Visão geral da recuperação de desastres
Um cluster Junos Space permite que você mantenha alta disponibilidade e escalabilidade em sua solução de gerenciamento de rede. No entanto, como todos os nós em um cluster precisam estar dentro da mesma sub-rede, eles normalmente são implantados no mesmo data center ou dentro do mesmo campus. Mas você pode recuperar facilmente um cluster de um desastre em um local espelhando a instalação original do Junos Space em um cluster para outro cluster em um local geograficamente diferente. Então, se o local principal do Junos Space falhar devido a um desastre como um terremoto, o outro local pode assumir o controle. Assim, a instalação física da configuração de recuperação de desastres é tipicamente um conjunto de dois clusters geograficamente separados: o local ativo ou principal (ou seja, o local local) e o local de espera ou backup (ou seja, o local remoto).
Quando os requisitos básicos de conectividade e pré-requisitos são atendidos (consulte pré-requisitos para configurar requisitos de recuperação de desastres e conectividade para configurar a recuperação de desastres ), os dados do cluster no local ativo são replicados para o cluster no local de espera em tempo quase real.
Os dados nos bancos de dados MySQL e PgSQL são replicados assíncronamente do site ativo até o site de espera por uma conexão SSL. Os dados do MySQL e pgSQL entre os locais de recuperação de desastres são criptografados usando certificados SSL auto-assinados que são gerados quando a recuperação de desastres é inicializada. Certificado raiz de CA, CRLs, certificados de usuário, scripts, imagens do dispositivo, logs de auditoria arquivados e informações sobre trabalhos programados são replicados no site de espera durante a replicação de dados em tempo real para o site de espera. Os arquivos de base de dados de configuração e rodízio (RRD) são sincronizados periodicamente usando o Secure Copy Protocol (SCP) do site ativo até o site de espera.
O cão de guarda de recuperação de desastres, um mecanismo junos space embutido, monitora a integridade da replicação de banco de dados em todos os locais. Todos os outros serviços (como JBoss, OpenNMS, Apache e assim por diante) não são executados no local de espera até que o site ativo não seja entregue ao local de espera. Um failover para o site de espera é iniciado automaticamente quando o site ativo está desativado. Um algoritmo de arbitragem de dispositivos é usado para determinar qual site deve ser o local ativo para evitar um cenário de cérebro dividido onde ambos os locais tentam estar ativos. Para obter informações sobre o algoritmo de arbitragem do dispositivo, veja Detecção de falhas usando o algoritmo de arbitragem do dispositivo.
As seções a seguir descrevem os requisitos de conectividade para o processo de recuperação de desastres, mecanismos de detecção de falhas e os comandos de recuperação de desastres:
Solução de recuperação de desastres
Depois de configurar e iniciar o processo de recuperação de desastres entre um site ativo e um local de espera, a replicação assíncronos do banco de dados MySQL e PgSQL entre os sites é iniciada. A configuração e os arquivos RRD são suportados até o site de espera por SCP em intervalos de tempo definidos.
O processo de recuperação de desastres não executa a replicação em tempo real do banco de dados de Cassiee no local de espera ou monitora o serviço de Cassie em execução nos nós do Junos Space.
Durante a operação normal da solução de recuperação de desastres, os usuários de GUI e API e os dispositivos gerenciados estão conectados ao site ativo para todos os serviços de gerenciamento de rede. A conectividade entre o local de espera e os dispositivos gerenciados é desativada enquanto o site ativo estiver funcional. Quando o site ativo fica indisponível devido a um desastre, o local de espera fica operacional. Neste momento, todos os serviços no local de espera são iniciados e a conectividade entre o local de espera e os dispositivos gerenciados é estabelecida.
A Figura 1 exibe a solução de recuperação de desastres.
