了解 CoS 虚拟输出队列 (VOQ)
通过交换机转发流量的传统方法就是在入口接口上的输入队列中缓冲入口流量,通过交换矩阵将流量转发到出口接口上的输出队列,然后在输出队列上再次缓冲流量,然后再将流量传输到下一跃点。在入口端口上对数据包进行排队的传统方法是将发往不同出口端口的流量存储在同一输入队列(缓冲区)中。
在拥塞期间,交换机可能会在出口端口丢包,因此交换机可能会花费资源通过交换矩阵将流量传输到出口端口,结果却丢弃该流量,而不是转发。由于输入队列存储发往不同出口端口的流量,一个出口端口上的拥塞可能会影响不同出口端口上的流量,这种情况称为队头阻塞 (HOLB)。
虚拟输出队列 (VOQ) 架构采用不同的方法:
-
交换机不是用于输入和输出队列的单独物理缓冲区,而是使用每个数据包转发引擎 (PFE) 芯片入口管道上的物理缓冲区来存储每个出口端口的流量。出口端口上的每个输出队列在交换机上所有 PFE 芯片上的每个入口管道上都有缓冲区存储空间。入口管道存储空间到输出队列的映射是 1 对 1,因此每个输出队列在每个入口管道上接收缓冲区空间。
-
每个输出队列都有一个专用的 VOQ,该 VOQ 由每个数据包转发芯片上的输入缓冲区组成,专用于该输出队列(1 对 1 映射)。此架构可防止任意两个端口之间的通信影响另一个端口。
-
在出口端口具有转发流量的资源之前,VOQ 不会将流量从交换矩阵入口端口传输到出口端口,而不是将流量存储在物理输出队列中,直到可以转发为止。
VOQ 是输入队列(缓冲区)的集合,用于接收和存储发往一个出口端口上的一个输出队列的流量。每个出口端口上的每个输出队列都有自己的专用 VOQ,其中包含向该输出队列发送流量的所有输入队列。
VOQ 架构
VOQ 表示特定输出队列的入口缓冲。唯一的缓冲区 ID 标识 PFE 芯片上的每个输出队列。六个 PFE 芯片中的每一个都对特定输出队列使用相同的唯一缓冲区 ID。在六个 PFE 芯片上使用特定缓冲区 ID 存储的流量包括发往一个端口上一个特定输出队列的流量,并且是该输出队列的 VOQ。
如果交换机有 72 个出口端口,每个端口上有 8 个输出队列,则每个 PFE 芯片上有 576 个 VOQ (72 x 8 = 576)。由于交换机有六个 PFE 芯片,因此交换机总共有 3,456 个 VOQ (576 x 6 = 3,456)。
VOQ 分布在主动向该输出队列发送流量的所有 PFE 芯片上。每个输出队列是所有 PFE 芯片中分配给该输出队列的缓冲区总数之和(按其唯一缓冲区 ID)。因此,输出队列本身是虚拟的,而不是物理的,尽管输出队列由物理输入队列组成。
往返时间缓冲
虽然在拥塞期间没有输出队列缓冲(无长期存储),但出口线卡上有一个小型物理输出队列缓冲区,用于满足流量从入口到出口遍历交换矩阵的往返时间。往返时间包括入口端口请求出口端口资源、从出口端口接收资源授权以及通过交换矩阵传输数据所需的时间。
