Outras configurações de MC-LAG
Configuração de pontes ativas e VRRP sobre IRB na agregação de enlaces multichassis em roteadores da Série MX
As seções a seguir descrevem a configuração de ponte ativa ativa e VRRP sobre IRB em uma agregação de enlace multichassis (MC-LAG) :
- Configuração do MC-LAG
- Configuração do link de proteção de enlaces entrechassis
- Configuração de vários chassis
- Configuração da ID de serviço
- Configuração do IGMP Snooping para o MC-LAG ativo-ativo
Configuração do MC-LAG
Um MC-LAG é composto por grupos de agregação de enlaces lógicos (LAGs) e é configurado sob a hierarquia [editar interfaces aeX] , da seguinte forma:
[edit]
interfaces {
ae0 {
encapsulation ethernet-bridge;
multi-chassis-protection {
peer 10.10.10.10 {
interface ge-0/0/0;
}
}
aggregated-ether-options {
mc-ae {
mode active-active; # see note below
}
}
}
}
A declaração ativa do modo só é válida se o encapsulamento for uma ponte ethernet ou uma ponte vlan estendida.
Use a declaração de modo para especificar se um MC-LAG está ativo em espera ou ativo. Se a conexão ICCP estiver ativa e a ICL aparecer, o roteador configurado como standby traz à tona as interfaces Ethernet agregadas de multichassis compartilhadas com o peer.
Usar a proteção multi-chassi no nível da interface física é uma maneira de reduzir a configuração no nível de interface lógica.
Se houver interfaces lógicas n+1 sob ae0, de ae0.0 a ae0.n, existem interfaces lógicas n+1 sob ge-0/0/0 também, desde ge-0/0/0.0 até ge-0/0/0.n, cada interface lógica ge-0/0 é um link de proteção para a interface lógica ae0.
Um domínio de ponte não pode ter interfaces lógicas Ethernet agregadas por multichassis que pertencem a diferentes grupos de redundância.
Configuração do link de proteção de enlaces entrechassis
O link de proteção de enlaces de interchassis (ICL-PL) oferece redundância quando ocorre uma falha no enlace (por exemplo, uma falha no tronco MC-LAG) em um dos links ativos. O ICL-PL é uma interface Ethernet agregada. Você pode configurar apenas um ICL-PL entre os dois pares, embora você possa configurar vários MC-LAGs entre eles.
O ICL-PL assume que a interface ge-0/0/0.0 é usada para proteger a interface ae0.0 do MC-LAG-1:
[edit]
interfaces {
ae0 {
....
unit 0 {
multi-chassis-protection {
peer 10.10.10.10 {
interface ge-0/0/0.0;
}
....
}
...
}
}
}
A interface de proteção pode ser uma interface do tipo Ethernet, como ge ou xe, ou uma interface Ethernet agregada (ae).
Configuração de vários chassis
Uma hierarquia de alto nível é usada para especificar uma configuração relacionada à multichassis da seguinte forma:
[edit]
multi-chassis {
multi-chassis-protection {
peer 10.10.10.10 {
interface ge-0/0/0;
}
}
}
Este exemplo especifica a interface ge-0/0/0 como a interface de proteção multichassis para todas as interfaces Ethernet agregadas de multichasse que também fazem parte do peer. Isso pode ser substituído especificando a proteção no nível da interface física e no nível lógico da interface.
Configuração da ID de serviço
Você deve configurar a mesma configuração exclusiva em toda a rede para um serviço no conjunto de roteadores PE que fornecem o serviço. Você pode configurar os IDs de serviço no nível das hierarquias mostrados nos seguintes exemplos:
Configuração global (sistema lógico padrão)
switch-options {
service-id 10;
}
bridge-domains {
bd0 {
service-id 2;
}
}
routing-instances {
r1 {
switch-options {
service-id 10;
}
bridge-domains {
bd0 {
service-id 2;
}
}
}
}
Sistemas lógicos
ls1 {
switch-options {
service-id 10;
}
routing-instances {
r1 {
switch-options {
service-id 10;
}
}
}
}
O uso de um nome de serviço por domínio de ponte não é compatível.
A ID de serviço de nível de ponte é necessária para vincular domínios de ponte relacionados entre pares, e deve ser configurada com o mesmo valor. Os valores de id de serviço compartilham o espaço do nome em todas as instâncias de ponte e roteamento, e entre pares. Assim, os valores duplicados para IDs de serviço não são permitidos nessas entidades.
