Monitore a qualidade do serviço de rede usando o RMON
RMON para monitoramento da qualidade do serviço
O monitoramento de saúde e desempenho pode se beneficiar do monitoramento remoto de variáveis SNMP pelos agentes locais de SNMP em execução em cada roteador. Os agentes SNMP comparam os valores de MIB com limiares predefinidos e geram alarmes de exceção sem a necessidade de votação por uma plataforma central de gerenciamento SNMP. Este é um mecanismo eficaz para o gerenciamento proativo, desde que os limites tenham linhas de base determinadas e definidas corretamente. Para obter mais informações, veja RFC 2819, MIB de monitoramento remoto de rede.
Este tópico inclui as seguintes seções:
- Limites de configuração
- Interface de linha de comando RMON
- Tabela de eventos da RMON
- Tabela de alarme RMON
- Solução de problemas RMON
Limites de configuração
Ao definir um limiar crescente e em queda para uma variável monitorada, você pode ser alertado sempre que o valor da variável estiver fora do intervalo operacional permitido. (Veja Figura 1.)
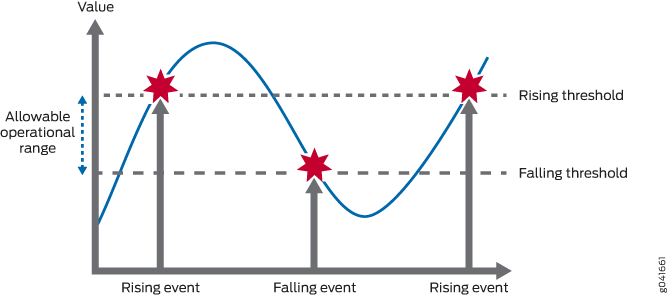
Os eventos só são gerados quando o limiar é cruzado pela primeira vez em qualquer direção, em vez de após cada período de amostra. Por exemplo, se um evento de travessia de limiar crescente for levantado, não ocorrerão mais eventos de travessia de limiar até um evento correspondente de queda. Isso reduz consideravelmente a quantidade de alarmes que são produzidos pelo sistema, tornando mais fácil para a equipe de operações reagir quando os alarmes ocorrem.
Para configurar o monitoramento remoto, especifique as seguintes informações:
A variável a ser monitorada (pelo identificador de objetos SNMP)
O tempo entre cada inspeção
Um limite crescente
Um limiar em queda
Um evento em ascensão
Um evento em queda
Antes de configurar com sucesso o monitoramento remoto, você deve identificar quais variáveis precisam ser monitoradas e seu alcance operacional permitido. Isso requer algum período de base para determinar os intervalos operacionais permitidos. Um período de linha de base inicial de pelo menos três meses não é incomum quando se identifica primeiro as faixas operacionais e define limites, mas o monitoramento da linha de base deve continuar ao longo da vida útil de cada variável monitorada.
Interface de linha de comando RMON
O Junos OS fornece dois mecanismos que você usa para controlar o agente de monitoramento remoto no roteador: interface de linha de comando (CLI) e SNMP. Para configurar uma entrada RMON usando a CLI, inclua as seguintes declarações no nível de [edit snmp] hierarquia:
rmon {
alarm index {
description;
falling-event-index;
falling-threshold;
intervals;
rising-event-index;
rising-threshold;
sample-type (absolute-value | delta-value);
startup-alarm (falling | rising | rising-or-falling);
variable;
}
event index {
community;
description;
type (log | trap | log-and-trap | none);
}
}
Se você não tiver acesso à CLI, poderá configurar o monitoramento remoto usando o SNMP Manager ou o aplicativo de gerenciamento, assumindo que o acesso SNMP foi concedido. (Veja Tabela 1.) Para configurar o RMON usando O SNMP, realize solicitações de SNMP Set para o evento RMON e tabelas de alarme.
Tabela de eventos da RMON
Configure um evento para cada tipo que você deseja gerar. Por exemplo, você pode ter dois eventos genéricos, subindo e caindo, ou muitos eventos diferentes para cada variável que está sendo monitorada (por exemplo, evento de elevação da temperatura , evento de queda da temperatura , evento de impacto de firewall , evento de utilização de interface e assim por diante). Após a configuração dos eventos, você não precisa atualizá-los.
Campo |
Descrição |
|---|---|
|
Descrição do texto deste evento |
|
Tipo de evento (por exemplo, |
|
Grupo trap para o qual enviar este evento (conforme definido na configuração do Junos OS, que não é o mesmo que a comunidade) |
|
Entidade (por exemplo) |
|
Status desta linha (por exemplo, |
Tabela de alarme RMON
A tabela de alarme RMON armazena os identificadores de objetos SNMP (incluindo suas instâncias) das variáveis que estão sendo monitoradas, juntamente com quaisquer limiares de aumento e queda e seus índices de eventos correspondentes. Para criar uma solicitação de RMON, especifique os campos mostrados em Tabela 2.