这意味着,如果数据包未在交换机入口处丢弃,且交换机将数据包通过交换矩阵转发到出口端口,则数据包将不会被丢弃,而是被转发到下一跃点。所有丢包都在入口管道中进行。
交换机具有 4 GB 的外部 DRAM,可用作延迟带宽缓冲区 (DBB)。DBB 为入口端口提供存储,直到端口可以将流量转发到出口端口。
请求和授予出口端口带宽
当数据包到达入口端口时,入口管道会将数据包存储在入口队列中,其中包含目标输出队列的唯一缓冲区 ID。交换机在执行数据包查找后做出缓冲决策。如果数据包属于已超过最大流量阈值的类,则数据包可能不会被缓冲,并且可能会被丢弃。要通过交换矩阵将数据包传输到出口端口:
-
入口线卡 PFE 请求调度程序向出口线卡 PFE 授权调度程序发送请求,以通知出口 PFE 数据可供传输。
-
当有可用的出口带宽时,出口线卡授权调度程序会通过向入口线卡 PFE 发送带宽授权来进行响应。
-
入口线卡 PFE 从出口线卡 PFE 接收授权,并将数据传输到出口线卡。
入口数据包将保留在入口端口输入队列的 VOQ 中,直到输出队列准备好接受和转发更多流量。
在大多数情况下,交换矩阵的速度足够快,对出口服务等级 (CoS) 策略保持透明,因此将流量从入口管道转发到交换矩阵到出口端口的过程不会影响为流量配置的 CoS 策略。只有在发生交换矩阵故障或端口公平性问题时,交换矩阵才会影响 CoS 策略。
当数据包进出同一 PFE 芯片(本地交换)时,数据包不会遍历交换矩阵。但是,交换机使用与通过交换矩阵的数据包相同的请求和授权机制来接收出口带宽,因此,当流量争用同一输出队列时,本地交换的数据包和通过交换矩阵后到达 PFE 芯片的数据包将得到公平对待。
VOQ 优势
VOQ架构提供两大优势:
消除队头阻塞
VOQ 架构消除了队头阻塞 (HOLB) 问题。在非 VOQ 交换机上,当出口端口的拥塞影响未拥塞的不同出口端口时,就会发生 HOLB。当拥塞端口和未拥塞端口在入口接口上共享同一输入队列时,将发生 HOLB。
HOLB 场景的一个示例是,交换机的流量流进入一个入口端口 (IP-1),这些流量流发往两个不同的出口端口(EP-2 和 EP-3):
-
出口端口 EP-2 上发生拥塞。出口端口 EP-3 上没有拥塞,如 图 1 所示。
图 1:EP-2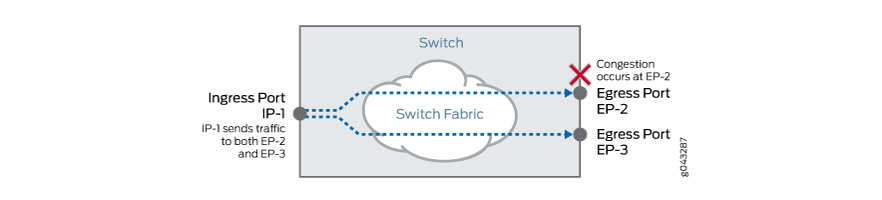 上发生拥塞
上发生拥塞
-
出口端口 EP-2 向入口端口 IP-1 发送背压信号,如 图 2 所示。
图 2:EP-2 背压 IP-1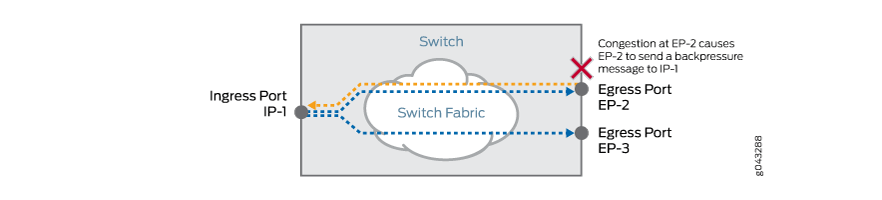
-
背压信号会导致入口端口 IP-1 停止发送流量并缓冲流量,直到它收到恢复发送的信号,如 图 3 所示。到达入口端口 IP-1、发往未拥塞出口端口 EP-3 的流量将与发往拥塞端口 EP-2 的流量一起缓冲,而不是转发至端口 EP-3。
图 3:EP-2 的背压导致 IP-1 缓冲流量而不是发送流量,从而影响 EP-3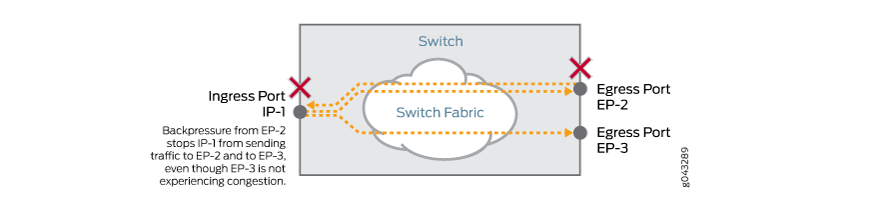
