3_eth/ addr_assign_type address addr_len broadcast carrier carrier_changes carrier_down_count carrier_up_count device dev_id dev_port dormant duplex flags gro_flush_timeout ifalias ifindex iflink link_mode mtu name_assign_type napi_defer_hard_irqs netdev_group operstate phys_port_id phys_port_name phys_switch_id power proto_down queues speed statistics subsystem testing threaded tx_queue_len type uevent
在这里,您可以检查作状态、地址、mtu、速度和接口统计信息等属性(包括传输和接收的数据包、丢弃的数据包,以及 ECN 标记的数据包、接收的 CNP 数据包和传输的 CNP 数据包):
-
root@MI300X-01:/sys/class/infiniband/bnxt_re3# cat device/net/gpu3_eth/operstate up root@MI300X-01:/sys/class/infiniband/bnxt_re3# cat device/net/gpu3_eth/address 7c:c2:55:bd:7e:20 root@MI300X-01:/sys/class/infiniband/bnxt_re3# cat device/net/gpu3_eth/mtu 9000 root@MI300X-01:/sys/class/infiniband/bnxt_re3# cat device/net/gpu3_eth/speed 400000 root@MI300X-01:/sys/class/infiniband/bnxt_re3# ls device/net/gpu3_eth/statistics collisions multicast rx_bytes rx_compressed rx_crc_errors rx_dropped rx_errors rx_fifo_errors rx_frame_errors rx_length_errors rx_missed_errors rx_nohandler rx_over_errors rx_packets tx_aborted_errors tx_bytes tx_carrier_errors tx_compressed tx_dropped tx_errors tx_fifo_errors tx_heartbeat_errors tx_packets tx_window_errors tx_fifo_errors rx_dropped rx_frame_errors rx_nohandlertx_aborted_errors tx_compressed tx_window_errors root@MI300X-01:/sys/class/infiniband/bnxt_re3# ls ports/1 cap_mask cm_rx_duplicates cm_rx_msgs cm_tx_msgs cm_tx_retries counters gid_attrs gids hw_counters lid lid_mask_count link_layer phys_state pkeys rate sm_lid sm_sl state root@MI300X-01:/sys/class/infiniband/bnxt_re3# ls ports/1/counters/ -m excessive_buffer_overrun_errors link_downed link_error_recovery local_link_integrity_errors port_rcv_constraint_errors port_rcv_data port_rcv_errors port_rcv_packets port_rcv_remote_physical_errors port_rcv_switch_relay_errors port_xmit_constraint_errors port_xmit_data port_xmit_discards port_xmit_packets port_xmit_wait symbol_error VL15_dropped
要检查 ECN 统计信息,请检查特定接口的相关计数器:
-
root@MI300X-01:/sys/class/infiniband/bnxt_re3# ls ports/1/hw_counters/ -m active_ahs active_cqs active_mrs active_mws active_pds active_qps active_rc_qps active_srqs active_ud_qps bad_resp_err db_fifo_register dup_req lifespan local_protection_err local_qp_op_err max_retry_exceeded mem_mgmt_op_err missing_resp oos_drop_count pacing_alerts pacing_complete pacing_reschedule recoverable_errors remote_access_err remote_invalid_req_err remote_op_err res_cmp_err res_cq_load_err res_exceed_max res_exceeds_wqe res_invalid_dup_rkey res_irrq_oflow resize_cq_cnt res_length_mismatch res_mem_err res_opcode_err res_rem_inv_err res_rx_domain_err res_rx_invalid_rkey res_rx_no_perm res_rx_pci_err res_rx_range_err res_srq_err res_srq_load_err res_tx_domain_err res_tx_invalid_rkey res_tx_no_perm res_tx_pci_err