Campo |
Descrição |
|---|---|
|
Status desta linha (por exemplo, |
|
Período de amostragem (em segundos) da variável monitorada |
|
OID (e instância) da variável a ser monitorada |
|
Valor real da variável amostrada |
|
Tipo de amostra ( |
|
Alarme inicial ( |
|
Limite crescente em relação ao qual comparar o valor |
|
Limiar de queda em relação ao qual comparar o valor |
|
Índice (linha) do evento em ascensão na tabela de eventos |
|
Índice (linha) do evento em queda na tabela de eventos |
Tanto os alarmStatus campos eventStatus são entryStatus primitivos, como definido na RFC 2579, Convenções textuais para SMIv2.
Solução de problemas RMON
Você soluciona problemas do agente RMON, rmopdque é executado no roteador inspecionando o conteúdo do RMON MIB empresarial da Juniper Networks, jnxRmonque fornece as extensões listadas na Tabela 3 RFC 2819 alarmTable.
Campo |
Descrição |
|---|---|
|
Número de vezes em que a solicitação interna |
|
Valor de |
|
Razão pela qual a solicitação |
|
Valor de |
|
Status desta entrada de alarme |
O monitoramento das extensões nesta tabela fornece pistas sobre por que alarmes remotos podem não se comportar como esperado.
Entenda os pontos de medição, os principais indicadores de desempenho e os valores básicos
Este tópico do capítulo fornece diretrizes para o monitoramento da qualidade do serviço de uma rede IP. Ele descreve como provedores de serviços e administradores de rede podem usar informações fornecidas pelos roteadores da Juniper Networks para monitorar o desempenho e a capacidade da rede. Você deve ter uma compreensão completa do SNMP e do MIB associado com o Junos OS.
Para uma boa introdução ao processo de monitoramento de uma rede IP, consulte RFC 2330, Framework for IP Performance Metrics.
Este tópico contém as seguintes seções:
Pontos de medição
Definir os pontos de medição onde as métricas são medidas é igualmente tão importante quanto definir as próprias métricas. Esta seção descreve pontos de medição dentro do contexto deste capítulo e ajuda a identificar onde as medições podem ser tomadas de uma rede de provedor de serviços. É importante entender exatamente onde está um ponto de medição. Os pontos de medição são vitais para entender a implicação do que a medição real significa.
Uma rede IP consiste em uma coleção de roteadores conectados por links físicos que estão todos executando o Protocolo de Internet. Você pode ver a rede como uma coleção de roteadores com um ponto de entrada (entrada) e um ponto de saída (saída). Veja Figura 2.
As medições centradas na rede são feitas em pontos de medição que mapeiam mais de perto os pontos de entrada e saída para a própria rede. Por exemplo, para medir o atraso em toda a rede do provedor do Site A ao Site B, os pontos de medição devem ser o ponto de entrada para a rede do provedor no Site A e o ponto de saída no Site B.
As medições centradas no roteador são tomadas diretamente dos próprios roteadores, mas tenha cuidado para garantir que os subcomponentes corretos do roteador tenham sido identificados com antecedência.
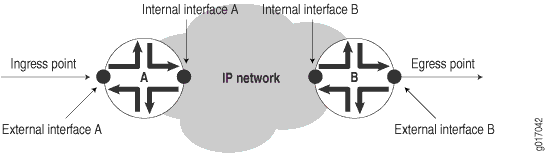
Figura 2 não mostra as redes de clientes nas instalações do cliente, mas elas estariam localizadas em ambos os lados dos pontos de entrada e saída. Embora este capítulo não discuta como medir os serviços de rede percebidos por essas redes clientes, você pode usar medidas feitas para a rede do provedor de serviços como entrada em tais cálculos.
Principais indicadores básicos de desempenho
Por exemplo, você pode monitorar uma rede de provedor de serviços para três indicadores básicos de desempenho chave (KPIs):
mede a "acessibilidade" de um ponto de medição de outro ponto de medição na camada de rede (por exemplo, usando ping de ICMP). A infraestrutura de roteamento e transporte subjacente da rede do provedor oferecerá suporte às medições de disponibilidade, com falhas destacadas como indisponibilidade.
mede o número e o tipo de erros que estão ocorrendo na rede do provedor, e pode consistir em medições centradas no roteador e centradas na rede, como falhas de hardware ou perda de pacotes.
da rede do provedor mede o quão bem ela pode oferecer suporte a serviços IP (por exemplo, em termos de atraso ou utilização).
Configuração das linhas de base
Qual é o desempenho da rede do provedor? Recomendamos um período inicial de monitoramento de três meses para identificar os parâmetros operacionais normais de uma rede. Com essas informações, você pode reconhecer exceções e identificar comportamentos anormais. Você deve continuar o monitoramento da linha de base para a vida útil de cada métrica medida. Com o tempo, você deve ser capaz de reconhecer tendências de desempenho e padrões de crescimento.