-
只有当出口端口 EP-2 清除到足以允许入口端口 IP-1 恢复发送流量时,入口端口 IP-1 才会将流量传输到未拥塞的出口端口 EP-3,如 图 4 所示。
图 4:EP-2 上的拥塞消失,允许 IP-1 恢复向两个出口端口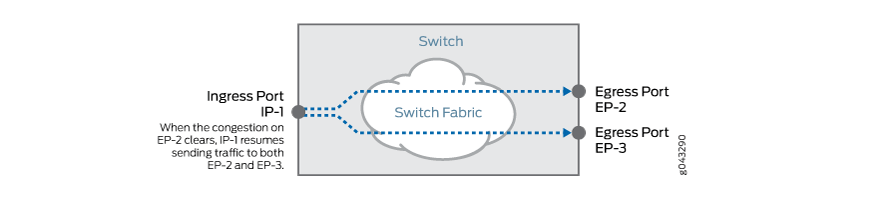 发送流量
发送流量
这样,拥塞的出口端口 EP-2 会对未拥塞的出口端口 EP-3 产生负面影响,因为两个出口端口在入口端口 IP-1 上共享相同的输入队列。
VOQ 架构通过为每个接口上的每个输出队列创建不同的专用虚拟队列来避免 HOLB,如 图 5 所示。
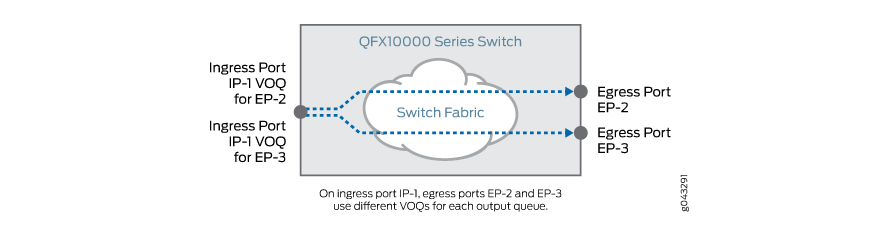 上都有一个单独的虚拟输出队列
上都有一个单独的虚拟输出队列
由于不同的出口队列不共享同一个输入队列,因此一个端口上的拥塞出口队列不会影响其他端口上的出口队列,如 图 6 所示。(出于同样的原因,一个端口上拥塞的出口队列不会影响同一端口上的另一个出口队列。每个输出队列都有自己的专用虚拟输出队列,由入口接口输入队列组成。)
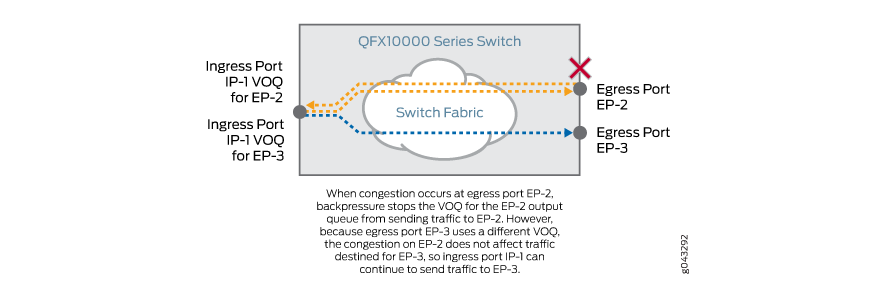
在入口接口执行队列缓冲可确保交换机仅在出口队列已准备好接收该流量时,才会通过交换矩阵将流量发送到出口队列。如果出口队列尚未准备好接收流量,则流量将保持在入口接口上缓冲。
提高交换矩阵效率和利用率
传统的输出队列架构有一些固有的低效率问题,VOQ 架构可以解决这些问题。
-
数据包缓冲 — 传统的队列架构会在长期 DRAM 存储中将每个数据包缓冲两次,一次在入口接口,一次在出口接口。VOQ 架构仅在入口接口的长期 DRAM 存储中缓冲每个数据包一次。交换结构的速度足够快,可以对出口 CoS 策略保持透明,因此交换机可以以不需要深度出口缓冲区的速率转发流量,而不会影响配置的出口 CoS 策略(调度),而不是在出口接口上再次缓冲数据包。
-
资源消耗 — 传统的队列架构将数据包从入口接口输入队列(缓冲区)通过交换矩阵发送到出口接口输出队列(缓冲区)。在出口接口,即使交换机已消耗资源通过交换矩阵传输数据包并将其存储在出口队列中,数据包也可能被丢弃。在出口接口准备好传输流量之前,VOQ 架构不会通过交换矩阵将数据包发送到出口接口。这样可以提高系统利用率,因为不会浪费任何资源来传输和存储稍后丢弃的数据包。
独立于 VOQ 架构的瞻博网络交换架构还能提供更好的交换矩阵利用率,因为交换机可以将数据包转换为信元。单元具有可预测的尺寸,使交换机能够将单元均匀地喷射到交换矩阵链路上,从而更充分地利用交换矩阵链路。数据包大小差异很大,而且数据包大小不可预测。由于数据包大小的差异和不可预测性,基于数据包的交换矩阵的利用率不得超过 65-70%。瞻博网络基于单元的交换矩阵可以提供近 95% 的交换矩阵利用率,这要归功于对小区大小的可预测性和可控性。