Requisitos do sistema de controlador NorthStar
O NorthStar Controller opera em sistemas Linux que executam o CentOS ou o Red Hat Enterprise Linux (RHEL) versão 7.6, 7.7 ou 7.9.
Certifique-se de que:
Você usa uma versão compatível do CentOS Linux ou Red Hat Enterprise Linux (RHEL). Essas são nossas recomendações para o Linux:
Imagem do CentOS Linux ou RHEL 7,6, 7,7 ou 7,9. Versões anteriores não são suportadas.
Instale sua escolha de versão linux suportada usando o ISO mínimo.
Você usa RAM, número de CPUs virtuais e disco rígido especificados no Server Sizing Guidance para sua instalação.
Você abre as portas listadas no Firewall Port Guidance.
Ao atualizar o NorthStar Controller, os arquivos são apoiados no /opt directory.
Orientação de dimensionamento de servidor
A orientação nesta seção deve ajudá-lo a configurar seus servidores com recursos suficientes para oferecer suporte eficiente e eficaz às funções do Controlador NorthStar. As recomendações nesta seção são o resultado de testes internos combinados com dados de campo.
Uma implantação típica do NorthStar contém os seguintes sistemas:
Um sistema de aplicativos
O sistema de aplicativos contém o elemento de computação de caminho (PCE), o servidor de computação de caminho (PCS), os componentes para acesso à Web, aquisição de topologia, coleta de mensagens CLI ou SNMP e, um banco de dados de configuração.
Um sistema de análise
O sistema de análise é usado para telemetria e coleta de dados do NetFlow, e contém o banco de dados de análise. O sistema de análise é usado em implantações que rastreiam os níveis de tráfego de uma rede.
(Opcional) Um coletor dedicado ou secundário
Um coletor secundário é usado para a coleta de mensagens CLI e SNMP de nós grandes e é necessário quando há necessidade de uma coleta pesada de dados; ver Tabela 2.
(Opcional) Um nó de planejador dedicado
Um nó de planejador é necessário para executar simulação de rede offline em um sistema que não seja o sistema de aplicativos; ver Tabela 2.
Para implantações de alta disponibilidade, descritas na configuração de um cluster NorthStar para alta disponibilidade, um cluster teria 3 ou mais sistemas de aplicação e análise, mas eles seriam dimensionados de forma semelhante a uma implantação com um único sistema de aplicativos e um único sistema de análise.
A Tabela 1 descreve os requisitos estimados de servidor dos sistemas de aplicação e análise pelo tamanho da rede.
Tipo de instância |
POC/LAB (RAM / vCPU / HDD) |
Médio (nós <75) (RAM / vCPU / HDD) |
Grandes (nós <300) (RAM / vCPU / HDD) |
XL (mais de 300 nós)* (RAM / vCPU / HDD) |
|---|---|---|---|---|
Aplicativo |
16G / 4vCPU / 500G |
64G / 8vCPU / 1T |
96G / 8vCPU / 1,5T |
128G / 8vCPU / 2T |
Para a coleta de um grande número de mensagens SNMP e CLI em um único sistema de não alta disponibilidade (HA), você pode exigir 16GB de RAM e 8 vCPUs adicionais ou um coletor secundário; ver Tabela 2. |
||||
Analytics |
16G/4vCPU/500G |
48G / 6vCPU/ 1T |
64G / 8vCPU/ 2T |
64G / 12vCPU / 3T |
As implantações de NetFlow podem exigir 16G a 32G RAM adicionais e duplicar as CPUs virtuais no sistema de análise. |
||||
|
Nota:
Com base no número de dispositivos em sua rede, verifique com seu representante da Juniper Networks para confirmar seus requisitos específicos para redes na categoria XL. |
||||
A Tabela 2 descreve os requisitos estimados de servidor para os coletores secundários e o planejador dedicado.