No contexto deste capítulo, muitas das métricas identificadas não têm um alcance operacional permitido associado a eles. Na maioria dos casos, você não pode identificar o intervalo operacional permitido até que você tenha determinado uma linha de base para a variável real em uma rede específica.
Definir e medir a disponibilidade da rede
Este tópico inclui as seguintes seções:
Definir disponibilidade de rede
A disponibilidade da rede IP de um provedor de serviços pode ser considerada como a acessibilidade entre os pontos de presença regionais (POP), como mostrado em Figura 3.
Com o exemplo acima, quando você usa uma malha completa de pontos de medição, onde cada POP mede a disponibilidade a cada outro POP, você pode calcular a disponibilidade total da rede do provedor de serviços. Esse KPI também pode ser usado para ajudar a monitorar o nível de serviço da rede e pode ser usado pelo provedor de serviços e seus clientes para determinar se eles estão operando dentro dos termos de seu contrato de nível de serviço (SLA).
Quando um POP pode consistir em vários roteadores, faça medições para cada roteador conforme mostrado em Figura 4.
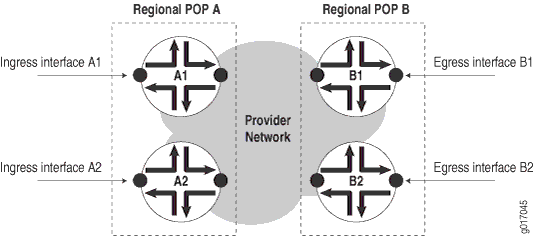
As medições incluem:
Disponibilidade de caminho — disponibilidade de uma interface B1 de saída, como visto de uma interface de entrada A1.
Disponibilidade do roteador — Porcentagem da disponibilidade de caminhos de todos os caminhos medidos que terminam no roteador.
Disponibilidade POP — Porcentagem da disponibilidade do roteador entre quaisquer dois POPs regionais, A e B.
Disponibilidade de rede — Porcentagem da disponibilidade pop para todos os POPs regionais na rede do provedor de serviços.
Para medir a disponibilidade POP de POP A para POP B Figura 4, você deve medir os seguintes quatro caminhos:
Path A1 => B1 Path A1 => B2 Path A2 => B1 Path A2 => B2
Medir a disponibilidade do POP B ao POP A exigiria mais quatro medições e assim por diante.
Uma malha completa de medições de disponibilidade pode gerar tráfego de gerenciamento significativo. No diagrama da amostra acima:
Cada POP tem dois roteadores de borda de provedor (PE) co-localizados, cada um com 2 interfaces STM1, para um total de 18 roteadores PE e 36 interfacesSTM1.
Existem seis roteadores de provedor de núcleo (P), quatro com 2xSTM4 e 3 interfaces STM1 cada, e dois com 3xSTM4 e 3 interfaces STM1 cada.
Isso faz um total de 68 interfaces. Uma malha completa de caminhos entre cada interface é:
[n x (n-l)] / 2 dá [68 x (68-1)] / 2=2278 caminhos
Para reduzir o tráfego de gerenciamento na rede do provedor de serviços, em vez de gerar uma malha completa de testes de disponibilidade de interface (por exemplo, de cada interface para qualquer outra interface), você pode medir a partir do endereço loopback de cada roteador. Isso reduz o número de medições de disponibilidade necessárias para um total de uma para cada roteador, ou:
[n x (n-1)] / 2 dá [24 x (24-1)] / 2=276 medições
Isso mede a disponibilidade de cada roteador para todos os outros roteadores.
Monitoramento do SLA e da largura de banda necessária
Um SLA típico entre um provedor de serviços e um cliente pode afirmar:
A Point of Presence is the connection of two back-to-back provider edge routers to separate core provider routers using different links for resilience. The system is considered to be unavailable when either an entire POP becomes unavailable or for the duration of a Priority 1 fault.
