Visão geral da arquitetura de software
O Juniper Apstra tem os dois componentes principais a seguir em sua arquitetura de sistema:
-
Servidor Apstra
-
Agentes de dispositivo do Apstra
Cada dispositivo gerenciado pelo Apstra exigirá um agente Apstra instalado nele. O servidor Apstra e todos os agentes do Apstra atuam como um sistema operacional distribuído.
A conectividade TCP é o único requisito entre os nós.
O Apstra traduz requisitos de negócios de alto nível, chamados de "intenção", e os traduz em um ambiente de rede de data center totalmente operacional.
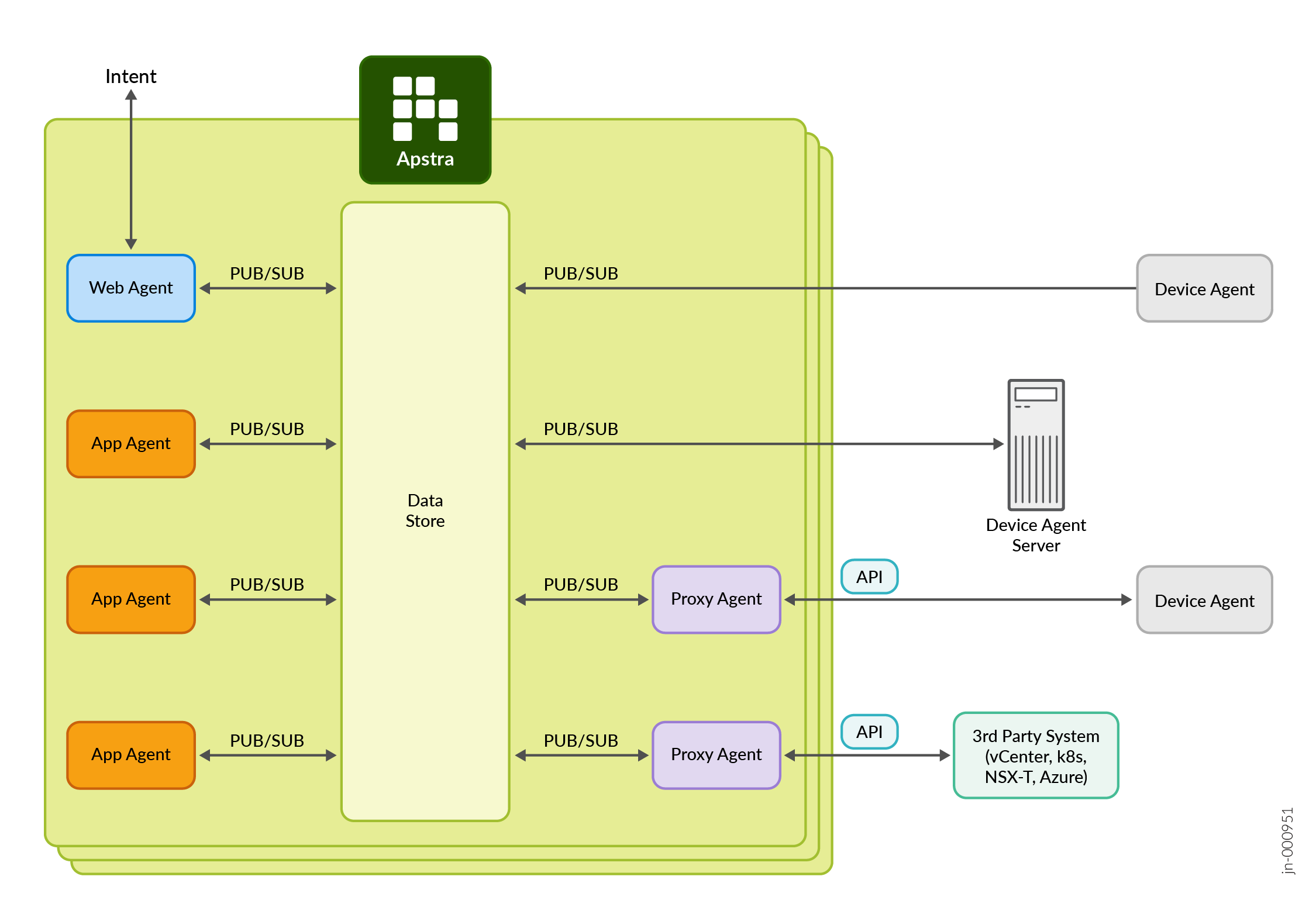
A arquitetura do Juniper Apstra é baseada em uma infraestrutura de gerenciamento de estado distribuída, que pode ser descrita como uma malha de comunicação centrada em dados com armazenamento de dados na memória escalável horizontalmente e tolerante a falhas. Todas as funcionalidades do aplicativo de design de referência específico são implementadas por meio de um conjunto de agentes sem estado. Os agentes se comunicam entre si por meio de um canal de comunicação lógico baseado em publicação e assinatura e, essencialmente, implementam a lógica do aplicativo.