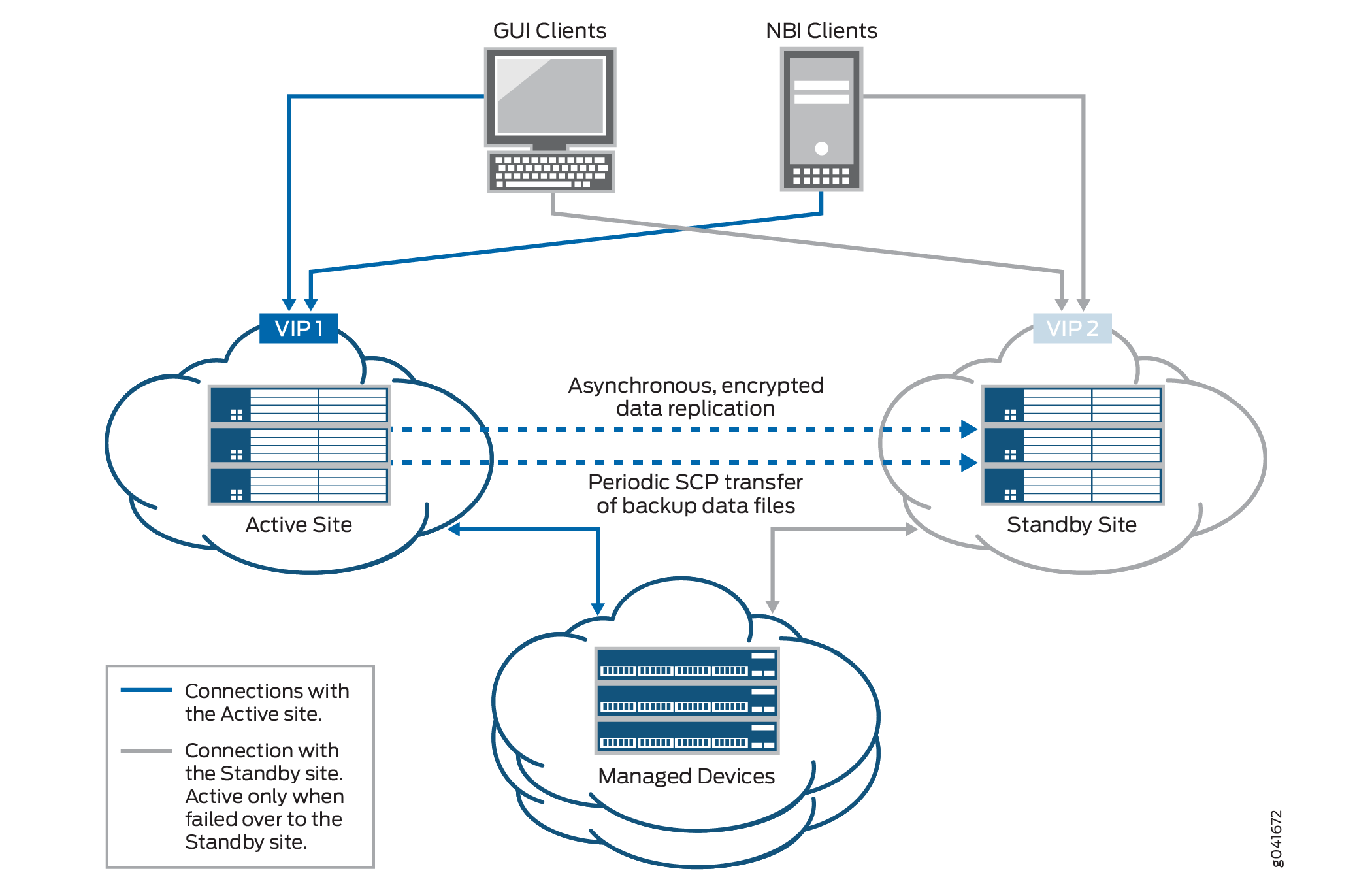
O processo de cão de guarda de recuperação de desastres é iniciado no nó VIP dos locais ativos e de espera para monitorar a integridade do processo de replicação e detectar quando o local remoto cai. O cão de guarda de recuperação de desastres no local local verifica se há problemas de conectividade entre ambos os locais (pingando os nós no local remoto) e se os sites estão conectados a dispositivos árbitros (se você usar o algoritmo de arbitragem do dispositivo).
O cão de guarda de recuperação de desastres em um site realiza as seguintes tarefas para confirmar a conectividade com o local remoto e dispositivos árbitros:
-
Ping no endereço VIP do site remoto em um intervalo configurável regular. O valor padrão do intervalo é de 30 segundos.
Para cada ping, espere uma resposta dentro de um intervalo de tempo limite configurável. O valor padrão para o intervalo de tempo limite é de 5 segundos.
-
Se o site local não receber uma resposta dentro do intervalo de tempo limite, o cão de guarda de recuperação de desastres refrê o ping para um número configurável de vezes. Por padrão, o número de retries é de 4.
-
Se todas as retries falharem, o cão de guarda de recuperação de desastres no site local conclui que o endereço VIP do local remoto não é acessível.
No entanto, o cão de guarda de recuperação de desastres não conclui que o local remoto está desativado porque o local remoto pode estar mudando o endereço VIP para um nó de espera devido a uma switchover local.
-
Para considerar a possibilidade de um switchover de endereço VIP, o cão de guarda de recuperação de desastres pings os endereços IP dos outros nós balanceadores de carga no local remoto. Se o ping em algum dos nós receber uma resposta, o cão de guarda de recuperação de desastres conclui que o local remoto ainda está funcionando.
Se o ping para os nós falhar, o cão de guarda de recuperação de desastres não conclui que o local remoto está desativado. Em vez disso, o cão de guarda da recuperação de desastres considera a possibilidade de problemas de conectividade entre os locais. Ambos os sites tentarão se tornar ativos.