res_tx_range_err res_unaligned_atomic res_unsup_opcode res_wqe_format_err rnr_naks_rcvd rx_atomic_req rx_bytes rx_cnp_pkts rx_ecn_marked_pkts rx_good_bytes rx_good_pkts rx_out_of_buffer rx_pkts rx_read_req rx_read_resp rx_roce_discards rx_roce_errors rx_roce_only_bytes rx_roce_only_pkts rx_send_req rx_write_req seq_err_naks_rcvd to_retransmits tx_atomic_req tx_bytes tx_cnp_pkts tx_pkts tx_read_req tx_read_resp tx_roce_discards tx_roce_errors tx_roce_only_bytes tx_roce_only_pkts tx_send_req tx_write_req unrecoverable_err watermark_ahs watermark_cqs watermark_mrs watermark_mws watermark_pds watermark_qps watermark_rc_qps watermark_srqs watermark_ud_qps root@MI300X-01:/sys/class/infiniband# for iface in /sys/class/infiniband/*/ports/1/hw_counters/rx_ecn_marked_pkts; do echo "$(basename $(dirname $(dirname $(dirname $(dirname "$iface"))))) : $(cat "$iface")" done bnxt_re0 : 0 bnxt_re1 : 1102 bnxt_re2 : 532 bnxt_re3 : 707 bnxt_re4 : 474 bnxt_re5 : 337 bnxt_re6 : 970 bnxt_re7 : 440 root@MI300X-01:/sys/class/infiniband# for iface in /sys/class/infiniband/*/ports/1/hw_counters/tx_cnp_pkts; do echo "$(basename $(dirname $(dirname $(dirname $(dirname "$iface"))))) : $(cat "$iface")" done bnxt_re0 : 0 bnxt_re1 : 1102 bnxt_re2 : 532 bnxt_re3 : 707 bnxt_re4 : 474 bnxt_re5 : 337 bnxt_re6 : 970 bnxt_re7 : 440 root@MI300X-01:/sys/class/infiniband# for iface in /sys/class/infiniband/*/ports/1/hw_counters/rx_cnp_pkts; do echo "$(basename $(dirname $(dirname $(dirname $(dirname "$iface"))))) : $(cat "$iface")" done bnxt_re0 : 0 bnxt_re1 : 830 bnxt_re2 : 0 bnxt_re3 : 375 bnxt_re4 : 734 bnxt_re5 : 23 bnxt_re6 : 2395 bnxt_re7 : 2291
ethtool -s <InterfaceIndex> |egrep "pfc_frames|roce_pause" |more
示例:
-
root@MI300X-01:/sys/class/infiniband# for iface in $(ls /sys/class/net/ | grep '^gpu'); do echo "$iface :" sudo ethtool -S "$iface" | egrep "pfc_frames|roce_pause" done gpu0_eth : rx_pfc_frames: 0 tx_pfc_frames: 22598 continuous_roce_pause_events: 0 resume_roce_pause_events: 0 gpu1_eth : rx_pfc_frames: 0 tx_pfc_frames: 194626 continuous_roce_pause_events: 0 resume_roce_pause_events: 0 gpu2_eth : rx_pfc_frames: 0 tx_pfc_frames: 451620 continuous_roce_pause_events: 0 resume_roce_pause_events: 0 gpu3_eth : rx_pfc_frames: 0 tx_pfc_frames: 492042 continuous_roce_pause_events: 0 resume_roce_pause_events: 0 gpu4_eth : rx_pfc_frames: 0 tx_pfc_frames: 407113 continuous_roce_pause_events: 0 resume_roce_pause_events: 0 gpu5_eth : rx_pfc_frames: 0 tx_pfc_frames: 290378 continuous_roce_pause_events: 0 resume_roce_pause_events: 0 gpu6_eth : rx_pfc_frames: 0 tx_pfc_frames: 228918 continuous_roce_pause_events: 0 resume_roce_pause_events: 0 gpu7_eth : rx_pfc_frames: 0 tx_pfc_frames: 477572 continuous_roce_pause_events: 0 resume_roce_pause_events: 0 root@MI300X-01:/sys/class/infiniband# for iface in $(ls /sys/class/net/ | grep '^gpu'); do