O que são sondas
As sondas são a unidade básica de abstração na análise baseada em intenção. Geralmente, uma determinada sonda consome algum conjunto de dados da rede, faz várias agregações e cálculos sucessivos nela e, opcionalmente, especifica algumas condições dessas agregações e cálculos nos quais as anomalias são levantadas.
As sondas são gráficos acíclicos direcionados (DAGs) em que os nós do gráfico são processadores e estágios. Os estágios são dados, associados ao contexto, que podem ser inspecionados pelo operador. Processadores são conjuntos de operações que produzem e reduzem dados de saída a partir de dados de entrada. A entrada para os processadores são de um ou muitos estágios, e a saída dos processadores também é de um ou muitos estágios. A direcionalidade das bordas em um DAG de sonda representa esse fluxo de entrada para saída.
É importante ressaltar que os processadores iniciais em uma sonda são especiais e não possuem nenhum estágio de entrada. Eles são teoricamente geradores de dados. Vamos nos referir a eles como processadores de origem.
O IBA funciona ingerindo telemetria bruta de coletores em sondas para extrair conhecimento (ex: anomalias, agregações e assim por diante). Um determinado coletor publica a telemetria como uma coleção de métricas, em que cada métrica tem identidade (ou seja, conjunto de pares de chave-valor) e um valor. As sondas IBA, geralmente com o uso de consultas gráficas, devem especificar totalmente a identidade de uma métrica para ingerir seu valor na sonda. Com esse recurso, os probes podem ingerir métricas com especificação parcial de identidade usando filtros de ingestão, permitindo assim a ingestão de métricas com identidades desconhecidas.
Algumas sondas são criadas automaticamente. Esses testes não serão excluídos automaticamente. Isso mantém as coisas simples operacionalmente e em termos de implementação.
Processadores
Os processadores de entrada de uma sonda lidam com a configuração necessária para ingerir a telemetria bruta na sonda para iniciar o pipeline de processamento de dados. Para esses processadores, o número de itens de saída do estágio (um ou muitos) é igual ao número de resultados na(s) consulta(s) de grafo especificada(s). Se várias consultas de grafo forem especificadas, por exemplo. graph_query: [A, B]e a consulta A corresponder a 5 nós e a consulta B corresponder a 10 nós, os resultados da consulta A poderão ser acessados usando query_result índices de 0 a 4 e os resultados da consulta B usando índices de 5 a 14.
Se o tipo de entrada e/ou o tipo de saída de um processador não for especificado, o processador pegará uma única entrada chamada e produzirá uma única saída chamada.
Alguns campos do processador são chamados de expressões. Em alguns casos, elas são consultas de gráficos e são assim anotadas. Em outros casos, são expressões Python que produzem um valor. Por exemplo, no processador Accumulate, a duração pode ser especificada como inteiro com segundos, por exemplo 900, , ou como uma expressão, por exemplo 60 * 15. No entanto, as expressões podem ser mais úteis: há várias maneiras de parametrizá-las.
As expressões dão suporte a valores de cadeia de caracteres. Os parâmetros de configuração do processador que são cadeias de caracteres e expressões de suporte devem usar aspas especiais ao especificar o valor estático. Por exemplo, state: "up" não é válido porque se refere à variável "up", não a uma string estática, então deveria ser: state: '"up"'.
Uma expressão está sempre associada a uma consulta de grafo e é executada para cada correspondência resultante dessa consulta. O contexto de execução da expressão é tal que cada variável especificada na consulta é resolvida para um nó nomeado no resultado da correspondência associado. Para obter mais informações, consulte Exemplo de coletor de serviço .
Os processadores baseados em grafo foram estendidos com o query_tag_filter, que permite filtrar os resultados da consulta de grafo por marcas. Nas sondas IBA, as tags são usadas apenas como critérios de filtro para servidores e roteadores externos, especificamente para a sonda ECMP Imbalance (Interfaces Externas) e a sonda Total East/West Traffic. Para obter informações específicas sobre o processador, consulte Processadores de sondagem na seção Referências.