-
Para evitar que ambos os sites tentem se tornar ativos, o cão de guarda de recuperação de desastres inicia o algoritmo de arbitragem de dispositivos e determina se um failover é necessário.
Um failover só é iniciado se a porcentagem de dispositivos árbitros gerenciados pelo site ativo ficar abaixo do limite de failover. Em seguida, o site ativo torna-se o site de espera e o site de espera torna-se o site ativo.
Se a porcentagem de dispositivos árbitros estiver acima do limite de failover, o site de espera permanecerá em espera e o site ativo permanecerá ativo. A porcentagem de dispositivos árbitros gerenciados pelo site ativo é configurável e seu valor padrão é de 50%.
O failover é iniciado se as seguintes condições forem atendidas:
-
O site de espera não pode chegar ao endereço VIP do site ativo ou aos endereços IP de nós de outros nós de balanceamento de carga no site ativo.
-
A porcentagem dos dispositivos árbitros gerenciados pelo site ativo está abaixo do limite de failover.
Para obter mais informações sobre o algoritmo de arbitragem do dispositivo, veja Detecção de falhas usando o algoritmo de arbitragem do dispositivo.
Pré-requisitos para configurar a recuperação de desastres
Você precisa garantir que sua instalação no Junos Space atenda aos seguintes pré-requisitos antes de configurar a recuperação de desastres:
-
O cluster Junos Space no local principal ou ativo (que pode ser um único nó ou vários nós) e o cluster no local remoto ou em espera (que pode ser um único nó ou vários nós) devem ser configurados exatamente da mesma maneira, com todos os mesmos aplicativos, adaptadores de dispositivos, mesmas configurações da família IP, e assim por diante.
-
Ambos os clusters devem ser configurados com informações de servidor SMTP da interface de usuário do Junos Space. Para obter mais informações, veja Gerenciamento de servidores SMTP. Essa configuração permite que os clusters no site ativo e no site de espera notifiquem o administrador por e-mail se as replicações falharem.
O número de nós(s) em site ativo e site de espera deve ser o mesmo.
Requisitos de conectividade para configurar a recuperação de desastres
Você precisa garantir que a solução de recuperação de desastres atenda aos seguintes requisitos de conectividade antes de configurar a recuperação de desastres:
-
Conectividade de camada 3 entre os clusters Junos Space nos locais ativos e de espera. Isso significa:
-
Cada nó em um cluster pode pingar com sucesso o endereço VIP do outro cluster
-
Cada nó em um cluster pode usar SCP para transferir arquivos entre os sites ativos e de espera
-
A replicação de banco de dados nos dois clusters é possível por meio das portas TCP 3306 (replicação de banco de dados MySQL) e 5432 (replicação de banco de dados PostgreSQL)
-
A largura de banda e a latência da conexão entre os dois clusters são de tal forma que a replicação de banco de dados em tempo real é bem sucedida. Embora a largura de banda exata necessária dependa da quantidade de dados transferidos, recomendamos um mínimo de uma conexão de largura de banda de 100 Mbps com uma latência de menos de 150 milissegundos.
-
-
Conectividade independente de Camada 3 entre cada cluster e dispositivos gerenciados
-
Conectividade independente de Camada 3 entre cada cluster e clientes GUI ou NBI
Para configurar o processo de recuperação de desastres, consulte Configurando o processo de recuperação de desastres entre um local ativo e de espera.
Cão de guarda da recuperação de desastres
O cão de guarda de recuperação de desastres, também conhecido como cão de guarda DR, é um mecanismo junos space embutido para monitorar a integridade da replicação de dados (banco de dados MySQL, banco de dados PgSQL, arquivos de configuração e arquivos RRD) em todos os sites. O cão de guarda de recuperação de desastres também monitora a integridade geral da configuração de recuperação de desastres, inicia um failover do local ativo para o standby quando o local ativo falha e permite que o local de espera retome os serviços de gerenciamento de rede com o mínimo de interrupção do serviço. Uma instância do cão de guarda de recuperação de desastres é iniciada no nó VIP em ambos os locais quando você inicia o processo de recuperação de desastres.
O cão de guarda de recuperação de desastres fornece os seguintes serviços:
- batimento cardíaco
- mysqlMonitor
- pgsqlMonitor
- fileMonitor
- arbiterMonitor
- configMonitor
- serviceMonitor
- notificação
batimento cardíaco
O serviço entre os locais ativos e de espera usa ping para verificar a conectividade entre os locais. Ambos os sites enviam mensagens de coração para o outro. O serviço de pulsação executa as seguintes tarefas:
-
Detecte uma falha no local remoto pingando no local remoto em intervalos regulares.
-
Quando o site remoto não responde, descarte a possibilidade de um problema temporário devido a uma falha local no local remoto.