echo "$iface :" sudo ethtool -S "$iface" | grep cos | grep -v ": 0" done gpu0_eth : rx_bytes_cos0: 9529443988084 rx_packets_cos0: 3319036491 rx_bytes_cos4: 18230144638154 rx_packets_cos4: 5955503873 rx_discard_bytes_cos4: 3032625534 rx_discard_packets_cos4: 736191 tx_bytes_cos0: 27757371721830 tx_packets_cos0: 9297694711 tx_bytes_cos4: 604920 tx_packets_cos4: 2628 gpu1_eth : rx_bytes_cos0: 27969554019118 rx_packets_cos0: 9565740297 rx_bytes_cos4: 4193860 rx_packets_cos4: 47350 tx_bytes_cos0: 27738638134736 tx_packets_cos0: 9184463836 tx_bytes_cos4: 619484 tx_packets_cos4: 2686 tx_bytes_cos5: 81548 tx_packets_cos5: 1102 gpu2_eth : rx_bytes_cos0: 27961559203510 rx_packets_cos0: 9438688373 rx_bytes_cos4: 4134654 rx_packets_cos4: 46526 tx_bytes_cos0: 27177768852872 tx_packets_cos0: 9028738664 tx_bytes_cos4: 619444 tx_packets_cos4: 2686 tx_bytes_cos5: 39368 tx_packets_cos5: 532 gpu3_eth : rx_bytes_cos0: 27886187894460 rx_packets_cos0: 9394306658 rx_bytes_cos4: 4161424 rx_packets_cos4: 46910 tx_bytes_cos0: 27963541263338 tx_packets_cos0: 9314918707 tx_bytes_cos4: 619624 tx_packets_cos4: 2688 tx_bytes_cos5: 52318 tx_packets_cos5: 707 gpu4_eth : rx_bytes_cos0: 27760098268028 rx_packets_cos0: 9493708902 rx_bytes_cos4: 4190302 rx_packets_cos4: 47275 tx_bytes_cos0: 27943026331154 tx_packets_cos0: 9175330615 tx_bytes_cos4: 619068 tx_packets_cos4: 2683 tx_bytes_cos5: 35076 tx_packets_cos5: 474 gpu5_eth : rx_bytes_cos0: 27742656661456 rx_packets_cos0: 9603877462 rx_bytes_cos4: 4136456 rx_packets_cos4: 46558 tx_bytes_cos0: 27862529155204 tx_packets_cos0: 9053600792 tx_bytes_cos4: 619318 tx_packets_cos4: 2686 tx_bytes_cos5: 24938 tx_packets_cos5: 337 gpu6_eth : rx_bytes_cos0: 27204139187706 rx_packets_cos0: 9417550449 rx_bytes_cos4: 4309610 rx_packets_cos4: 48912 tx_bytes_cos0: 27939647032856 tx_packets_cos0: 9122722262 tx_bytes_cos4: 619248 tx_packets_cos4: 2685 tx_bytes_cos5: 71780 tx_packets_cos5: 970 gpu7_eth : rx_bytes_cos0: 27985967658372 rx_packets_cos0: 9636086344 rx_bytes_cos4: 4303716 rx_packets_cos4: 48823 tx_bytes_cos0: 27949102839310 tx_packets_cos0: 9149097911 tx_bytes_cos4: 619138 tx_packets_cos4: 2684 tx_bytes_cos5: 32560 tx_packets_cos5: 440 BCM957608> sudo niccli -i 2 listmap -pri2cos ------------------------------------------------------------------------------- NIC CLI v231.2.63.0 - Broadcom Inc. (c) 2024 (Bld-94.52.34.117.16.0) ------------------------------------------------------------------------------- Base Queue is 0 for port 0 ---------------------------- Priority TC Queue ID ------------------------ 0 0 4 1 0 4 2 0 4 3 1 0 4 0 4 5 0 4 6 0 4 7 2 5
将服务器配置为使用 RCCL 控制流量的管理接口:
ROCm 通信集体库 (RCCL) 创建 TCP 会话来协调进程并交换 RoCE 的队列对信息、GID(全局 ID)、本地和远程缓冲区地址、RDMA 密钥(用于内存访问权限的 RKEY)
这些 TCP 会话将在作业启动时创建,默认情况下使用其中一个 GPU 接口(用于 RoCEv2 流量的接口相同)。
示例:
-