Um número de disponibilidade de SLA de 99,999% para a rede de um provedor estaria relacionado a um tempo de inatividade de aproximadamente 5 minutos por ano. Portanto, para medir isso proativamente, você teria que fazer medições de disponibilidade com uma granularidade de menos de um a cada cinco minutos. Com um tamanho padrão de 64 bytes por solicitação de ping ICMP, um teste de ping por minuto geraria 7680 bytes de tráfego por hora por destino, incluindo respostas de ping. Uma malha completa de testes de ping para 276 destinos geraria 2.119.680 bytes por hora, o que representa o seguinte:
Em um link OC3/STM1 de 155,52 Mbps, uma utilização de 1,362 por cento
Em um link OC12/STM4 de 622,08 Mbps, uma utilização de 0,340 por cento
Com um tamanho de 1500 bytes por solicitação de ping ICMP, um teste de ping por minuto geraria 180.000 bytes por hora por destino, incluindo respostas de ping. Uma malha completa de testes de ping para 276 destinos geraria 49.680.000 bytes por hora, o que representa o seguinte:
Em um link OC3/STM1, 31,94% de utilização
Em um link OC12/STM4, 7,986 por cento de utilização
Cada roteador pode registrar os resultados de cada destino testado. Com um teste por minuto para cada destino, um total de 1 x 60 x 24 x 276 = 397.440 testes por dia seriam realizados e registrados por cada roteador. Todos os resultados de ping são armazenados no pingProbeHistoryTable (ver RFC 2925) e podem ser recuperados por um aplicativo de relatórios de desempenho SNMP (por exemplo, software de gerenciamento de desempenho de serviços da InfoVista, Inc., ou Concord Communications, Inc.) para pós processamento. Esta tabela tem um tamanho máximo de 4.294.967.295 linhas, o que é mais do que adequado.
Medir a disponibilidade
Existem dois métodos que você pode usar para medir a disponibilidade:
Proativo — a disponibilidade é automaticamente medida com a maior frequência possível por um sistema de suporte operacional.
Reativo — A disponibilidade é registrada por um help desk quando uma falha é relatada pela primeira vez por um usuário ou um sistema de monitoramento de falhas.
Esta seção discute o monitoramento de desempenho em tempo real como uma solução de monitoramento proativa.
Monitoramento de desempenho em tempo real
A Juniper Networks oferece um serviço de monitoramento de desempenho (RPM) em tempo real para monitorar o desempenho da rede em tempo real. Use o recurso de configuração rápida J-Web para configurar parâmetros de monitoramento de desempenho em tempo real usados em testes de monitoramento de desempenho em tempo real. (J-Web Quick Configuration é uma GUI baseada em navegador que é executado em roteadores da Juniper Networks. Para obter mais informações, consulte o Guia de usuário da interface J-Web.)
Configuração do monitoramento de desempenho em tempo real
Algumas das opções mais comuns que você pode configurar para testes de monitoramento de desempenho em tempo real são mostradas.Tabela 4
Campo |
Descrição |
|---|---|
| Solicitação de informações | |
|
Tipo de sondagem a ser enviada como parte do teste. Os tipos de sondagem podem ser:
|
|
Tempo de espera (em segundos) entre cada transmissão da sonda. O intervalo é de 1 a 255 segundos. |
|
Tempo de espera (em segundos) entre os testes. O intervalo é de 0 a 86400 segundos. |
|
Número total de sondagens enviadas para cada teste. O intervalo é de 1 a 15 sondas. |
|
Porta TCP ou UDP para a qual as sondas são enviadas. Use o número 7 — um número padrão de porta TCP ou UDP — ou selecione um número de porta de 49152 a 65535. |
|
Bits de ponto de código de serviços diferenciados (DSCP). Esse valor deve ser um padrão válido de 6 bits. O padrão é 000000. |
|
Tamanho (em bytes) da porção de dados das sondas ICMP. A faixa é de 0 a 65507 bytes. |
|
Conteúdo da parte de dados das sondas ICMP. O conteúdo deve ser um valor hexadácimal. A faixa é de 1 a 800h. |
| Limites máximos de sondagem | |
|
Número total de sondagens que devem ser perdidas sucessivamente para desencadear uma falha na sonda e gerar uma mensagem de log do sistema. O intervalo é de 0 a 15 sondas. |
|
Número total de sondagens que devem ser perdidas para desencadear uma falha na sonda e gerar uma mensagem de log do sistema. O intervalo é de 0 a 15 sondas. |
|
Tempo total de ida e volta (em microssegundos) do roteador de serviços até o servidor remoto, que, se excedido, desencadeia uma falha na sonda e gera uma mensagem de log do sistema. A faixa é de 0 a 60.000.000 microssegundos. |
|
Jitter total (em microssegundos) para um teste, que, se excedido, desencadeia uma falha na sonda e gera uma mensagem de log do sistema. A faixa é de 0 a 60.000.000 microssegundos. |
|
Desvio padrão máximo permitido (em microssegundos) para um teste que, se excedido, desencadeia uma falha na sonda e gera uma mensagem de log do sistema. A faixa é de 0 a 60.000.000 microssegundos. |
|
Tempo total de ida (em microssegundos) do roteador até o servidor remoto, o que, se excedido, desencadeia uma falha na sonda e gera uma mensagem de log do sistema. A faixa é de 0 a 60.000.000 microssegundos. |
|
Tempo total de ida (em microssegundos) do servidor remoto até o roteador, o que, se excedido, desencadeia uma falha na sonda e gera uma mensagem de log do sistema. A faixa é de 0 a 60.000.000 microssegundos. |
|
Jitter total de tempo de saída (em microssegundos) para um teste, que, se excedido, desencadeia uma falha na sonda e gera uma mensagem de log do sistema. A faixa é de 0 a 60.000.000 microssegundos. |
|
Jitter total de tempo de entrada (em microssegundos) para um teste, que, se excedido, desencadeia uma falha na sonda e gera uma mensagem de log do sistema. A faixa é de 0 a 60.000.000 microssegundos. |
|
Desvio padrão máximo permitido de tempos de saída (em microssegundos) para um teste que, se excedido, desencadeia uma falha na sonda e gera uma mensagem de log do sistema. A faixa é de 0 a 60.000.000 microssegundos. |
|
Desvio padrão máximo permitido de tempos de entrada (em microssegundos) para um teste que, se excedido, desencadeia uma falha na sonda e gera uma mensagem de log do sistema. A faixa é de 0 a 60.000.000 microssegundos. |
Exibição de informações de monitoramento de desempenho em tempo real
Para cada teste de monitoramento de desempenho em tempo real configurado no roteador, as informações de monitoramento incluem o tempo de ida e volta, o jitter e o desvio padrão. Para visualizar essas informações, selecione Monitor > RPM na interface J-Web ou insira o comando de show services rpm interface de linha de comando (CLI).