-
Habilite ou desabilite o failover automático dependendo das configurações de configuração de recuperação de desastres.
-
Evite cenários de cérebro dividido executando o algoritmo de arbitragem de dispositivo (padrão) ou a lógica configurada no script personalizado.
-
Verifique a configuração de recuperação de desastres após a reinicialização de um site.
mysqlMonitor
O serviço mysqlMonitor executa as seguintes tarefas:
-
Monitore a integridade da replicação do banco de dados MySQL dentro do site e entre os locais ativos e de espera.
-
Corrija erros de replicação de banco de dados do MySQL.
-
Notifique o administrador por e-mail se algum dos erros de replicação do banco de dados MySQL não puder ser corrigido automaticamente.
pgsqlMonitor
O serviço pgsqlMonitor executa as seguintes tarefas:
-
Monitore a integridade da replicação do banco de dados pgSQL dentro do site e entre os locais ativos e de espera.
-
Corrija erros de replicação de banco de dados pgSQL.
-
Notifique o administrador por e-mail se algum dos erros de replicação do banco de dados pgSQL não puder ser corrigido automaticamente.
fileMonitor
O serviço fileMonitor executa as seguintes tarefas:
-
Monitore a integridade dos arquivos de configuração e arquivos RRD replicados nos sites e entre os locais ativos e de espera.
-
Corrija erros encontrados durante a replicação de arquivos de configuração e arquivos RRD.
-
Notifique o administrador por e-mail se algum dos erros de replicação não puder ser corrigido automaticamente. Você também pode visualizar os erros de replicação na saída do trabalho do cron.
arbiterMonitor
O serviço arbiterMonitor verifica periodicamente se o site local pode pingar todos os dispositivos árbitros. Se a porcentagem de dispositivos árbitros que forem acessáveis ficar abaixo de um limite de aviso configurado (70%, por padrão), uma notificação por e-mail é enviada ao administrador.
configMonitor
O serviço configMonitor executa as seguintes tarefas:
-
Monitore os arquivos de configuração de recuperação de desastres em todos os nós em ambos os locais.
-
Transfira os arquivos de configuração em nós em um site se os arquivos não estiverem em sincronia.
serviceMonitor
O serviçoMonitor executa as seguintes tarefas:
-
Monitore a situação dos serviços selecionados (como jboss, jboss-dc, httpd e dr-watchdog) em um site específico.
-
Inicie ou interrompe os serviços selecionados se eles exibirem um status incorreto.
notificação
O serviço de notificação notifica o administrador sobre condições de erro, avisos ou mudanças de estado de recuperação de desastres detectadas pelo cão de guarda da recuperação de desastres por e-mail. Os e-mails de notificação são enviados se:
-
O failover automático é desativado devido a problemas de conectividade entre um site e dispositivos árbitros.
-
A porcentagem de dispositivos árbitros que podem ser alcançados é menor do que o limite de aviso.
-
Um site fica em espera ou ativo.
-
O site de espera não pode fazer backup de arquivos do site ativo através do SCP.
-
Um site não pode estabelecer uma conexão SSH com o site remoto.
-
O site local não consegue obter o nome de host do nó primário MySQL.
-
Um site não pode corrigir erros de replicação de banco de dados MySQL e PgSQL.
O serviço de notificação não envia e-mails para relatar os mesmos erros em um período configurável de tempo (por padrão, 3600 segundos).
Detecção de falhas usando o algoritmo de arbitragem de dispositivos
Um algoritmo de arbitragem de dispositivos é usado para detectar falhas em um site. Uma lista de dispositivos altamente acessíveis que executam o Junos OS e gerenciados pela Junos Space Platform são selecionados como dispositivos árbitros. Recomendamos que você selecione dispositivos árbitros com base nos seguintes critérios:
-
Você deve ser capaz de alcançar os dispositivos árbitros por meio das conexões SSH iniciadas pelo Junos Space de ambos os locais. Não selecione dispositivos que usam conexões iniciadas por dispositivos com a Junos Space Platform.
-
Você deve ser capaz de ping dispositivos árbitros em ambos os locais de recuperação de desastres.
-
Você deve escolher dispositivos árbitros que permaneçam conectados à Junos Space Platform ou sejam reiniciados ou desativados com menos frequência, pois isso pode afetar os resultados do algoritmo de arbitragem do dispositivo. Se você prever que determinados dispositivos árbitros estarão offline durante alguma parte de suas vidas, evite escolher esses dispositivos.
-
Você deve escolher dispositivos árbitros de diferentes locais geográficos para garantir que um problema na rede de gerenciamento em um local não torne todos os dispositivos árbitros inalcançáveis de seus sites.
-
Você não pode selecionar os dispositivos NAT e ww Junos OS como dispositivos árbitros.