jnpr@MI300X-01:~$ netstat -atn | grep 10.200 | grep "ESTABLISHED" tcp 0 0 10.200.4.8:47932 10.200.4.2:43131 ESTABLISHED tcp 0 0 10.200.4.8:46699 10.200.4.2:37236 ESTABLISHED tcp 0 0 10.200.2.8:60502 10.200.13.2:35547 ESTABLISHED tcp 0 0 10.200.4.8:37330 10.200.4.2:55355 ESTABLISHED tcp 0 0 10.200.4.8:56438 10.200.4.2:53947 ESTABLISHED ---more---
建议使用连接到(前端交换矩阵)的管理接口。为此,请在启动作业时包括以下内容: export NCCL_SOCKET_IFNAME=“mgmt_eth”。 相同的环境变量同时适用于 NCCL 和 RCCL。
示例:
-
jnpr@MI300X-01:~$ netstat -atn | grep 10.10.1 | grep "ESTABLISHED" tcp 0 0 10.10.1.0:44926 10.10.1.2:33149 ESTABLISHED tcp 0 0 10.10.1.0:46705 10.10.1.0:40320 ESTABLISHED tcp 0 0 10.10.1.0:54661 10.10.1.10:52452 ESTABLISHED ---more---
用于 RDMA 流量的 AMD Pollara DCQCN 配置
对于 AMD Pollara 验证,需要启用 DCQCN,并且必须在 AMD NIC 卡上应用 QOS。
- 使用脚本在 NIC 上配置 QOS。DSCP参数等同于表25中建议的值。服务器 DCQCN 配置参数。
-
jnpr@mi300-01:~$ cat /usr/local/bin/jnpr-setupqos.sh #!/bin/bash for i in $(sudo /usr/sbin/nicctl show port | grep Port | awk {'print $3'}); do sudo /usr/sbin/nicctl update port -p $i --pause-type pfc --rx-pause enable --tx-pause enable; done cts_dscp=48 cts_prio=2 data_dscp=26 data_prio=3 sudo nicctl update qos --classification-type dscp sudo nicctl update qos dscp-to-priority --dscp $cts_dscp --priority $cts_prio sudo nicctl update qos dscp-to-priority --dscp $data_dscp --priority $data_prio sudo nicctl update qos pfc --priority $cts_prio --no-drop enable sudo nicctl update qos pfc --priority $data_prio --no-drop enable sudo nicctl update qos dscp-to-purpose --dscp $cts_dscp --purpose xccl-cts
-
- 使用 AMD
nicctl命令行实用程序,以下是配置的 QOS 参数:-
jnpr@mi300-01:~$ sudo nicctl show qos | more NIC : 42424650-4c32-3530-3130-313346000000 (0000:06:00.0) Port : 0490812b-9860-4242-4242-000011010000 Classification type : DSCP DSCP-to-priority : DSCP bitmap : 0xfffefffffbffffff ==> priority : 0 DSCP bitmap : 0x0001000000000000 ==> priority : 2 DSCP bitmap : 0x0000000004000000 ==> priority : 3 DSCP : 0-25, 27-47, 49-63 ==> priority : 0 DSCP : 48 ==> priority : 2 DSCP : 26 ==> priority : 3 DSCP-to-purpose : 48 ==> xccl-cts PFC : PFC priority bitmap : 0xc PFC no-drop priorities : 2,3 Scheduling : -------------------------------------------- Priority Scheduling Bandwidth Rate-limit Type (in %age) (in Gbps) -------------------------------------------- 0 DWRR 0 N/A 2 DWRR 0 N/A 3 DWRR 0 N/A NIC : 42424650-4c32-3530-3130-313844000000 (0000:23:00.0) Port : 0490812b-9fb0-4242-4242-000011010000 Classification type : DSCP DSCP-to-priority : DSCP bitmap : 0xfffefffffbffffff ==> priority : 0 DSCP bitmap : 0x0001000000000000 ==> priority : 2 DSCP bitmap : 0x0000000004000000 ==> priority : 3 DSCP : 0-25, 27-47, 49-63 ==> priority : 0 DSCP : 48 ==> priority : 2 DSCP : 26 ==> priority : 3 DSCP-to-purpose : 48 ==> xccl-cts PFC : PFC priority bitmap : 0xc PFC no-drop priorities : 2,3 --More--
-
- 该
rdma link命令可用于检查是否存在与 AMD Pollara NIC 卡的 roce-devices 关联。-