Filtros de ingestão
Com "filtros de ingestão", um resultado de consulta pode ingerir várias métricas em uma sondagem. Os tipos de dados de tabela são usados para armazenar várias métricas como parte de um único item de saída de estágio. Os tipos de dados de tabela incluem table_ns, table_dss, table_ts - para corresponder aos tipos existentes - ns, dss, ts -respectivamente.
Filtro de coleção IBA
Os filtros de coleta determinam as métricas coletadas dos dispositivos de destino.
Um filtro de coleta para um determinado coletor em um determinado dispositivo é simplesmente uma coleção de filtros de ingestão presentes em diferentes sondas. Você também pode especificá-lo como parte da ativação de um serviço fora do contexto de IBA ou testes, mas as regras de precedência existentes para ativação de serviços se aplicam aqui - somente os filtros em um determinado nível de precedência são agregados. Quando várias investigações especificam um filtro de ingestão direcionado a um serviço específico em um dispositivo específico, as métricas coletadas são uma união, ou seja, uma métrica é publicada quando corresponde a qualquer um dos filtros. É por isso que os dados também são filtrados pelo componente controlador antes de serem assimilados nas sondas IBA.
Esse filtro é avaliado por coletores de telemetria, geralmente para controlar melhor até mesmo qual subconjunto de métricas disponíveis é buscado do sistema operacional do dispositivo subjacente (por exemplo, para buscar apenas um subconjunto de rotas em vez de obter todas as rotas, o que pode ser um número enorme). De qualquer forma, somente as métricas que correspondem ao filtro de coleção são publicadas como a telemetria bruta.
Como parte da habilitação de um serviço em um dispositivo, agora você pode especificar filtros de coleção para serviços. Esse filtro se torna uma entrada adicional fornecida aos coletores como parte de "self.service_config.collection_filters".
Formato de filtro IBA
A seguir estão as metas de design/usabilidade para filtros (ingestão e coleta)
- Facilidade de criação - desde que os autores da sondagem sejam os que a especificam
- Na maioria das vezes, os casos são corresponder a qualquer, corresponder a uma determinada lista de valores possíveis, correspondência de igualdade, verificar se a chave tem valores numéricos.
- Avaliação eficiente - dado que os filtros são avaliados nos caminhos quentes de coleta ou ingestão.
- Agregável - vários filtros são agregados para que essa lógica de agregação não precise se tornar responsabilidade de coletores individuais.
- Linguagem de programação neutra – os componentes que operam em filtros podem estar em Python ou C++ ou em alguma outra linguagem no futuro.
- Programável - ser passível de programabilidade futura em torno dos filtros, pelo próprio controlador e/ou coletores, para melhorar coisas como usabilidade, desempenho e assim por diante.
Considerando os objetivos acima, segue-se um esquema sugerido e ilustrativo para filtro1. Consulte as seções de filtro de ingestão para obter exemplos específicos para entender isso melhor.
FILTER_SCHEMA = s.Dict(s.Object(
'type': s.Enum(['any', 'equals', 'list', 'pattern', 'range', 'prefix']),
'value': s.OneOf({
'equals': s.OneOf([s.String(), s.Integer()]),
'list': s.List(s.String(), validate=s.Length(min=1)),
'pattern': s.List(s.String(), validate=s.Length(min=1)),
'range': s.AnomalyRange(), validate=s.Length(min=1),
'prefix': s.Object({
'prefixsubnet': s.Ipv6orIpv4NetworkAddress(),
'ge_mask': s.Optional(s.Integer()),
'le_mask': s.Optional(s.Integer()),
'eq_mask': s.Optional(s.Integer())
})
), key_type=s.String(description=
'Name of the key in metric identity. Missing metric identity keys are '
'assumed to match any value'))
Uma instância da especificação de filtro é interpretada como AND de todas as chaves especificadas (também conhecidas como restrições por chave). Várias especificações de filtro provenientes de várias sondas são consideradas OR no nível do filtro.