O algoritmo de arbitragem de dispositivos no site ativo usa ping para se conectar a dispositivos árbitros a partir do site ativo. O algoritmo de arbitragem de dispositivos no site de espera faz login nos dispositivos árbitros através de conexões SSH usando as credenciais de login do banco de dados da Junos Space Platform. A seguir, os fluxos de trabalho do algoritmo de arbitragem do dispositivo nos locais ativos e de espera.
No site ativo:
-
Ping todos os dispositivos árbitros selecionados.
-
Compute a porcentagem de dispositivos árbitros que podem ser pingados.
-
Verifique se a porcentagem de dispositivos árbitros que podem ser pingados está acima ou o mesmo que o valor configurado do limiar de failover.
-
Se a porcentagem de dispositivos árbitros conectados estiver acima ou o mesmo que o valor configurado do limiar de failover (failureDetection.threshold.failover na seção watchdog da API de recuperação de desastres), o failover não será iniciado porque o site ativo está gerenciando a maioria dos dispositivos árbitros.
-
Se a porcentagem de dispositivos árbitros estiver abaixo do valor configurado do limiar de failover, o failover será iniciado (se o failover automático for habilitado) e o site ativo ficar em espera. Se o failover automático for desativado, o site ativo permanecerá ativo.
-
No site de espera:
-
Faça login em dispositivos de árbitro através de conexões SSH.
-
Execute um comando em cada dispositivo árbitro para recuperar a lista de conexões SSH a qualquer nó (gerenciado pelo nó) no local ativo.
-
Calcule a porcentagem de dispositivos árbitros gerenciados pelo site ativo.
-
Calcule a porcentagem de dispositivos árbitros que não podem ser alcançados por meio de conexões SSH.
-
Se a porcentagem de dispositivos árbitros gerenciados pelo site ativo estiver acima ou o mesmo que o valor configurado do limite de failover, o failover não é necessário porque o site ativo ainda está gerenciando a maioria dos dispositivos árbitros.
-
Se a porcentagem de dispositivos árbitros gerenciados pelo site ativo estiver abaixo do valor configurado do limiar de failover, o cão de guarda da recuperação de desastres conclui que um failover pode ser necessário.
-
-
No entanto, como os dispositivos que não podem ser alcançados a partir do local de espera podem ser conectados e gerenciados pelo site ativo, o site de espera assume que todos os dispositivos árbitros que não podem ser alcançados estão sendo gerenciados pelo site ativo e calcula a nova porcentagem de dispositivos gerenciados pelo site ativo.
-
Se a porcentagem de dispositivos gerenciados pelo site ativo estiver abaixo da porcentagem limite para ajustar dispositivos gerenciados (failureDetection.threshold.adjustManaged parâmetro na seção watchdog da API de recuperação de desastres, o valor padrão é de 50%), o site de espera permanece em espera. Por padrão, a porcentagem limite para ajustar dispositivos gerenciados deve estar abaixo do limite de failover.
-
Se a nova porcentagem calculada pela inclusão dos dispositivos gerenciados pelo site ativo e dispositivos árbitros que não podem ser alcançados estiver abaixo do limite de failover, o cão de guarda da recuperação de desastres conclui que um failover deve ser iniciado.
Se o failover automático for habilitado, o site de espera inicia o processo de ativação. Se o failover automático for desativado, não haverá falha.
-
Se você desativou o failover automático ou o recurso foi desativado devido a problemas de conectividade, você deve executar jmp-dr manualFailover no local de espera para retomar os serviços de gerenciamento de rede a partir do site de espera.
Detecção de falhas usando os scripts personalizados de detecção de falhas
Além de usar o algoritmo de arbitragem de dispositivos, você pode criar scripts personalizados de detecção de falhas (sh, bash, Perl ou Python) para decidir quando ou se falhará no site de espera. Scripts de falha personalizados invocam o jmp-dr api v1 config ––include comando e buscam a configuração de recuperação de desastres e o status dos serviços de vigilância de recuperação de desastres. A configuração de recuperação de desastres e o status dos serviços de vigilância de recuperação de desastres em um local são organizados como várias seções. A Tabela 1 lista essas seções.