jnpr@mi300-01:~$ rdma link | grep gpu link rocep9s0/1 state ACTIVE physical_state LINK_UP netdev gpu0_eth link rocep38s0/1 state ACTIVE physical_state LINK_UP netdev gpu1_eth link rocep70s0/1 state ACTIVE physical_state LINK_UP netdev gpu2_eth link roceo1/1 state ACTIVE physical_state LINK_UP netdev gpu3_eth link rocep137s0/1 state ACTIVE physical_state LINK_UP netdev gpu4_eth link rocep166s0/1 state ACTIVE physical_state LINK_UP netdev gpu5_eth link rocep198s0/1 state ACTIVE physical_state LINK_UP netdev gpu6_eth link rocep233s0/1 state ACTIVE physical_state LINK_UP netdev gpu7_eth
roce-devices 在加载 ionic_rdma 内核模块时创建,应为每个 NIC 卡创建以下 roce-device 文件。
-
jnpr@mi300-01:/sys/class/infiniband$ find /sys/class/infiniband -type l /sys/class/infiniband/rocep137s0 /sys/class/infiniband/rocep38s0 /sys/class/infiniband/rocep70s0 /sys/class/infiniband/roceo1 /sys/class/infiniband/rocep166s0 /sys/class/infiniband/rocep233s0 /sys/class/infiniband/rocep198s0 /sys/class/infiniband/rocep9s0
-
- 要在 AMD Pollara NIC 上配置 DCQCN,请使用适当的参数运行以下脚本。
-
jnpr @mi300-01:~$ cat /usr/local/bin/jnpr-enable-dcqcn.sh #!/bin/bash TOKEN_BUCKET_SIZE=800000 AI_RATE=160 ALPHA_UPDATE_INTERVAL=1 ALPHA_UPDATE_G=512 INITIAL_ALPHA_VALUE=64 RATE_INCREASE_BYTE_COUNT=431068 HAI_RATE=300 RATE_REDUCE_MONITOR_PERIOD=1 RATE_INCREASE_THRESHOLD=1 RATE_INCREASE_INTERVAL=1 CNP_DSCP=48 ROCE_DEVICES=$(rdma link | grep gpu | awk '{ print $2 }' | awk -F/ '{ print $1 }' | paste -sd " ") for roce_dev in $ROCE_DEVICES do sudo nicctl update dcqcn -r $roce_dev -i 1 \ --token-bucket-size $TOKEN_BUCKET_SIZE \ --ai-rate $AI_RATE \ --alpha-update-interval $ALPHA_UPDATE_INTERVAL \ --alpha-update-g $ALPHA_UPDATE_G \ --initial-alpha-value $INITIAL_ALPHA_VALUE \ --rate-increase-byte-count $RATE_INCREASE_BYTE_COUNT \ --hai-rate $HAI_RATE \ --rate-reduce-monitor-period $RATE_REDUCE_MONITOR_PERIOD \ --rate-increase-threshold $RATE_INCREASE_THRESHOLD \ --rate-increase-interval $RATE_INCREASE_INTERVAL \ --cnp-dscp $CNP_DSCP Done
-
- 使用 nicctl 命令,检查每个 roce-device 的 DCQCN 配置文件。
-
jnpr@mi300-01:~$ sudo nicctl show dcqcn --roce-device rocep137s0 | more ROCE device : rocep137s0 DCQCN profile id : 7 Status : Disabled Rate reduce monitor period : 100 Alpha update interval : 100 Clamp target rate : 0 Rate increase threshold : 1 Rate increase byte count : 431068 Rate increase in AI phase : 200 Alpha update G value : 50 Minimum rate : 1 Token bucket size : 4000000 Rate increase interval : 10 Rate increase in HAI phase : 200 Initial alpha value : 64 DSCP value used for CNP : 48 DCQCN profile id : 5 Status : Disabled Rate reduce monitor period : 100 Alpha update interval : 100 Clamp target rate : 0 Rate increase threshold : 1 Rate increase byte count : 431068 Rate increase in AI phase : 200 Alpha update G value : 50 Minimum rate : 1 Token bucket size : 4000000 Rate increase interval : 10 