O esquema apresentado aqui é apenas para comunicar os requisitos. Você pode escolher qualquer maneira que cumpra os casos de uso indicados.
Os processadores coletores additional_properties especificados na configuração dos processadores coletores podem ser acessados usando o namespace especial context. . Por exemplo, se um coletor definir a propriedade system_role, ele poderá ser usado desta maneira:
duration: 60 * (15 if context.system_role == "leaf" else 10)
O contexto de itens está disponível desde que o conjunto de itens não seja alterado em relação ao conjunto original derivado da configuração do processador coletor. Depois que os dados passam por um processador que altera esse conjunto, eles não estão mais disponíveis (por exemplo, qualquer processador de agrupamento).
No blueprint, navegue até Análise > sondas para ir para a exibição de tabela de sondas. Você pode instanciar, criar, clonar, editar, excluir, importar e exportar sondas.
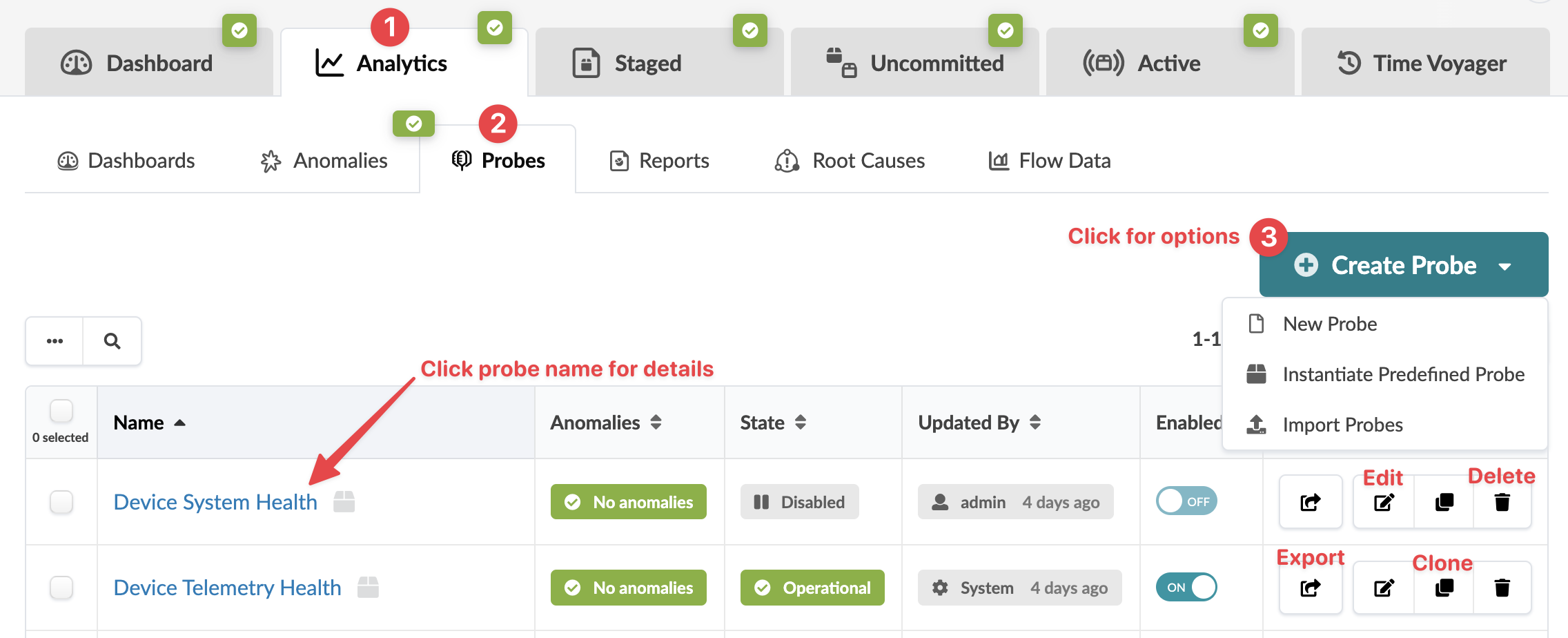
Para acessar os detalhes de uma sonda, clique em seu nome. Você pode ativar/desativar um teste na exibição de tabela ou na exibição de detalhes. Você pode exibir estágios em alguns testes de várias maneiras. Por exemplo, ao clicar na sonda chamada Integridade do Sistema do Dispositivo, você verá a imagem abaixo. Você pode selecionar a fonte de dados (tempo real, séries temporais, avisos de serviço de telemetria) e agregar dados de várias maneiras. Além disso, você pode ver o espaço em disco usado em cada sonda, conforme aplicável.