O ID de serviço no nível de domínio da ponte é obrigatório para domínios de ponte VLAN tipo não únicos. O ID de serviço é opcional para domínios de ponte com um identificador VLAN (VID) definido. Se nenhum ID de serviço for definido neste último caso, ele será captado na configuração de ID de serviço para essa instância de roteamento.
Quando esta instância de roteamento padrão (ou qualquer outra instância de roteamento) que contém um domínio de ponte contendo uma interface Ethernet agregada multichassis for configurada, você deve configurar uma id numberde serviço de opções de switch de nível global, independentemente de os domínios de ponte contidos terem IDs de serviço específicos configurados.
Na ilustração da amostra mostrada na Figura 1, as instâncias de roteamento de rede N1 e N2, ambas para o mesmo ID de serviço, estão configuradas com o mesmo ID de serviço em N1 e N2. O uso de uma string de nome em vez de um número não é suportado.
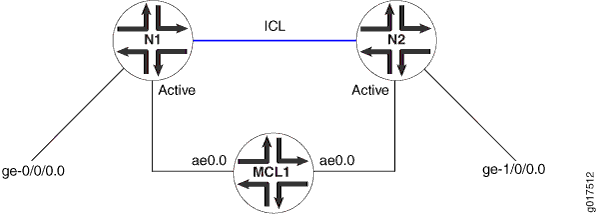
As seguintes restrições de configuração aplicam-se:
O ID de serviço deve ser configurado quando a interface Ethernet agregada multichassis estiver configurada e uma interface lógica Ethernet agregada de multichassis faz parte de um domínio de ponte. Esse requisito é aplicado.
Um único domínio de ponte não pode corresponder a dois IDs de grupo de redundância.
Na Figura 2, é possível configurar um domínio de ponte que consiste em interfaces lógicas a partir de duas interfaces Ethernet agregadas de multichassis e mapeá-las para um ID de grupo de redundância separado, que não é suportado. Um serviço deve ser mapeado um a um com o grupo de redundância que fornece o serviço. Esse requisito é aplicado.
Figura 2: Domínio de ponte com interfaces lógicas de duas interfaces de ethernet agregadas multichassis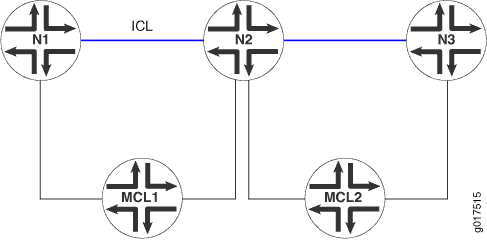
Para exibir a configuração de Ethernet agregada multichassis, use o comando de interfaces mc-aeshow. Para obter mais informações, veja o CLI Explorer.
Configuração do IGMP Snooping para o MC-LAG ativo-ativo
Para que a solução multicast funcione, o seguinte deve ser configurado:
O link de proteção multichassis deve ser configurado como uma interface voltada para o roteador.
[edit bridge-domain bd-name] protocols { igmp-snooping { interface ge-0/0/0.0 { multicast-router-interface; } } }Neste exemplo, ge-0/0/0.0 é uma interface de ICL.
As
multichassis-lag-replicate-stateopções de declaração devem ser configuradas sob amulticast-snooping-optionsdeclaração para esse domínio de ponte.
Bisbilhotar com MC-LAG ativo e ativo só é suportado no modo não proxy.
Configuração do IGMP Snooping no modo ativo-ativo MC-LAG
Você pode usar a opção bridge-domain da service-id declaração para especificar a configuração Ethernet agregada multichassis em roteadores MX240, roteadores MX480, roteadores MX960 e switches da Série QFX.
A
service-iddeclaração é obrigatória para domínios de ponte do tipo VLAN não únicos (nenhum, todos ou vlan-id-tags:dual).A declaração é opcional para domínios de ponte com um VID definido.
O nível
service-idde ponte é necessário para conectar domínios de ponte relacionados entre pares, e deve ser configurado com o mesmo valor.Os
service-idvalores compartilham o espaço do nome em todas as instâncias de ponte e roteamento, e entre pares. Assim, valores duplicadosservice-idnão são permitidos entre essas entidades.Uma mudança de id de serviço de ponte é considerada catastrófico, e o domínio da ponte é alterado.
Esse procedimento permite habilitar ou desabilitar o recurso de replicação.