Rate increase in HAI phase : 200 Initial alpha value : 64 DSCP value used for CNP : 48 DCQCN profile id : 3 Status : Disabled Rate reduce monitor period : 100 Alpha update interval : 100 Clamp target rate : 0 Rate increase threshold : 1 Rate increase byte count : 431068 Rate increase in AI phase : 200 Alpha update G value : 50 Minimum rate : 1 Token bucket size : 4000000 Rate increase interval : 10 Rate increase in HAI phase : 200 Initial alpha value : 64 DSCP value used for CNP : 48 --More—
-
- 最后,运行rccl_test.sh脚本,如下所示。下面的示例显示了为“全部减少”运行的测试。
jnpr@mi300-01:/mnt/nfsshare/source/aicluster/rccl-tests$ ./run-rccl.sh Running all_reduce, channels 64, qps 1 ... Num nodes: 2 + tee --append /mnt/nfsshare/logs/rccl/MI300-RAILS-ALL/06062025_18_03_35/test.log + /opt/ompi/bin/mpirun --np 16 --allow-run-as-root -H MI300-01:8,MI300-02:8 --bind-to numa -x NCCL_IB_GID_INDEX=1 -x UCX_UNIFIED_MODE=y -x NCCL_IB_PCI_RELAXED_ORDERING=1 -x NCCL_GDR_FLUSH_DISABLE=1 -x RCCL_GDR_FLUSH_GPU_MEM_NO_RELAXED_ORDERING=0 -x PATH=/opt/ompi/bin:/opt/rocm/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin -x LD_LIBRARY_PATH=/home/dbarmann/pollara/rccl-7961624/build/release:/home/dbarmann/pollara/amd-anp-new/build:/opt/ompi/lib: -x UCX_NET_DEVICES=gpu0_eth,gpu1_eth,gpu2_eth,gpu3_eth,gpu4_eth,gpu5_eth,gpu6_eth,gpu7_eth -x NCCL_IB_HCA=rocep9s0,rocep38s0,rocep70s0,roceo1,rocep137s0,rocep166s0,rocep198s0,rocep233s0 --mca btl '^vader,openib' --mca btl_tcp_if_include mgmt_eth -x NCCL_MIN_NCHANNELS=64 -x NCCL_MAX_NCHANNELS=64 -x NCCL_IB_QPS_PER_CONNECTION=1 -x NCCL_TOPO_DUMP_FILE=/tmp/system_run2.txt -x HSA_NO_SCRATCH_RECLAIM=1 -x NCCL_GDRCOPY_ENABLE=0 -x NCCL_IB_TC=106 -x NCCL_IB_FIFO_TC=192 -x NCCL_IGNORE_CPU_AFFINITY=1 -x RCCL_LL128_FORCE_ENABLE=1 -x NCCL_PXN_DISABLE=0 -x NCCL_DEBUG=INFO -x NET_OPTIONAL_RECV_COMPLETION=1 -x NCCL_IB_USE_INLINE=1 -x NCCL_DEBUG_FILE=/mnt/nfsshare/logs/rccl/MI300-RAILS-ALL/06062025_18_03_35/nccl-debug.log -x 'LD_PRELOAD=/home/dbarmann/pollara/amd-anp-new/build/librccl-net.so /home/dbarmann/pollara/rccl-7961624/build/release/librccl.so' /mnt/nfsshare/source/aicluster/rccl-tests/build/all_reduce_perf -b 1024 -e 16G -f 2 -g 1 -n 20 -m 1 -c 1 -w 5_# nThread 1 nGpus 1 minBytes 1024 maxBytes 17179869184 step: 2(factor) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0_# rccl-tests: Version develop:b0a3841+ # Using devices # Rank 0 Group 0 Pid 18335 on mi300-01 device 0 [0000:05:00] AMD Instinct MI300X # Rank 1 Group 0 Pid 18336 on mi300-01 device 1 [0000:29:00] AMD Instinct MI300X # Rank 2 Group 0 Pid 18337 on mi300-01 device 2 [0000:49:00] AMD Instinct MI300X # Rank 3 Group 0 Pid 18340 on mi300-01 device 3 [0000:65:00] AMD Instinct MI300X # Rank 4 Group 0 Pid 18338 on mi300-01 device 4 [0000:85:00] AMD Instinct MI300X # Rank 5 Group 0 Pid 18341 on mi300-01 device 5 [0000:a9:00] AMD Instinct MI300X # Rank 6 Group 0 Pid 18342 on mi300-01 device 6 [0000:c9:00] AMD Instinct MI300X # Rank 7 Group 0 Pid 18339 on mi300-01 device 7 [0000:e5:00] AMD Instinct MI300X # Rank 8 Group 0 Pid 16249 on mi300-02 device 0 [0000:05:00] AMD Instinct MI300X # Rank 9 Group 0 Pid 16251 on mi300-02 device 1 [0000:29:00] AMD Instinct MI300X # Rank 10 Group 0 Pid 16250 on mi300-02 device 2 [0000:49:00] AMD Instinct MI300X # Rank 11 Group 0 Pid 16254 on mi300-02 device 3 [0000:65:00] AMD Instinct MI300X # Rank 12 Group 0 Pid 16255 on mi300-02 device 4 [0000:85:00] AMD Instinct MI300X # Rank 13 Group 0 Pid 16253 on mi300-02 device 5 [0000:a9:00] AMD Instinct MI300X # Rank 14 Group 0 Pid 16252 on mi300-02 device 6 [0000:c9:00] AMD Instinct MI300X # Rank 15 Group 0 Pid 16256 on mi300-02 device 7 [0000:e5:00] AMD Instinct MI300X # # out-of-place in-place # size count type redop root time algbw busbw #wrong time algbw busbw #wrong # (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s) 1024 256 float sum -1 41.61 0.02 0.05 0 53.55 0.02 0.04 0 2048 512 float sum -1 43.79 0.05 0.09 0 50.54 0.04 0.08 0 4096 1024 float sum -1 45.75 0.09 0.17 0 45.21 0.09 0.17 0 8192 2048 float sum -1 46.50 0.18 0.33 0 47.75 0.17 0.32 0 16384 4096 float sum -1 60.52 0.27 0.51 0 48.90 0.34 0.63 0 32768 8192 float sum -1 49.68 0.66 1.24 0 52.57 0.62 1.17 0 65536 16384 float sum -1 53.75 1.22 2.29 0 52.74 1.24 2.33 0 131072 32768 float sum -1 69.16 1.90 3.55 0 56.83 2.31 4.32 0 262144 65536 float sum -1 69.31 3.78 7.09 0 63.17 4.15 7.78 0 524288 131072 float sum -1 77.16 6.79 12.74 0 80.51 6.51 12.21 0 1048576 262144 float sum -1 127.5 8.23 15.42 0 107.6 9.75 18.28 0 2097152 524288 float sum -1 125.0 16.78 31.46 0 130.9 16.02 30.04 0 4194304 1048576 float sum -1 149.5 28.06 52.61 0 148.4 28.26 52.99 0 8388608 2097152 float sum -1 222.9 37.63 70.55 0 231.6 36.21 67.90 0 16777216 4194304 float sum -1 321.3 52.21 97.90 0 326.2 51.43 96.43 0 33554432 8388608 float sum -1 436.2 76.93 144.25 0 447.0 75.06 140.75 0 67108864 16777216 float sum -1 678.9 98.85 185.35 0 684.6 98.02 183.79 0 134217728 33554432 float sum -1 1164.6 115.25 216.10 0 1148.1 116.90 219.19 0 268435456 67108864 float sum -1 1550.3 173.15 324.66 0 1563.9 171.65 321.84 0 536870912 134217728 float sum -1 2979.9 180.16 337.81 0 2977.6 180.30 338.07 0 1073741824 268435456 float sum -1 5824.8 184.34 345.64 0 5859.5 183.25 343.59 0 2147483648 536870912 float sum -1 11596 185.20 347.25 0 11611 184.94 346.77 0 4294967296 1073741824 float sum -1 520420 8.25 15.47 0 23190 185.21 347.27 0 8589934592 2147483648 float sum -1 46157 186.10 348.94 0 46150 186.13 349.00 0 17179869184 4294967296 float sum -1 568668 30.21 56.65 0 91823 187.10 350.81 0 # Errors with asterisks indicate errors that have exceeded the maximum threshold. # Out of bounds values : 0 OK # Avg bus bandwidth : 117.077 #