Tipo de instância |
POC/LAB (RAM / vCPU / HDD) |
Médio (nós <75) (RAM / vCPU / HDD) |
Grandes (nós <300) (RAM / vCPU / HDD) |
XL (mais de 300 nós) (RAM / vCPU / HDD) |
|---|---|---|---|---|
Tudo em um |
24G / 8vCPU/ 1T |
Não aplicável |
Não aplicável |
Não aplicável |
Coletores secundários |
8G / 4vCPU / 200G |
16G / 8vCPU / 500G |
16G / 8vCPU / 500G |
16G / 8vCPU / 500G |
Planejador dedicado |
8G / 4vCPU / 200G |
16G / 8vCPU / 1T |
16G / 8vCPU / 1T |
16G / 8vCPU / 1T |
A RAM adicional pode ser necessária com base no número de sessões de planejador ativo e complexidade dos modelos. |
||||
|
Nota:
O All-In-One é uma configuração onde todos os componentes estão instalados em uma única máquina virtual, destina-se apenas a fins de demonstração. Não é recomendado para implantações de produção ou configurações de laboratório destinadas a modelar implantações de produção. |
||||
Ao instalar o Centos de instalação mínimo ou o RHEL Linux, os sistemas de arquivos podem ser colapsado em um único sistema de arquivos raiz (/) ou sistemas de arquivos separados. Se você estiver usando sistemas de arquivos separados, você pode atribuir espaço para cada cliente de acordo com o tamanho mencionado na Tabela 3 para os diferentes diretórios.
Filesystem |
Requisito de espaço |
Propósito |
|---|---|---|
/Boot |
1G |
Kernel linux e arquivos necessários para inicialização |
Trocar |
0 a 4G |
Não é necessário, mas pode ter configuração mínima |
/ |
10G |
Sistema operacional (incluindo /usr) |
/var/lib/docker |
20G |
Processos conteinerizados (apenas sistema de aplicativos) |
/Tmp |
24G |
Arquivos de depuração NorthStar em caso de erro de processo (apenas sistema de aplicativo) |
/Optar |
Espaço restante no sistema de arquivos |
Componentes northstar |
- Espaço adicional em disco para a JTI Analytics em elasticSearch
- Espaço adicional em disco para eventos de rede em Cassandra
- Requisitos de memória de coletor (Aipo)
Espaço adicional em disco para a JTI Analytics em elasticSearch
É necessário um espaço de armazenamento considerável para oferecer suporte às análises de JTI no ElasticSearch. Cada evento de registro JTI requer aproximadamente 330 bytes de espaço em disco. Uma estimativa razoável do número de eventos gerados é (<números de interfaces> + <números de LSPs>) ÷ relatórios de intervalo em segundos = eventos por segundo.
Assim, para uma rede com 500 roteadores, interfaces de 50K e LSPs de 60K, com um intervalo configurado de relatórios de cinco minutos (300 segundos), você pode esperar que algo no bairro de 366 eventos por segundo seja gerado. A 330 bytes por evento, ele sai para 366 eventos x 330 bytes x 86.400 segundos em um dia = mais de 10G de espaço em disco por dia ou 3,65T por ano. Para uma rede de mesmo tamanho, mas com um intervalo de relatórios de um minuto (60 segundos), você teria um requisito muito maior de espaço em disco — mais de 50G por dia ou 18T por ano.
Há um evento de roll-up adicional criado por hora por elemento para agregação de dados. Em uma rede com interfaces de 50K e LSPs de 60K (total de elementos de 110K), você teria eventos de roll-up de 110K por hora. Em termos de espaço em disco, seriam eventos de 110K por hora x 330 bytes por evento x 24 horas por dia = quase 1G de espaço em disco necessário por dia.
Para uma rede típica de cerca de 100K elementos (interfaces + LSPs), recomendamos que você permita um adicional de 11G de espaço de disco por dia se tiver um intervalo de relatórios de cinco minutos, ou 51G por dia se tiver um intervalo de relatórios de um minuto.
Veja a retenção de dados bruta e agregada do NorthStar Analytics no Guia do usuário do controlador NorthStar para obter informações sobre a personalização de parâmetros de agregação e retenção de dados para reduzir a quantidade de espaço em disco exigido pela ElasticSearch.