Para exibir os resultados das mais recentes sondas de monitoramento de desempenho em tempo real, entre no show services rpm probe-results comando CLI:
user@host> show services rpm probe-results
Owner: p1, Test: t1
Target address: 10.8.4.1, Source address: 10.8.4.2, Probe type: icmp-ping
Destination interface name: lt-0/0/0.0
Test size: 10 probes
Probe results:
Response received, Sun Jul 10 19:07:34 2005
Rtt: 50302 usec
Results over current test:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
Results over all tests:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
Medir a saúde
Você pode monitorar métricas de saúde reativamente usando software de gerenciamento de falhas, como SMARTS InCharge, Micromuse Netcool Omnibus ou Concord Live Exceptions. Recomendamos que você monitore as métricas de saúde mostradas em Tabela 5.
Métrica |
Descrição |
Parâmetros |
|
|---|---|---|---|
Nome |
Value |
||
Erros em |
Número de pacotes de entrada que contivessem erros, impedindo-os de serem entregues |
Nome do MIB | IF-MIB (RFC 2233) |
| Nome variável | seInErrors |
||
| OID variável | .1.3.6.1.31.2.2.1.14 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Interfaces lógicas |
||
Erros fora |
Número de pacotes de saída que contêm erros, impedindo-os de serem transmitidos |
Nome do MIB | IF-MIB (RFC 2233) |
| Nome variável | seOutErrors |
||
| OID variável | .1.3.6.1.31.2.2.1.20 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Interfaces lógicas |
||
Descartes em |
Número de pacotes de entrada descartados, embora nenhum erro tenha sido detectado |
Nome do MIB | IF-MIB (RFC 2233) |
| Nome variável | ifInDiscards |
||
| OID variável | .1.3.6.1.31.2.2.1.13 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Interfaces lógicas |
||
Protocolos desconhecidos |
Número de pacotes de entrada descartados porque eram de um protocolo desconhecido |
Nome do MIB | IF-MIB (RFC 2233) |
| Nome variável | ifInUnknownProtos |
||
| OID variável | .1.3.6.1.31.2.2.1.15 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Interfaces lógicas |
||
Status de operação da interface |
Status operacional de uma interface |
Nome do MIB | IF-MIB (RFC 2233) |
| Nome variável | ifOperStatus |
||
| OID variável | .1.3.6.1.31.2.2.1.8 |
||
| Frequência (min) | 15 |
||
| Alcance permitido | 1 (up) |
||
| Objetos gerenciados | Interfaces lógicas |
||
Estado do caminho comutada por rótulos (LSP) |
Estado operacional de um caminho comutada por rótulos MPLS |
Nome do MIB | MPLS-MIB |
| Nome variável | mplsLspState |
||
| OID variável | mplsLspEntry.2 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | 2 (up) |
||
| Objetos gerenciados | Todos os caminhos comutos de rótulos na rede |
||
Status de operação de componentes |
Status operacional de um componente de hardware do roteador |
Nome do MIB | JUNIPER-MIB |
| Nome variável | jnxOperatingState |
||
| OID variável | .1.3.6.1.4.1.2636.1.13.1.6 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | 2 (em execução) ou 3 (pronto) |
||
| Objetos gerenciados | Todos os componentes de cada roteador da Juniper Networks |
||
Temperatura de operação do componente |
Temperatura operacional de um componente de hardware, em Celsius |
Nome do MIB | JUNIPER-MIB |
| Nome variável | jnxOperatingTemp |
||
| OID variável | .1.3.6.1.4.1.2636.1.13.1.7 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Todos os componentes em um chassi |
||
Tempo de ativação do sistema |
Tempo, em milissegundos, de que o sistema está operacional. |
Nome do MIB | MIB-2 (RFC 1213) |
| Nome variável | sysUpTime |
||
| OID variável | .1.3.6.1.1.3 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | Aumentar apenas (o decremento indica uma reinicialização) |
||
| Objetos gerenciados | Todos os roteadores |
||
Sem erros de rota IP |