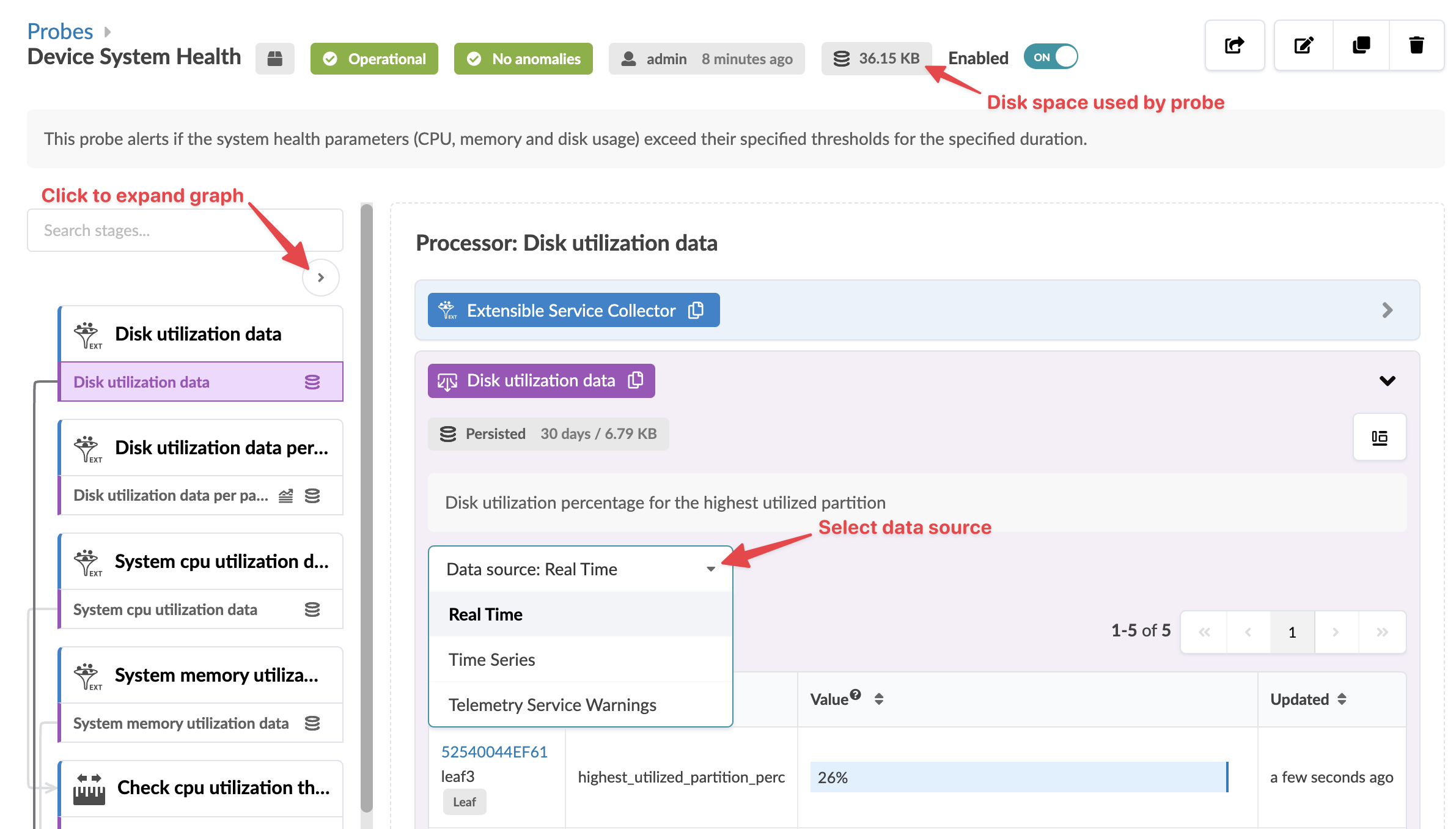
Se o controlador Apstra não tiver espaço em disco suficiente, os arquivos de dados de telemetria mais antigos serão excluídos. Para reter dados de telemetria mais antigos, você pode aumentar a capacidade com os clusters de VM do Apstra.