Para configurar a espionagem de IGMP no modo ativo-ativo MC-LAG:
Configuração de switchover manual e automático de enlaces para interfaces MC-LAG em roteadores da Série MX
Em uma topologia de agregação de enlaces multichassis (MC-LAG) com modo de espera ativa, uma switchover de link só acontece se o nó ativo cair. Você pode anular esse comportamento padrão configurando uma interface MC-LAG no modo de espera ativa para reverter automaticamente para um nó preferido. Com essa configuração, você pode acionar um switchover de link para um nó preferido mesmo quando o nó ativo estiver disponível. Por exemplo, considere dois nós, PE1 e PE2. O PE1 está configurado no modo ativo, tornando-o um nó preferido, e o PE2 está configurado no modo de espera ativa. Em caso de falha no PE1, o PE2 torna-se o nó ativo. No entanto, assim que o PE1 estiver disponível novamente, um switchover de link automático é acionado e o controle é trocado de volta para PE1, embora o PE2 esteja ativo.
Você pode configurar o switchover do link em dois modos: reversivo e nãoevertivo. No modo reversivo, o switchover do link é acionado automaticamente usando o comando do request interface mc-ae switchover modo operacional. No modo nãoevertivo, o switchover do link deve ser acionado manualmente pelo usuário. Você também pode configurar um tempo de reversão que aciona um switchover automático ou manual quando o temporizador especificado expirar.
Se dois dispositivos MC-LAG configurados em uma configuração de espera ativa usando o Protocolo de Controle Inter-Chassis (ICCP) e o modo de codificação de switch não evertivo forem configurados nas interfaces Ethernet agregadas dos MC-LAGs e quando ambas as interfaces mc-ae estiverem vinculadas com uma configuração local de comutação local de circuito de Camada 2, recomendamos que você realize a
request interface mc-ae switchover (immediate mcae-id mcae-id | mcae-id mcae-id)transição entrando na rede comando de modo operacional em apenas uma das interfaces Ethernet agregadas de um dispositivo MC-LAG. Esse comando só pode ser emitido em dispositivos MC-LAG que são configurados como nós ativos (usando astatus-control activedeclaração no nível de[edit interfaces aeX aggregated-ether-options mc-ae]hierarquia).No modo de switchover não evertivo, quando uma interface MC-LAG faz a transição para o estado de espera por causa de uma falha no link do membro MC-LAG e outra interface MC-LAG se move para o estado ativo, o MC-LAG em estado de espera permanece nesse estado até que o MC-LAG no estado ativo encontre uma falha e retorne ao estado ativo.
Se você realizar uma transição em ambas as interfaces Ethernet agregadas no MC-LAG, devido à configuração local de comutação local do circuito de Camada 2, uma transição em uma interface Ethernet agregada desencadeia uma transição na outra interface Ethernet agregada. Nesse cenário, ambas as interfaces Ethernet agregadas se movem para o estado de espera e depois voltam para o estado ativo. Portanto, você não deve realizar switchover em ambas as interfaces Ethernet agregadas em um MC-LAG ao mesmo tempo.
A configuração de circuito de camada 2 e as funcionalidades VPLS não são suportadas se você configurar uma interface MC-LAG para estar no modo de transição reversiva. Você pode configurar o recurso de switchover reversivo ou nãoevertivo apenas se dois dispositivos MC-LAG estiverem configurados em uma configuração de espera ativa (um dispositivo definido como um nó ativo usando a
status-control standbydeclaração e o outro dispositivo definido como um nó de espera usando astatus-control activedeclaração no nível de[edit interfaces aeX aggregated-ether-options mc-ae]hierarquia. Você pode realizar uma troca entrando no comando dorequest interface mc-ae switchover (immediate mcae-id mcae-id | mcae-id mcae-id)modo operacional apenas em dispositivos MC-LAG configurados como nós ativos.
Para configurar o mecanismo de switchover de link em uma interface MC-LAG:
Você pode usar o show interfaces mc-ae revertive-info comando para visualizar as informações de configuração do switchover.
Forçando os links ou interfaces MC-LAG com capacidade de LACP limitado para estar em alta
Em uma rede MC-LAG, um link de cliente MC-LAG sem a configuração do Link Access Control Protocol (LACP) permanece desativado e não pode ser acessado pelos switches MC-LAG.