Número de pacotes que não podiam ser entregues porque não havia rota IP para o seu destino. |
Nome do MIB | MIB-2 (RFC 1213) |
| Nome variável | ipOutNoRoutes |
||
| OID variável | ip.12 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Cada roteador |
||
Nomes errados da comunidade SNMP |
Número de nomes incorretos da comunidade SNMP recebidos |
Nome do MIB | MIB-2 (RFC 1213) |
| Nome variável | nomes de imunidade snmpInBadCommunity |
||
| OID variável | snmp.4 |
||
| Frequência (min) | 24 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Cada roteador |
||
Violações da comunidade SNMP |
Número de comunidades SNMP válidas usadas para tentar operações inválidas (por exemplo, tentando realizar solicitações de conjunto de SNMP) |
Nome do MIB | MIB-2 (RFC 1213) |
| Nome variável | snmpInBadCommunityUses |
||
| OID variável | snmp.5 |
||
| Frequência (min) | 24 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Cada roteador |
||
Switchover de redundância |
Número total de switches de redundância relatados por esta entidade |
Nome do MIB | JUNIPER-MIB |
| Nome variável | jnxRedundancySwitchoverCount |
||
| OID variável | jnxRedundancyEntry.8 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Todos os roteadores da Juniper Networks com mecanismos de roteamento redundantes |
||
Estado da FRU |
Status operacional de cada unidade substituível em campo (FRU) |
Nome do MIB | JUNIPER-MIB |
| Nome variável | jnxFruState |
||
| OID variável | jnxFruEntry.8 |
||
| Frequência (min) | 15 |
||
| Alcance permitido | 2 a 6 para estados prontos/on-line. Veja jnxFruOfflineReason em caso de falha da FRU. |
||
| Objetos gerenciados | Todas as FRUs em todos os roteadores da Juniper Networks. |
||
Taxa de pacotes com queda de cauda |
Taxa de pacotes perdidos por fila de saída por fila de saída, por classe de encaminhamento, por interface. |
Nome do MIB | JUNIPER-COS-MIB |
| Nome variável | jnxCosIfqTailPktRate |
||
| OID variável | jnxCosIfqStatsEntry.12 |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Para cada classe de encaminhamento por interface na rede do provedor, quando o CoS estiver habilitado. |
||
Utilização de interface: octets recebidos |
Número total de octets recebidos na interface, incluindo caracteres de estrutura. |
Nome do MIB | IF-MIB |
| Nome variável | ifInOctets |
||
| OID variável | .1.3.6.1.2.1.2.2.1.10.x |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Todas as interfaces operacionais da rede |
||
Utilização de interface: octets transmitidos |
Número total de octets transmitidos para fora da interface, incluindo caracteres de estrutura. |
Nome do MIB | IF-MIB |
| Nome variável | seOutOctets |
||
| OID variável | .1.3.6.1.2.1.2.2.1.16.x |
||
| Frequência (min) | 60 |
||
| Alcance permitido | A ser base |
||
| Objetos gerenciados | Todas as interfaces operacionais da rede |
||
As contagens de byte variam dependendo do tipo de interface, encapsulamento usado e suporte ao PIC. Por exemplo, com o encapsulamento vlan-ccc em um PIC de 4x, GE ou GE 1Q, a contagem de byte inclui a sobrecarga de palavras de enquadramento e controle. (Veja Tabela 6.)
Tipo PIC |
Encapsulação |
entrada (nível de unidade) |
Saída (nível de unidade) |
SNMP |
|---|---|---|---|---|
4xFE |
vlan-ccc |
Quadro (sem sequência de verificação de quadros [FCS]) |
Quadro (incluindo FCS e palavra de controle) |
ifInOctets, seOutOctets |
GE |
vlan-ccc |
Quadro (sem FCS) |
Quadro (incluindo FCS e palavra de controle) |
ifInOctets, seOutOctets |
GE IQ |
vlan-ccc |
Quadro (sem FCS) |
Quadro (incluindo FCS e palavra de controle) |
ifInOctets, seOutOctets |
As armadilhas SNMP também são um bom mecanismo de uso para o gerenciamento da saúde. Para obter mais informações, veja "Armadilhas SNMP apoiadas pelo Junos OS" e "Armadilhas SNMP específicas para empresas apoiadas pelo Junos OS".