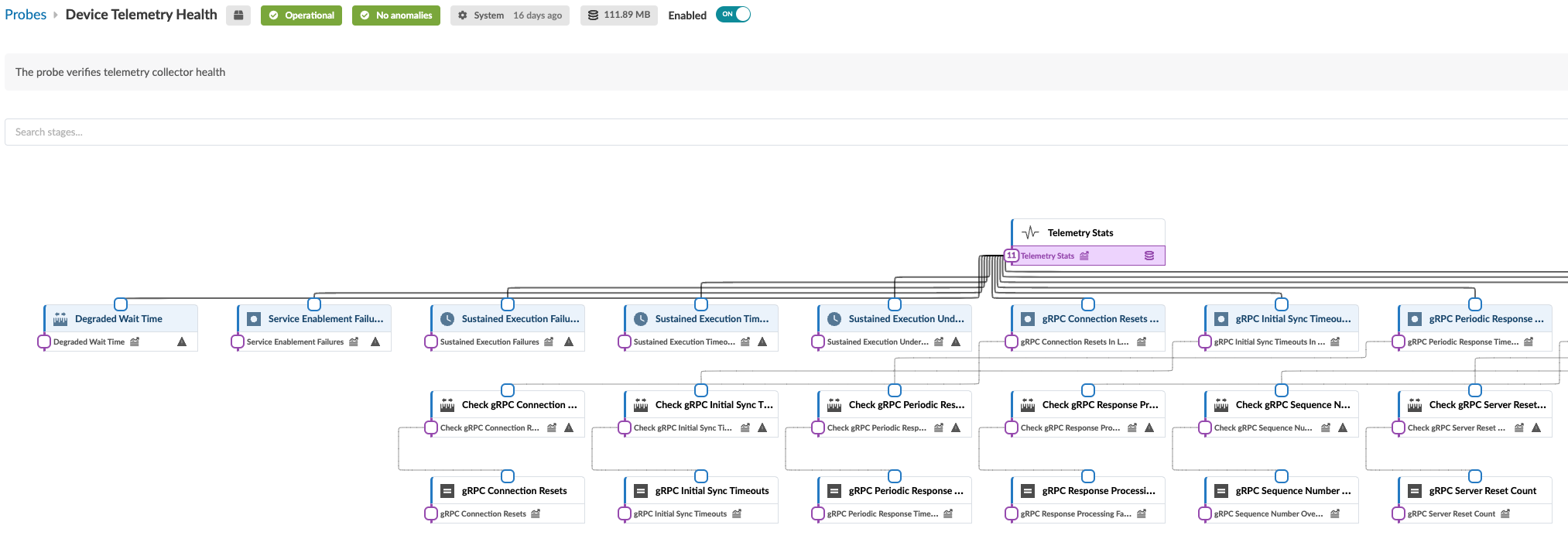
A estrutura e a lógica de sondas não lineares com dezenas de processadores não são facilmente distinguidas na visualização padrão. Você pode clicar no botão de expansão (parte superior do painel esquerdo) para ver uma representação expandida de como os processadores estão inter-relacionados. Por exemplo, a imagem abaixo mostra parte da exibição expandida da investigação de integridade de telemetria do dispositivo .