Espaço adicional em disco para eventos de rede em Cassandra
O banco de dados de Cassandra é outro componente que requer espaço adicional em disco para armazenamento de eventos de rede.
Usando esse mesmo exemplo de interfaces 50K e LSPs de 60K (110 elementos) e estimando um evento a cada 15 minutos (900 segundos) por elemento, haveria 122 eventos por segundo. O armazenamento necessário seria então de 122 eventos por segundo x 300 bytes por evento x 86.400 segundos por dia = cerca de 3,2 G por dia, ou 1,2T por ano.
Usando um evento a cada 5 minutos por elemento como estimativa em vez de cada 15 minutos, o requisito adicional de armazenamento é mais como 9,6G por dia ou 3,6T por ano.
Para uma rede típica de cerca de 100K elementos (interfaces + LSPs), recomendamos que você permita um adicional de 3-10G de espaço de disco por dia, dependendo da taxa de geração de eventos em sua rede.
Por padrão, o NorthStar mantém o histórico de eventos por 35 dias. Para personalizar o número de dias em que os dados do evento são retidos:
Modifique o parâmetro de dbCapacity em
/opt/northstar/data/web_config.jsonReinicie o processo pruneDB usando o
supervisorctl restart infra:prunedbcomando.
Requisitos de memória de coletor (Aipo)
Quando você usa o script collector.sh para instalar coletores secundários em um servidor separado do aplicativo NorthStar (para coleta distribuída), o script instala o número padrão de trabalhadores coletores descrito na Tabela 4. O número de processos de aipo iniciados por cada trabalhador é o número de núcleos na CPU mais um. Assim, em um servidor de 32 núcleos (por exemplo), o único trabalhador padrão instalado iniciaria 33 processos de aipo. Cada processo de aipo usa cerca de 50M de RAM.
Núcleos de CPU |
Trabalhadores instalados |
Processos totais de trabalhadores |
RAM mínima necessária |
|---|---|---|---|
1-4 |
4 |
20 (CPUs +1) x 4 = 20 |
1 GB |
5-8 |
3 |
18 (CPUs +1) x 2 = 18 |
1 GB |
16 |
1 |
17 (CPUs +1) x 1 = 17 |
1 GB |
32 |
1 |
33 (CPUs +1) x 1 = 33 |
2 GB |
Consulte a instalação de coletores secundários para coleta distribuída de dados para obter mais informações sobre a coleta distribuída de dados e trabalhadores secundários.
O número padrão de trabalhadores instalados visa otimizar os recursos do servidor, mas você pode alterar o número usando o script config_celery_workers.sh fornecido. Consulte a personalização da instalação do Collector Worker para obter mais informações. Você pode usar esse script para equilibrar o número de trabalhadores instalados com a quantidade de memória disponível no servidor.
Este script também está disponível para alterar o número de trabalhadores instalados no servidor de aplicativos NorthStar a partir do padrão, que também segue as fórmulas mostradas na Tabela 4.
Orientação de porta de firewall
As portas listadas na Tabela 5 devem ser permitidas por qualquer firewall externo que esteja sendo usado. As portas com a palavra cluster em suas descrições de propósito estão associadas à funcionalidade de alta disponibilidade (HA). Se você não estiver planejando configurar um ambiente ha, você pode ignorar essas portas. As portas com a palavra Analytics em suas descrições de propósito estão associadas ao recurso Analytics. Se você não estiver planejando usar o Analytics, você pode ignorar essas portas. As portas restantes listadas devem ser mantidas abertas em todas as configurações.