Use a opção de <seção> para visualizar os detalhes de uma seção ou usar os detalhes da seção no script personalizado de detecção de falhas.
| Secção |
Descrição |
Detalhes incluídos na seção |
Saída de amostra |
|---|---|---|---|
| papel |
Função de recuperação de desastres do site atual |
As funções podem ser ativas, de espera ou independentes. |
– |
| failover |
Tipo de failover que aconteceu por último |
O valor pode ser active_to_standby, standby_to_active ou vazio se o failover ainda não tiver acontecido. |
– |
| núcleo |
Configuração de recuperação de desastres do núcleo que inclui os detalhes do nó remoto do site |
peerVip–VIP do balanceador de carga no site remoto adminPass — Senhas de administrador criptografadas do site remoto. Várias entradas são separadas por vírgulas. scpTimeout — Valor de tempo limite usado para detectar falhas de transferência de SCP entre sites peerLoadBalancerNodes — endereços IP de nós dos nós de balanceamento de carga no local remoto. Várias entradas são separadas por vírgulas. peerBusinessLogicNodes — endereços IP de nós dos nós JBoss no local remoto. Várias entradas são separadas por vírgulas. peerDeviceMgtIps — Endereços IP de gerenciamento de dispositivos do site remoto. Várias entradas são separadas por vírgulas. |
{
"core": {
"peerVip": "10.155.90.210",
"adminPass": "ABCDE12345",
"scpTimeout": 120,
"peerLoadBalancerNodes": "10.155.90.211",
"peerBusinessLogicNodes": "10.155.90.211",
"peerDeviceMgtIps": "10.155.90.211"}
}
|
| mysql |
Configuração de recuperação de desastres relacionada ao banco de dados MySQL no site remoto |
temDedicatedDb— Não importa se o site remoto inclui nós dedicados de banco de dados peerVip-VIP dos nós MySQL no site remoto (nó normal ou nó de banco de dados dedicado) peerNodes — endereços IP de nós dos nós MySQL no local remoto (nó normal ou nó DB dedicado). Várias entradas são separadas por vírgulas. |
{ "mysql": {
"hasDedicatedDb": false,
"peerVip": "10.155.90.210",
"peerNodes": "10.155.90.211"
}
}
|
| pgsql |
Configuração de recuperação de desastres relacionada ao banco de dados PgSQL no local remoto |
hasFmpm— Não importa se o local remoto inclui nós especializados de FMPM peerFmpmVip-VIP dos nós postgreSQL no local remoto (nó normal ou nó especializado FM/PM) peerNodes—endereços IP de nós postgreSQL no local remoto (nó normal ou nó especializado FM/PM). Várias entradas são separadas por vírgulas. |
{ "psql": {
"hasFmpm": false,
"peerFmpmVip": "10.155.90.210",
"peerNodes": "10.155.90.211"
}
}
|
| arquivo |
Configuração e arquivos RRD — configuração de recuperação de desastres relacionada no site remoto |
backup.maxCount — Número máximo de arquivos de backup para reter backup.hoursOfDay — Tempos do dia para fazer backup de arquivos backup.daysOfWeek — Dias da semana para fazer backup de arquivos restaurar.horasOfDay —Horários do dia para sondagem de arquivos do site ativo restore.daysOfWeek — Dias da semana para sondagem de arquivos do site ativo |
{ "file": {
"backup": {
"maxCount": 3,
"hoursOfDay": "*",
"daysOfWeek": "*" },
"restore": {
"hoursOfDay": "*",
"daysOfWeek": "*" }
}
}
|
| cão de guarda |
Configuração de recuperação de desastres relacionada ao cão de guarda de recuperação de desastres no local atual |
pulsação.retries — Número de vezes para tentar novamente a mensagem de pulsação o tempo limite —Tempo limite de cada mensagem de pulsação em segundos interval de pulsação —Intervalo de mensagens de pulsação entre sites em segundos notification.email- Entre em contato com o endereço de e-mail para relatar problemas de serviços notificação.intervalo — Umedeça o intervalo entre o recebimento de e-mails sobre os serviços afetados falhaDetection.isCustom — Não importa se o site remoto usa a detecção de falhas personalizada falhaDeteção.script — Caminho do script de detecção de falhas falhaDetection.threshold.failover —Porcentagem de limiar para acionar um failover falhaDetection.threshold.adjustManaged-Threshold percentagem para ajustar a porcentagem de dispositivos gerenciados falhaDetection.threshold.warning — Porcentagem de limiar para enviar um aviso para garantir que um site de recuperação de desastres possa alcançar mais dispositivos árbitros para melhorar a precisão do algoritmo de arbitragem do dispositivo falhaDetection.waitDuration– Período de carência para permitir que o site ativo original se torne ativo novamente quando ambos os locais ficarem em espera falhaDeteção.árbitros — Lista de dispositivos árbitros |
{ "watchdog": {
"heartbeat": {
"retries": 4,
"timeout": 5,
"interval": 30 },
"notification": {
"email": "abc@example.com",
"interval": 3600 },
"failureDetection": {
"isCustom": false,
"script": "/var/cache/jmp-geo/watchdog/bin/arbitration",
"threshold": {
"failover": 0.5,
"adjustManaged": 0.5,