Cada aplicativo de design de referência do Apstra é simplesmente uma coleção de agentes stateless descritos acima. Em termos gerais, existem três classes de agentes no Apstra:
- Os agentes de interação (web) são responsáveis por interagir com os usuários, ou seja, receber informações do usuário e alimentar os usuários com contexto relevante do armazenamento de dados.
- Os agentes de aplicativo são responsáveis por executar transformações de dados específicas do domínio do aplicativo, assinando entidades de entrada e produzindo entidades de saída.
- Os agentes de dispositivo residem em (ou são proxies) em um sistema físico ou virtual gerenciado, como um switch, servidor, firewall, balanceador de carga ou até mesmo controlador, e são usados para escrever configurações e coletar telemetria usando interfaces nativas (específicas do dispositivo), geralmente APIs do fornecedor.
Essa interação pode ser ilustrada com um exemplo que descreve uma parte do aplicativo de design de referência de rede de data center do Apstra.
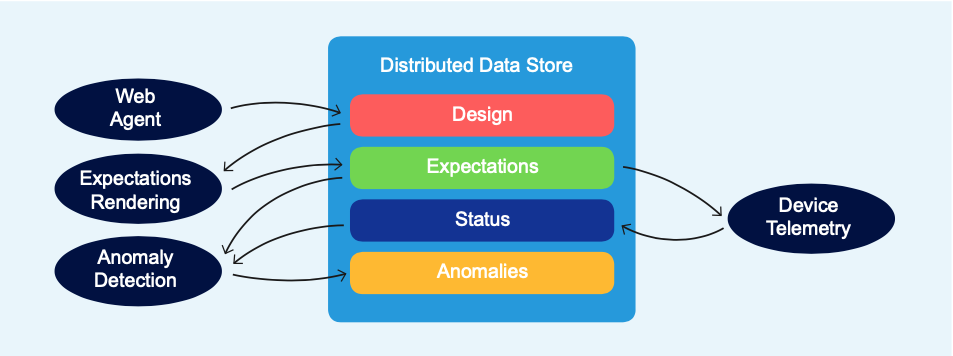
O agente da Web recebe a entrada do usuário — neste caso, um design para uma malha Clos L3 que contém o número de spines, leafs e links entre eles e os pools de recursos a serem usados para IPs de malha e números ASN. O agente da Web publica essa intenção no armazenamento de dados como um conjunto de nós e relacionamentos de grafo e suas respectivas propriedades.
O agente de build assina essa intenção e:
- Realiza validações de correção e integridade
- Aloca recursos de pools de recursos
Supondo que as validações sejam aprovadas, o agente de build publica essa intenção junto com as alocações de recursos no armazenamento de dados.
O agente de renderização de configuração assina a saída do agente de compilação. Para cada nó, o agente de configuração busca os dados relevantes, incluindo recursos, e os mescla com modelos de configuração.
O agente de expectativas também assina a saída do agente de compilação e gera expectativas que precisam ser atendidas para validar o resultado.
O agente de telemetria do dispositivo assina a saída do agente de expectativas e começa a coletar a telemetria relevante. As sondas IBA processam a telemetria bruta e a comparam com as expectativas e publicam anomalias.
O agente de identificação de causas-raiz (RCI) analisa as anomalias e as classifica em sintomas, impactos e causas-raiz identificadas.
Os agentes se comunicam por meio de interfaces baseadas em atributos (daí o termo centrado em dados) publicando entidades e assinando alterações nas entidades. O foco em dados também implica que a definição de dados faz parte da estrutura e é implementada definindo as entidades, em oposição aos sistemas baseados em mensagens, por exemplo.
O sistema de publicação-assinatura centrado em dados não sofre com os problemas dos sistemas baseados em mensagens. Em um sistema baseado em mensagens, mais cedo ou mais tarde o número de mensagens excede a capacidade do sistema de armazená-las ou consumi-las; Lidar com isso é difícil, pois é preciso repetir o histórico de mensagens para chegar a um estado consistente. O sistema centrado em dados é resiliente a surtos de mudanças de estado, pois é fundamentalmente dependente apenas do último estado. Esse estado captura o contexto importante e abstrai todas as sequências de eventos possíveis (e irrelevantes) que levam a ele.
Os problemas difíceis (por exemplo, elasticidade, tolerância a falhas) são resolvidos uma vez e em nome de todos os agentes. A arquitetura típica consiste em vários agentes sem estado que podem ser reiniciados em caso de falha e continuar de onde pararam simplesmente relendo o estado em que se inscrevem no banco de dados.