Port |
Purpose |
|---|---|
179 |
BGP: JunosVM ou cRPD para roteador BGP-LS — não é necessário se o IGP for usado para aquisição de topologia. Em uma instalação de cRPD, o roteador conecta a porta 179/TCP (BGP) diretamente ao servidor de aplicativos NorthStar. O cRPD é executado como um processo dentro do servidor de aplicativos NorthStar. Junos VM e cRPD são mutuamente exclusivos. |
161 |
SNMP |
450 |
NTAD |
830 |
COMUNICAÇÃO NETCONF entre NorthStar Controller e roteadores. Esta é a porta padrão para NETCONFD, mas em algumas instalações, a porta 22 é a preferida. Para mudar para a porta 22, acesse o NorthStar CLI conforme descrito na configuração das configurações do NorthStar usando o NorthStar CLI e modifique o valor da configuração da porta. Use o set northstar netconfd device-connection-pool netconf port comando. |
1514 |
Syslog: Relatórios padrão da interface de telemetria Junos para estatísticas de sondagem de RPM (suporte a Analytics) |
1812 |
Autenticação RADIUS |
2222 |
Daemon de gerenciamento em contêiner (cMGD). Usado para acessar o NorthStar CLI. |
2888 |
Cluster Zookeeper |
3000 |