Para garantir que o dispositivo cliente com capacidade de LACP limitado esteja ativo e acessível na rede MC-LAG, configure um dos links ou interfaces Ethernet agregados em um switch MC-LAG para ativar usando a force-up declaração no nível de hierarquia apropriado em seu dispositivo:
[edit interfaces interface-name aggregated-ether-options lacp]
Você pode configurar o recurso de força nos switches MC-LAG no modo ativo ou no modo de espera. No entanto, para evitar quedas duplicadas de tráfego e pacotes, você configura o recurso de force-up apenas em um link Ethernet agregado dos switches MC-LAG. Se vários links Ethernet agregados estiverem ativados nos switches MC-LAG com recurso de força configurado, o dispositivo selecionará o link com base no ID da porta LACP e na prioridade da porta. A porta com a menor prioridade é dada preferência. No caso de duas portas com a mesma prioridade, é dada preferência à única com a menor ID de porta.
A opção force-up não é suportada em switches QFX10002.
No switch QFX5100, você pode configurar o recurso force-up no Link Aggregation Control Protocol (LACP) nos switches MC-LAG a partir do Junos OS Release 14.1X53-D10.
Se o LACP aparecer parcialmente na rede MC-LAG — ou seja, ele aparece em um dos switches MC-LAG e não aparece em outros switches MC-LAG — o recurso de força é desativado.
Cada vez mais entradas de protocolo de descoberta de rede e ARP para topologias aprimoradas de MC-LAG e VXLAN de Camada 3
- Entendendo a necessidade de um aumento nas entradas de ARP e Network Discovery Protocol (NDP)
- Cada vez mais entradas de protocolo de descoberta de rede e ARP para MC-LAG aprimorado usando o transporte IPv4
- Cada vez mais entradas de protocolo de descoberta de rede e ARP para MC-LAG aprimorado usando o transporte IPv6
- Aumento do ARP para gateway EVPN-VXLAN para border-leaf em ponte roteada de borda (ERB) ou spine em ponte roteada centralmente (CRB) para tráfego de locatárioS IPv4
- Aumentando as entradas de protocolo de descoberta de rede e ARP para gateway EVPN-VXLAN para Border-Leaf em Edge Routed Bridge (ERB) ou Spine em Centrally Routed Bridge (CRB) para tráfego de locatárioS IPv6
Entendendo a necessidade de um aumento nas entradas de ARP e Network Discovery Protocol (NDP)
O número de entradas ARP e NDP aumentou para 256.000 para melhorar os cenários aprimorados de MC-LAG e VXLAN de Camada 3.
Aqui estão alguns cenários aprimorados de MC-LAG e VXLAN de Camada 3 em que é necessário um aumento nas entradas ARP e NDP:
Topologia MC-LAG aprimorada com um grande número de interfaces MC-AE que contêm um grande número de membros por chassi.
Topologia spine-leaf não colapsada, na qual os dispositivos leaf operam como gateways de Camada 2 e lidam com o tráfego dentro do VXLAN, e os dispositivos spine operam como gateways de Camada 3 e lidam com o tráfego entre as VXLANs usando interfaces IRB.
Nesse cenário, o aumento das entradas ARP e NDP é necessário no nível spine.
Dispositivos Leaf que operam como gateways de Camada 2 e Camada 3.
Nesse cenário, os dispositivos spine de trânsito oferecem apenas o funcionamento do roteamento de Camada 3, e o número aumentado de entradas ARP e NDP necessárias apenas no nível leaf.
Cada vez mais entradas de protocolo de descoberta de rede e ARP para MC-LAG aprimorado usando o transporte IPv4
Para aumentar o número de entradas ARP e NDP usando o transporte IPv4, siga essas etapas. Recomendamos que você use os valores fornecidos neste procedimento para um desempenho ideal:
Cada vez mais entradas de protocolo de descoberta de rede e ARP para MC-LAG aprimorado usando o transporte IPv6
Para aumentar o número de entradas ARP e Network Discovery Protocol usando o transporte IPv6. Recomendamos que você use os valores fornecidos neste procedimento para um desempenho ideal:
Aumento do ARP para gateway EVPN-VXLAN para border-leaf em ponte roteada de borda (ERB) ou spine em ponte roteada centralmente (CRB) para tráfego de locatárioS IPv4
Para aumentar o número de entradas ARP usando tráfego de locatário IPv4, siga essas etapas. Recomendamos que você use os valores fornecidos neste procedimento para um desempenho ideal:
Aumentando as entradas de protocolo de descoberta de rede e ARP para gateway EVPN-VXLAN para Border-Leaf em Edge Routed Bridge (ERB) ou Spine em Centrally Routed Bridge (CRB) para tráfego de locatárioS IPv6
Para aumentar o número de entradas ARP e Network Discovery Protocol usando o tráfego de locatárioS IPv4 e IPv6, siga essas etapas. Recomendamos que você use os valores fornecidos neste procedimento para um desempenho ideal:
Sincronização e comprometimento de configurações
Para propagar, sincronizar e confirmar alterações de configuração de um dispositivo (Junos Fusion Provider Edge, Junos Fusion Enterprise, switches da Série EX e roteadores da Série MX) para outro, execute as seguintes tarefas:
- Configure dispositivos para sincronização de configuração
- Criar um grupo de configuração global
- Crie um grupo de configuração local
- Crie um grupo de configuração remota
- Crie grupos aplicáveis para as configurações locais, remotas e globais
- Sincronização e comprometimento de configurações
- Resolução de problemas de conexões remotas de dispositivos
Configure dispositivos para sincronização de configuração
Configure os nomes de host ou endereços IP para os dispositivos que estarão sincronizando suas configurações, bem como os nomes de usuário e detalhes de autenticação para os usuários que administram a sincronização de configuração. Além disso, habilite uma conexão NETCONF para que os dispositivos possam sincronizar suas configurações. O Secure Copy Protocol (SCP) copia as configurações com segurança entre os dispositivos.