Medir o desempenho
O desempenho da rede de um provedor de serviços é geralmente definido como o quão bem ele pode oferecer suporte aos serviços, e é medido com métricas como atraso e utilização. Sugerimos que você monitore as seguintes métricas de desempenho usando aplicativos como o Gerenciamento de desempenho de serviços do InfoVista ou o Concord Network Health (ver Tabela 7).
| Métrica: | Atraso médio |
Descrição |
Tempo médio de ida e volta (em milissegundos) entre dois pontos de medição. |
Nome do MIB |
DISMAN-PING-MIB (RFC 2925) |
Nome variável |
|
OID variável |
pingResultsEntry.6 |
Frequência (min) |
15 (ou dependendo da frequência do teste de ping) |
Alcance permitido |
A ser base |
Objetos gerenciados |
Cada caminho medido na rede |
| Métrica: | Utilização de interface |
Descrição |
Porcentagem de utilização de uma conexão lógica. |
Nome do MIB |
IF-MIB |
Nome variável |
( |
OID variável |
entradas ifTable |
Frequência (min) |
60 |
Alcance permitido |
A ser base |
Objetos gerenciados |
Todas as interfaces operacionais da rede |
| Métrica: | Utilização de disco |
Descrição |
Utilização de espaço em disco dentro do roteador Juniper Networks |
Nome do MIB |
HOST-RESOURCES-MIB (RFC 2790) |
Nome variável |
hrStorageSize – hrStorageUsed |
OID variável |
hrStorageEntry.5 – hrStorageEntry.6 |
Frequência (min) |
1440 |
Alcance permitido |
A ser base |
Objetos gerenciados |
Todos os discos rígidos do mecanismo de roteamento |
| Métrica: | Utilização de memória |
Descrição |
Utilização da memória no mecanismo de roteamento e FPC. |
Nome do MIB |
JUNIPER-MIB (Chassis MIB empresarial da Juniper Networks) |
Nome variável |
jnxOperatingHeap |
OID variável |
Tabela para cada componente |
Frequência (min) |
60 |
Alcance permitido |
A ser base |
Objetos gerenciados |
Todos os roteadores da Juniper Networks |
| Métrica: | Carga de CPU |
Descrição |
Utilização média no último minuto de uma CPU. |
Nome do MIB |
JUNIPER-MIB (Chassis MIB empresarial da Juniper Networks) |
Nome variável |
jnxOperatingCPU |
OID variável |
Tabela para cada componente |
Frequência (min) |
60 |
Alcance permitido |
A ser base |
Objetos gerenciados |
Todos os roteadores da Juniper Networks |
| Métrica: | Utilização de LSP |
Descrição |
Utilização do caminho comutada por rótulos MPLS. |
Nome do MIB |
MPLS-MIB |
Nome variável |
mplsPathBandwidth / (mplsLspOctets * 8) |
OID variável |
mplsLspEntry.21 e mplsLspEntry.3 |
Frequência (min) |
60 |
Alcance permitido |
A ser base |
Objetos gerenciados |
Todos os caminhos comutos de rótulos na rede |
| Métrica: | Tamanho da fila de saída |
Descrição |
Tamanho, em pacotes, de cada fila de saída por classe de encaminhamento, por interface. |
Nome do MIB |
JUNIPER-COS-MIB |
Nome variável |
jnxCosIfqQedPkts |
OID variável |
jnxCosIfqStatsEntry.3 |
Frequência (min) |
60 |
Alcance permitido |
A ser base |
Objetos gerenciados |
Para cada classe de encaminhamento por interface na rede, assim que o CoS estiver habilitado. |
Esta seção inclui os seguintes tópicos:
- Meça a classe de serviço
- Contadores de filtro de firewall de entrada por classe
- Monitore bytes de saída por fila
- Calcule a queda de tráfego
Meça a classe de serviço
Você pode usar mecanismos de classe de serviço (CoS) para regular como determinadas classes de pacotes são tratadas em sua rede durante os momentos de pico de congestionamento. Normalmente, você deve executar as seguintes etapas ao implementar um mecanismo CoS:
Identificar o tipo de pacotes que é aplicado a esta classe. Por exemplo, inclua todo o tráfego do cliente a partir de uma interface de borda de entrada específica em uma classe, ou inclua todos os pacotes de um protocolo específico, como voz sobre IP (VoIP).
Identificar o comportamento determinístico necessário para cada classe. Por exemplo, se o VoIP for importante, dê ao tráfego VoIP a maior prioridade em tempos de congestionamento de rede. Por outro lado, você pode rebaixar a importância do tráfego web durante o congestionamento, pois isso pode não afetar muito os clientes.