JTI: Relatórios padrão da interface de telemetria Junos para IFD, IFL e LSP (oferece suporte ao NorthStar Analytics). Em versões anteriores do NorthStar, eram necessárias três portas JTI (2000, 2001, 2002). A partir da versão 4.3.0, esta única porta é usada em vez disso. |
3001 |
Telemetria orientada por modelo (MDT) |
3100 |
Telemetria em streaming para Ericsson. |
3888 |
Cluster Zookeeper |
4000 |
MDT (pipeline) — Comunicação de logstash |
4189 |
PCEP: PCC (roteador) para o servidor PCE NorthStar |
5000 |
cMGD-REST |
5672 |
Rabbitmq |
6379 |
Redis |
7000 |
Porta de comunicações para NorthStar Planner |
7001 |
Cluster de banco de dados de Cassie |
8123 |
Notificação do Health Monitor quando o controlador NorthStar e as análises são instalados em diferentes servidores; |
8124 |
Monitor de saúde |
8443 |
Web: Cliente web/REST para proteger servidor web (https) |
9000 |
Netflow |
9042 |
Servidor De planejador remoto |
9200 |
Chamadas de API de pesquisa elástica (monitoramento, pesquisa e agregação) em HTTP. |
9201 |
Pesquisa elástica quando o controlador NorthStar e o servidor de análise são instalados em servidores separados. |