Por exemplo, se você tem um dispositivo local chamado Switch A e deseja sincronizar uma configuração com dispositivos remotos chamados Switch B, Switch C e Switch D, você precisa configurar os detalhes do Switch B, Switch C e Switch D no Switch A.
Para especificar os detalhes da configuração:
Criar um grupo de configuração global
Crie um grupo de configuração global dos dispositivos locais e remotos.
Para criar um grupo de configuração global:
A saída para a configuração é a seguinte:
groups {
global {
when {
peers [ Switch A Switch B Switch C Switch D ];
}
interfaces {
ge-0/0/0 {
unit 0 {
family inet {
address 10.1.1.1/8;
}
}
}
ge-0/0/1 {
ether-options {
802.3ad ae0;
}
}
ge-0/0/2 {
ether-options {
802.3ad ae1;
}
}
ae0 {
aggregated-ether-options {
lacp {
active;
}
}
unit 0 {
family ethernet-switching {
interface-mode trunk;
vlan {
members v1;
}
}
}
}
ae1 {
aggregated-ether-options {
lacp {
active;
system-id 00:01:02:03:04:05;
admin-key 3;
}
mc-ae {
mc-ae-id 1;
redundancy-group 1;
mode active-active;
}
}
unit 0 {
family ethernet-switching {
interface-mode access;
vlan {
members v1;
}
}
}
}
}
switch-options {
service-id 1;
}
vlans {
v1 {
vlan-id 100;
l3-interface irb.100;
}
}
}
}
Crie um grupo de configuração local
Crie um grupo de configuração local para o dispositivo local.
Para criar um grupo de configuração local:
A saída para a configuração é a seguinte:
groups {
local {
when {
peers Switch A;
}
interfaces {
ae1 {
aggregated-ether-options {
mc-ae {
chassis-id 0;
status-control active;
events {
iccp-peer-down {
prefer-status-control-active;
}
}
}
}
}
irb {
unit 100 {
family inet {
address 10.10.10.3/8 {
arp 10.10.10.2 l2-interface ae0.0 mac 00:00:5E:00:53:00;
}
}
}
}
}
multi-chassis {
multi-chassis-protection 10.1.1.1 {
interface ae0;
}
}
}
}
Crie um grupo de configuração remota
Crie um grupo de configuração remota para dispositivos remotos.
Para criar um grupo de configuração remota:
A saída para a configuração é a seguinte:
groups {
remote {
when {
peers Switch B Switch C Switch D
}
interfaces {
ae1 {
aggregated-ether-options {
mc-ae {
chassis-id 1;
status-control standby;
events {
iccp-peer-down {
prefer-status-control-active;
}
}
}
}
}
irb {
unit 100 {
family inet {
address 10.10.10.3/8 {
arp 10.10.10.2 l2-interface ae0.0 mac 00:00:5E:00:53:00;
}
}
}
}
}
multi-chassis {
multi-chassis-protection 10.1.1.1 {
interface ae0;
}
}
}
}
Crie grupos aplicáveis para as configurações locais, remotas e globais
Crie grupos aplicáveis para que as mudanças na configuração sejam herdadas por grupos de configuração locais, remotos e globais. Liste os grupos de configuração por ordem de herança, onde os dados de configuração do primeiro grupo de configuração têm prioridade sobre os dados em grupos de configuração subsequentes.