Com essas informações, você pode configurar mecanismos na entrada da rede para monitorar, marcar e policiar as aulas de tráfego. O tráfego marcado pode então ser tratado de uma maneira mais determinística nas interfaces de saída, normalmente aplicando diferentes mecanismos de fila para cada classe durante os tempos de congestionamento da rede. Você pode coletar informações da rede para fornecer aos clientes relatórios que mostram como a rede está se comportando em tempos de congestionamento. (Veja Figura 5.)
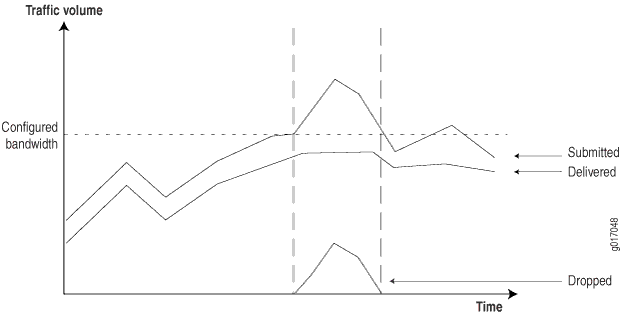
Para gerar esses relatórios, os roteadores devem fornecer as seguintes informações:
Tráfego enviado — Quantidade de tráfego recebido por classe.
Tráfego entregue — Quantidade de tráfego transmitido por classe.
Tráfego em queda — A quantidade de tráfego caiu devido aos limites da CoS.
A seção a seguir descreve como essas informações são fornecidas pelos roteadores da Juniper Networks.
Contadores de filtro de firewall de entrada por classe
Os contadores de filtro de firewall são um mecanismo muito flexível que você pode usar para combinar e contar tráfego de entrada por classe, por interface. Por exemplo:
firewall {
filter f1 {
term t1 {
from {
dscp af11;
}
then {
# Assured forwarding class 1 drop profile 1 count inbound-af11;
accept;
}
}
}
}
Por exemplo, Tabela 8 mostra filtros adicionais usados para combinar com as outras classes.
Valor do DSCP |
Condição de correspondência do firewall |
Descrição |
|---|---|---|
10 |
af11 |
Perfil de queda de classe 1 de encaminhamento garantido 1 |
12 |
af12 |
Perfil de queda de classe 1 de encaminhamento garantido 2 |
18 |
af21 |
Melhor perfil de queda de classe 2 de esforço 1 |
20 |
af22 |
Melhor perfil de queda de classe 2 de esforço 2 |
26 |
af31 |
Melhor perfil de queda de classe 3 de esforço 1 |
Qualquer pacote com um ponto de código CoS DiffServ (DSCP) em conformidade com o RFC 2474 pode ser contado dessa forma. O MIB do filtro de firewall específico para empresas da Juniper Networks apresenta as informações contrárias nas variáveis mostradas em Tabela 9.
Nome do indicador |
Contadores de entrada |
|---|---|
MIB |
|
Mesa |
|
Índice |
|
Variáveis |
|
Descrição |
Número de bytes sendo contados relativos ao contador de filtros de firewall especificado |
Versão SNMP |
SNMPv2 |
Essas informações podem ser coletadas por qualquer aplicativo de gerenciamento SNMP que ofereça suporte ao SNMPv2. Produtos de fornecedores como Concord Communications, Inc., e InfoVista, Inc., fornecem suporte para o Juniper Networks Firewall MIB com seus drivers de dispositivos nativos da Juniper Networks.
Monitore bytes de saída por fila
Você pode usar o ATM CoS MIB empresarial da Juniper Networks para monitorar o tráfego de saída, por classe de encaminhamento de circuito virtual, por interface. (Veja Tabela 10.)
Nome do indicador |
Contadores de saída |
|---|---|
MIB |
|
Variável |
|
Índice |
|
Descrição |
Número de bytes pertencentes à classe de encaminhamento especificada que foram transmitidos no circuito virtual especificado. |
Versão SNMP |
SNMPv2 |
Os contadores de interface não-ATM são fornecidos pelo CoS MIB específico para empresas da Juniper Networks, que fornece informações mostradas em Tabela 11.
Nome do indicador |
Contadores de saída |
|---|---|
MIB |
|
Mesa |
|
Índice |
|
Variáveis |
|
Descrição |
Número de bytes ou pacotes transmitidos por interface por classe de encaminhamento |
Versão SNMP |
SNMPv2 |
Calcule a queda de tráfego
Você pode calcular a quantidade de tráfego perdido subtraindo o tráfego de saída do tráfego de entrada:
Dropped = Inbound Counter – Outbound Counter
Você também pode selecionar contadores do CoS MIB, conforme mostrado em Tabela 12.
Nome do indicador |
Tráfego perdido |
|---|---|
MIB |
|
Mesa |
|
Índice |
|
Variáveis |
|
Descrição |
O número de pacotes com queda de cauda ou red-drop por interface por classe de encaminhamento |
Versão SNMP |
SNMPv2 |