9300 |
Cluster de pesquisa elástica |
10001 |
Modo passivo BMP: por padrão, o monitor ouve nesta porta as conexões recebidas da rede. |
17000 |
Cluster de banco de dados de Cassie |
50051 |
PRPD: aplicativo NorthStar para rede de roteador |
A Figura 1 detalha a direção do fluxo de dados pelas portas, quando clusters de nós não estão sendo usados. A Figura 2 e a Figura 3 detalham os fluxos adicionais para clusters ha de aplicativos NorthStar e clusters de HA de análise, respectivamente.
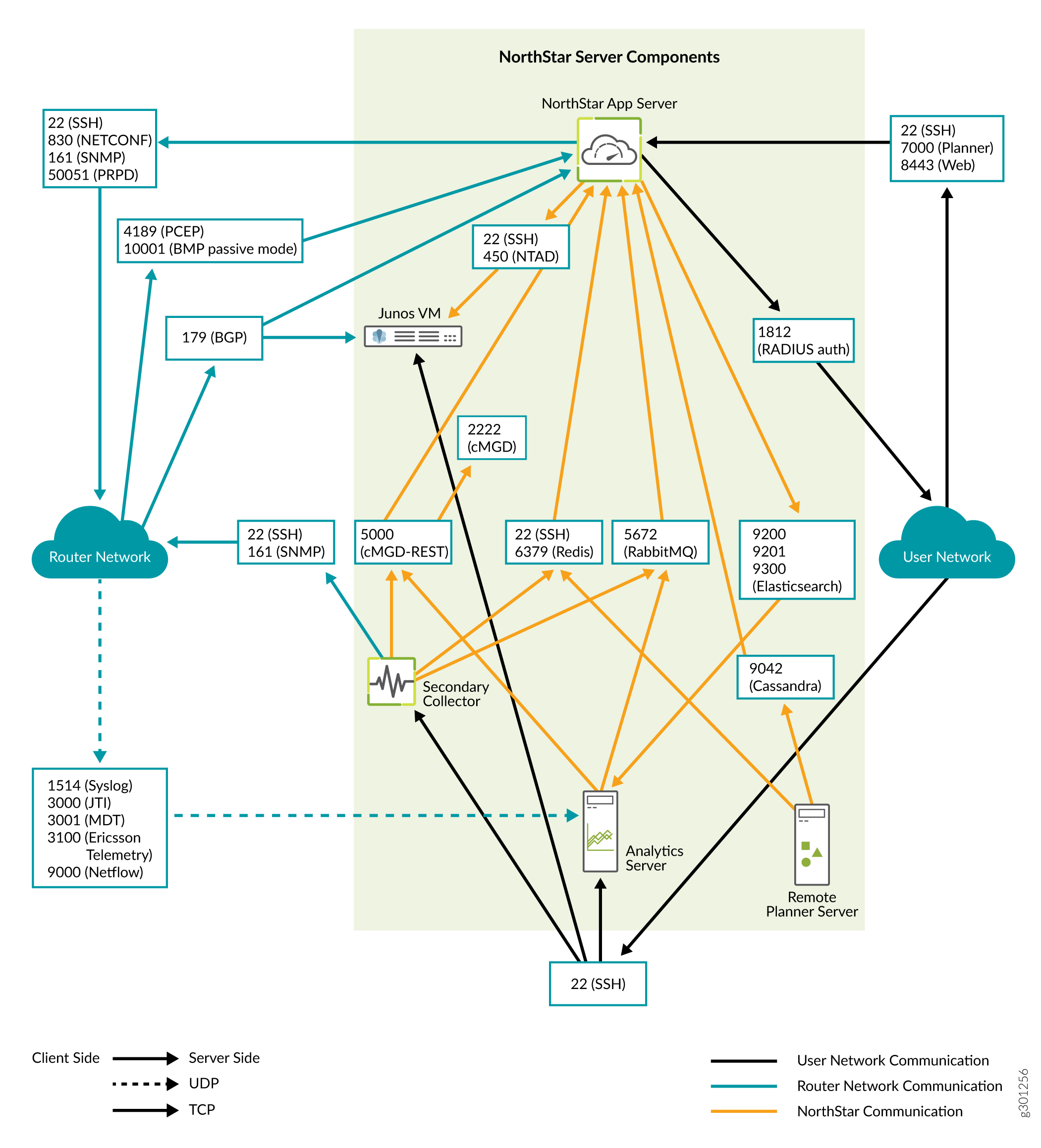 da porta principal northstar
da porta principal northstar
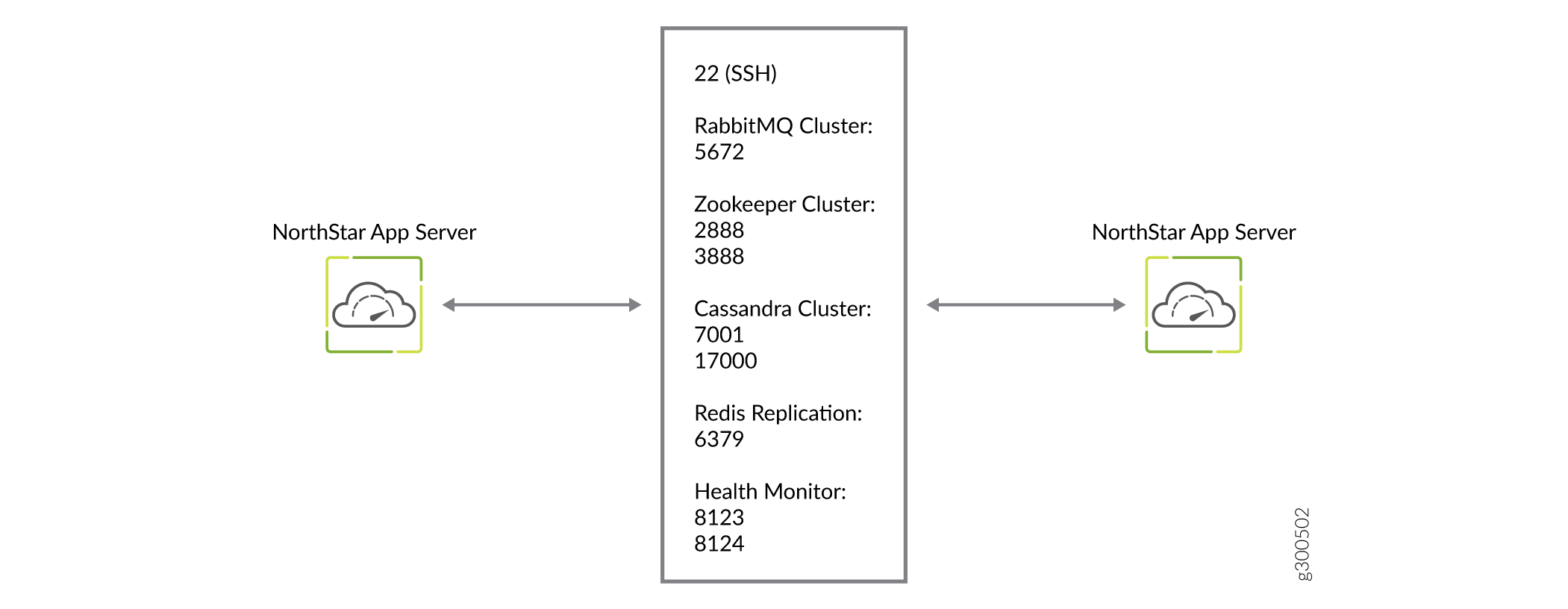 da porta HA do aplicativo NorthStar
da porta HA do aplicativo NorthStar
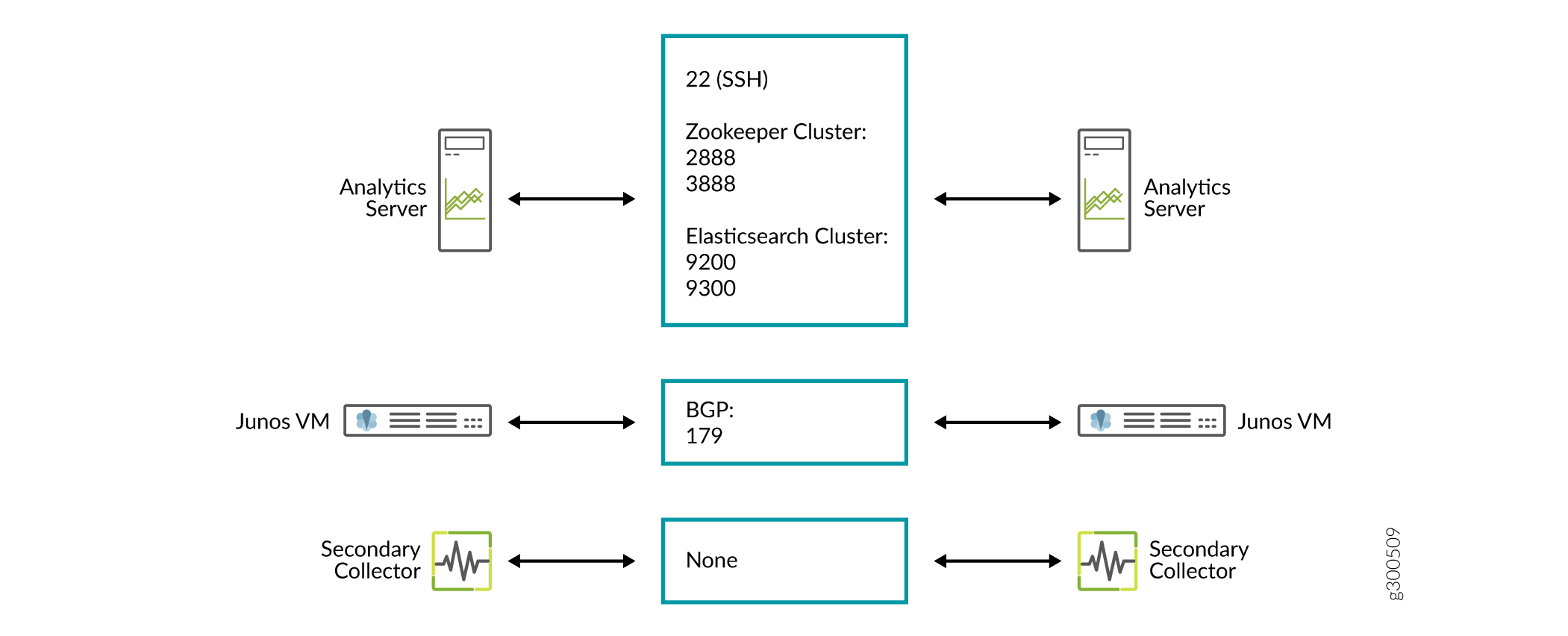 da porta ha de análise
da porta ha de análise
Requisitos de análise
Além de garantir que as portas 3000 e 1514 sejam mantidas abertas, o uso dos recursos de análise northstar exige que você combata os efeitos da filtragem de caminhos reversos (RPF), se necessário. Se o seu kernel fizer RPF por padrão, você deve fazer one o seguinte para rebater os efeitos:
Desativar RPF.