"warning": 0.7 },
"waitDuration": "8h",
"arbiters": [{
"username": "user1",
"password": "xxx",
"host": "10.155.69.114",
"port": 22,
"privateKey": ""
}]
}
}
}
|
| gerenciamento de dispositivos |
Endereços IP de gerenciamento de dispositivos no local remoto |
peerNodes — Endereços IP de gerenciamento de dispositivos do site remoto. Várias entradas são separadas por vírgulas. nós — endereços IP de gerenciamento de dispositivos no site atual. Várias entradas são separadas por vírgulas. endereço IP de gerenciamento de dispositivos ip neste nó (nó no qual o |
{ "deviceManagement": {
"peerNodes": "10.155.90.211",
"nodes": "10.155.90.222",
”ip”: “10.155.90.228,eth0”
}
}
|
| Estados |
Informações em tempo de execução dos serviços de vigilância de recuperação de desastres no local atual. Se o cão de guarda da recuperação de desastres nunca tiver sido executado neste site, esta seção não estará disponível. Se o cão de guarda da recuperação de desastres tiver parado, as informações nesta seção estão desatualizadas. |
– |
{ "states": {
"arbiterMonitor": {
"progress": "idle",
"msg": {
"service": "arbiterMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:18:55+00:00"
},
"service": {}
}, |
"configMonitor": {
"progress": "idle",
"msg": {
"service": "configMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:19:15+00:00"
},"service": {}
},
|
|||
"fileMonitor": {
"progress": "idle",
"msg": {
"service": "fileMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:18:59+00:00"
},
"service": {}
},
|
|||
"heartbeat": {
"progress": "unknown",
"msg": {
"service": "heartbeat",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"localFailover": false
},
"time": "2015-07-18T22:17:49+00:00"
},
"service": {
"booting": false,
"bootEndTime": null,
"waitTime": null,
"automaticFailover": false,
"automaticFailoverEndTime": "2015-07-18T07:41:41+00:00"
}
},
|
|||
"mysqlMonitor": {
"progress": "idle",
"msg": {
"service": "mysqlMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:19:09+00:00"
},
"service": {}
},
|
|||
"pgsqlMonitor": {
"progress": "unknown",
"msg": {
"service": "pgsqlMonitor",
"description": "Master node pgsql in active or standby site maybe CRASHED. Pgsql replication is in bad status. Please manually check Postgresql-9.4 status.",
"state": false,
"force": false,
"progress": "unknown",
"payload": {
"code": 1098
},
"time": "2015-07-18T22:18:27+00:00"
},"service": {}
},
|
|||
"serviceMonitor": {
"progress": "running",
"msg": {
"service": "serviceMonitor",
"description": "",
"state": true,
"force": false,
"progress": "unknown",
"payload": {
"code": 0
},
"time": "2015-07-18T22:19:30+00:00"
},
"service": {}
}
}
} |
A saída do script personalizado informa ao cão de guarda da recuperação de desastres se um failover no local de espera é necessário. O cão de guarda da recuperação de desastres interpreta a saída do script no formato JSON. O exemplo a seguir é:
{
"state": "active",
"action": "nothing",
"description": "",
"payload": {
"waitTime": "",
"details": {
"percentages": {
"connected": 1,
"arbiters": {
"10.155.69.114": "reachable"
}
}
}
}
}
A Tabela 2 descreve os detalhes da saída de script.
| Propriedade |
Descrição |
Tipo de dado |
Valores ou formato |
Outros detalhes |
|---|---|---|---|---|
| estado |
Função atual de recuperação de desastres deste site |
Corda |
ativo Espera |
Necessário Uma corda vazia não é permitida. |
| ação |
Ação que o cão de guarda de recuperação de desastres deve realizar |
Corda |
beActive— Mude o papel para ativo. beStandby— Mudar o papel para ficar de prontidão. nada — Não mude de papel. esperar — Aguarde na função atual o tempo especificado na propriedade payload.waitTime. |
Necessário Uma corda vazia não é permitida. |
| descrição |
Descrição do campo de ação e da mensagem enviada na notificação por e-mail |
Corda |
– |
Necessário Uma corda vazia é permitida. |
| payload.waitTime |
Fim do período de carência, quando ambos os sites ficam de prontidão |
String (Data) |
YYYY-MM-DD, hora da UTC no formato HH:MM+00:00 |
Necessário Uma corda vazia é permitida. Esta propriedade é usada quando você especifica o valor da ação conforme espera. |
| payload.details |
Informações personalizadas do usuário que podem ser usadas para depurar o script |
– |
Objeto JSON |
Opcional Uma corda vazia não é permitida. |
Etapas para configurar a recuperação de desastres
Para configurar a recuperação de desastres entre um site ativo e um site de espera:
-
Interrompa o processo de recuperação de desastres configurado durante os lançamentos anteriores antes de atualizar para o Junos Space Network Management Platform Release 15.2R1. Para obter mais informações sobre o processo de atualização, consulte a seção Instruções de atualização na plataforma de gerenciamento Junos Space Network Management Notes 15.2R1.