Quando você aplica os grupos de configuração e emite o commit peers-synchronize comando, alterações são cometidas em dispositivos locais e remotos. Se houver um erro em algum dos dispositivos, uma mensagem de erro será emitida e o commit será encerrado.
Para aplicar os grupos de configuração:
[edit] user@switch# set apply-groups [<name of global configuration group> <name of local configuration group> <name of remote configuration group>]
Por exemplo:
[edit] user@switch# set apply-groups [ global local remote ]
A saída para a configuração é a seguinte:
apply-groups [ global local remote ];Sincronização e comprometimento de configurações
O commit at <"string"> comando não é suportado ao realizar a sincronização de configuração.
Você pode habilitar a peers-synchronize declaração no dispositivo local (ou solicitando) para copiar e carregar sua configuração para o dispositivo remoto (ou respondendo) por padrão. Alternativamente, você pode emitir o commit peers-synchronize comando.
Configure o
commitcomando no local (ou solicitação) para realizar automaticamente umapeers-synchronizeação entre dispositivos.[edit] user@switch# set system commit peers-synchronize
A saída para a configuração é a seguinte:
system { commit { peers-synchronize; } }Emita o
commit peers-synchronizecomando no dispositivo local (ou solicitação).[edit] user@switch# commit peers-synchronize
Resolução de problemas de conexões remotas de dispositivos
Problema
Descrição
Quando você emite o commit comando, o sistema emite a seguinte mensagem de erro:
root@Switch A# commit
error: netconf: could not read hello error: did not receive hello packet from server error: Setting up sessions for peer: 'Switch B' failed warning: Cannot connect to remote peers, ignoring it
A mensagem de erro mostra que há um problema de conexão NETCONF entre o dispositivo local e o dispositivo remoto.
Resolução
Resolução
Verifique se a conexão SSH com o dispositivo remoto (Switch B) está funcionando.
root@Switch A# ssh root@Switch B
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY! Someone could be eavesdropping on you right now (man-in-the-middle attack)! It is also possible that a host key has just been changed. The fingerprint for the ECDSA key sent by the remote host is 21:e8:5a:58:bb:29:8b:96:a4:eb:cc:8a:32:95:53:c0. Please contact your system administrator. Add correct host key in /root/.ssh/known_hosts to get rid of this message. Offending ECDSA key in /root/.ssh/known_hosts:1 ECDSA host key for Switch A has changed and you have requested strict checking. Host key verification failed.A mensagem de erro mostra que a conexão SSH não está funcionando.
Exclua a entrada da chave no diretório /root/.ssh/known_hosts:1 e tente se conectar ao Switch B novamente.
root@Switch A# ssh root@Switch B
The authenticity of host 'Switch B (10.92.76.235)' can't be established. ECDSA key fingerprint is 21:e8:5a:58:bb:29:8b:96:a4:eb:cc:8a:32:95:53:c0. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'Switch A,10.92.76.235' (ECDSA) to the list of known hosts. Password: Last login: Wed Apr 13 15:29:58 2016 from 192.168.61.129 - JUNOS 15.1I20160412_0929_dc-builder Kernel 64-bit FLEX JNPR-10.1-20160217.114153_fbsd-builder_stable_10 At least one package installed on this device has limited support. Run 'file show /etc/notices/unsupported.txt' for details.A conexão com o Switch B foi bem sucedida.
Faça o login do Switch B.
root@Switch B# exit
logout Connection to Switch B closed.Verifique se o NETCONF sobre SSH está funcionando.
root@Switch A# ssh root@Switch B -s netconf
logout Connection to st-72q-01 closed.Password:<hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"><capabilities><capability>urn:ietf:params:netconf:base:1.0</capability><capability>urn:ietf:params:netconf:capability:candidate:1.0</capability>A mensagem de log mostra que a NETCONF sobre SSH foi bem sucedida.
Se a mensagem de erro mostrou que a NETCONF sobre SSH não foi bem sucedida, habilite a NETCONF sobre SSH emitindo o
set system services netconf sshcomando.Crie grupos de configuração para sincronizar se você ainda não o fez.
Você pode emitir o
show | comparecomando para ver se algum grupo de configuração foi criado.root@Switch A# show | compare
Emite o
commitcomando.root@Switch A# commit
[edit chassis] configuration check succeeds commit complete {master:0}[edit]A mensagem de log mostra que o commit foi bem sucedido.