Certifique-se de que haja uma rota para o endereço IP de origem das sondas apontando para a interface onde essas sondas são recebidas.
Especifique a filtragem reversa de modo solto (se o endereço de origem for roteável com alguma das rotas em qualquer uma das interfaces).
Requisitos de instalação de dois VM
Uma instalação de duas VM é uma em que o JunosVM não é empacotado com o software NorthStar Controller.
Requisitos de imagem de VM
O aplicativo NorthStar Controller VM está instalado em cima de uma VM Linux, de modo que o VM linux é necessário. Você pode obter uma imagem de VM do Linux de qualquer uma das seguintes maneiras:
Use a versão genérica fornecida pela maioria dos distribuidores Linux. Normalmente, essas são imagens baseadas em nuvem para uso em um ambiente habilitado para a nuvem e não exigem uma senha. Essas imagens são totalmente compatíveis com o OpenStack.
Crie sua própria imagem de VM. Alguns hipervisores, como DVM genérico, permitem que você crie sua própria imagem de VM. Recomendamos essa abordagem se você não estiver usando o OpenStack e seu hipervisor não oferecer suporte nativo à init na nuvem.
O JunosVM é fornecido no formato Qcow2 quando está dentro do pacote NorthStar Controller. Se você baixar o JunosVM separadamente (não empacotado com o NorthStar) no site de download northstar, ele será fornecido no formato VMDK.
A imagem do JunosVM só é compatível com controladores de disco IDE. Você deve configurar o hipervisor para usar o IDE em vez do tipo de controlador SATA para a imagem do disco JunosVM.
glance image-update --property hw_disk_bus=ide --property hw_cdrom_bus=ide
Requisitos de versão do JunosVM
Se você tiver e quiser continuar usando uma versão do JunosVM com mais de 17,2R1 de versão, você pode mudar a configuração northstar para dar suporte a ele, mas o suporte de roteamento por segmentos não estaria disponível. Veja a instalação do controlador NorthStar para as etapas de configuração.
Requisitos de redes VM
Os seguintes requisitos de rede devem ser atendidos para que a abordagem de instalação de duas VM seja bem sucedida:
Cada VM requer os seguintes NICs virtuais:
Um conectado à rede externa
Uma para a conexão interna entre o aplicativo NorthStar e o JunosVM
Um conectado à rede de gerenciamento se uma interface diferente for necessária entre as interfaces voltadas para o roteador e o cliente
Recomendamos uma rede plana ou roteada sem nenhum NAT para compatibilidade total.
Uma rede virtual com NAT de um para um (geralmente referenciado como um IP flutuante) pode ser usada enquanto o BGP-LS for usado como mecanismo de aquisição de topologia. Se a adjacência IS-IS ou OSPF for necessária, ela deve ser estabelecida em um túnel GRE.
Nota:Uma rede virtual com NAT n-to-one não é suportada.