Para obter mais informações sobre como parar o processo de recuperação de desastres configurado durante os lançamentos anteriores, veja Stop the Disaster Recovery Process na Junos Space Network Management Platform Release 14.1R3 e Anterior.
Você não precisa realizar esta etapa para uma instalação limpa do Junos Space Network Management Platform Release 15.2R1.
-
Configure servidores SMTP em ambos os locais a partir da interface de usuário do Junos Space para receber notificações. Para obter mais informações, veja o gerenciamento de servidores SMTP no Guia de usuário da Junos Space Network Management Platform Workspaces.
-
Copie o arquivo com a lista de dispositivos árbitros (se você estiver usando o algoritmo de arbitragem do dispositivo) ou o script personalizado de detecção de falhas para o local apropriado no local ativo. Garanta que todos os dispositivos árbitros sejam descobertos no local ativo. Para obter mais informações, veja a visão geral dos perfis de descoberta de dispositivos no Guia de usuário da Junos Space Network Management Platform Workspaces.
-
Configure o arquivo de configuração de recuperação de desastres no site ativo. A configuração de recuperação de desastres inclui configurações de SCP para sincronizar a configuração e arquivos RRD, configurações de pulsação, configurações de notificações e o mecanismo de detecção de falhas.
-
Configure o arquivo de configuração de recuperação de desastres no site de espera. A configuração de recuperação de desastres inclui configurações de SCP para sincronizar a configuração e arquivos RRD, configurações de pulsação e configurações de notificação.
-
Inicie o processo de recuperação de desastres a partir do local ativo.
Para obter mais informações, veja Configurando o processo de recuperação de desastres entre um site ativo e de espera.
Comandos de recuperação de desastres
Você usa os comandos de recuperação de desastres listados na Tabela 3 para configurar e gerenciar locais de recuperação de desastres. Você deve executar esses comandos no nó VIP do site. Você pode usar a opção --help com esses comandos para visualizar mais informações.
| Comando |
Descrição |
Opções |
|---|---|---|
|
|
Inicialize os arquivos de configuração de recuperação de desastres em ambos os locais. Você precisa inserir valores para os parâmetros solicitados pelo comando. Crie usuários e senhas MySQL e PgSQL necessários para replicar dados e monitorar a replicação em locais de recuperação de desastres. Os seguintes usuários são criados:
|
|
|
|
||
|
|
Inicie o processo de recuperação de desastres em ambos os locais. Você deve executar este comando no nó VIP do site ativo. O site ativo estabelece uma conexão SSH com o local de espera e executa o Quando você executa este comando, o banco de dados MySQL e a replicação e configuração do banco de dados PgSQL e o backup de arquivos RRD no site de espera são iniciados. Você executa este comando:
|
|
|
|
||
|
|
Quando o comando é executado sem opções, o comando:
Você deve executar o comando na seguinte ordem:
Você deve executar este comando no nó VIP do site local para modificar a configuração e o nó VIP do site remoto para aceitar a configuração modificada. |
Use essas opções para modificar a configuração de recuperação de desastres em um site e atualizar a mudança no site peer: |
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
Verifique a situação do processo de recuperação de desastres. O comando verifica se os bancos de dados MySQL e PgSQL são replicados e a configuração e os arquivos RRD são backup, e verifica o status do cão de guarda de recuperação de desastres e relata erros. |
– |
|
|
Impeça o processo de recuperação de desastres entre os locais. Quando você executa este comando, a replicação e configuração do banco de dados MySQL e PgSQL e o backup de arquivos RRD entre sites são interrompidos. Os arquivos de dados de recuperação de desastres não são excluídos. O status de serviços como JBoss, OpenNMS, Apache permanece inalterado. |
– |
|
|
Interrompa o processo de recuperação de desastres e exclua os arquivos de dados de recuperação de desastres de um site. O site inicia serviços como um cluster independente. Você deve executar este comando no nó VIP de ambos os sites para interromper completamente o processo de recuperação de desastres e excluir os arquivos de dados de recuperação de desastres de ambos os sites. |
– |
|
|
Falha manualmente no site de espera. Quando você executa este comando, o site de espera se torna o novo site ativo e o site ativo se torna o novo site de espera. |
|
|
|
||
|
|
Habilite o failover automático para o site de espera ou desabile o failover automático no site de espera por uma duração especificada.
Nota:
Você só pode executar esse comando se o cão de guarda de recuperação de desastres estiver ativo no local. |
|
|
|
||
|
|
Veja a configuração de recuperação de desastres e as informações de tempo de execução no formato JSON. |
|
|
Quando você inclui este comando em um script personalizado de detecção de falhas, o comando busca a configuração de recuperação de desastres e o status dos serviços de cão de guarda de recuperação de desastres e executa a lógica no script. |